czy kiedy chce zawartość tablicy zwiększyć o 1.
to czy przypisanie do każdej zmiennej po prostu ręcznie będzie szybsze niż w pętli ?
bo nie trzeba sprawdzać warunku żeby przerwać pętlę ?
wydaje mi się że jest to kompromis pomiędzy mniejszą ilością obliczeń a zarezerwowaną pamięcią na instrukcjie.
0
7
Pytasz o mikro optymalizację. Przy takich pytaniach warto podać język, rodzaj struktury (jest n rodzajów tablic) i przykładowy kod.
Nie ma na to odpowiedzi uniwersalnej pasującej do każdego języka.
3
Takimi rzeczami zajmuje się kompilator/interpreter.
0
int t[4];
for(int i=0i<4;i++){
t[i]++;
}
czy
t[0]++;t[1]++;t[2]++;t[3]++;
3
Tak naprawdę to bez znaczenia, jeśli chodzi o szybkość. A jeśli chodzi o czytelność to 1.
2
Nic ci to nie da. Na x86, Wykonanie instrukcji loop to czas nieporównywalnie mały z 2 instrukcjami mov pamięć-rejestr (i odwrotnie). Poza tym, w dzisiejszych czasach, kompilator ci to zoptymalizuje. Jak się uczysz programować, to już w ogóle zmykaj na jakiś nowoczesny język programowania. :)
0
nie rozumiem jak nic nie da. pierwszy przykład . pętla for może się nie wykonać ani razu bo jest sprawdzany warunek a on nie pochłania 0 czasu procesora. bez for tego nie było by warunku.
0
kamil kowalski napisał(a):
nie rozumiem jak nic nie da. pierwszy przykład . pętla for może się nie wykonać ani razu bo jest sprawdzany warunek a on nie pochłania 0 czasu procesora. bez for tego nie było by warunku.
No to zobacz co ci wygeneruje kompilator i porównaj obydwa rozwiązania - ile taktów procesora potrzeb do wykonania tej instrukcji. Zobacz jakie zegary mają aktualnie procesory i czy ma to sens?
0
// Type your code here, or load an example.
void square(int num) {
int t[4];
t[0]++;
t[1]++;
t[2]++;
t[3]++;
}
square(int):
push rbp
mov rbp, rsp
mov DWORD PTR [rbp-20], edi
mov eax, DWORD PTR [rbp-16]
add eax, 1
mov DWORD PTR [rbp-16], eax
mov eax, DWORD PTR [rbp-12]
add eax, 1
mov DWORD PTR [rbp-12], eax
mov eax, DWORD PTR [rbp-8]
add eax, 1
mov DWORD PTR [rbp-8], eax
mov eax, DWORD PTR [rbp-4]
add eax, 1
mov DWORD PTR [rbp-4], eax
nop
pop rbp
ret
// Type your code here, or load an example.
void square(int num) {
int t[4];
for(int i=0;i<4;i++){
t[i]++;
}
}
square(int):
push rbp
mov rbp, rsp
mov DWORD PTR [rbp-36], edi
mov DWORD PTR [rbp-4], 0
jmp .L2
.L3:
mov eax, DWORD PTR [rbp-4]
cdqe
mov eax, DWORD PTR [rbp-32+rax4]
lea edx, [rax+1]
mov eax, DWORD PTR [rbp-4]
cdqe
mov DWORD PTR [rbp-32+rax4], edx
add DWORD PTR [rbp-4], 1
.L2:
cmp DWORD PTR [rbp-4], 3
jle .L3
nop
nop
pop rbp
ret
2
Dla krótkich pętli kompilatory potrafią same rozwijać pętle. GCC ma nawet specjalną opcje -funroll_loops do tego.
3
Jeśli to C/C++ to lepiej to zostaw kompilatorowi.
Jeśli naprawdę chcesz to optymalizować ręcznie to raczej musisz mieć ustalony rozmiar tablicy (stały).
I tablica musi być wielkości setek lub tysięcy elementów.
Kilka rozwiązań:
- SIMD intrisinc: https://stackoverflow.com/a/41087832
- openmp:
#pragma omp simd - intel: #pragma vector always
0
W dzisiejszym czasach dobrą drogą jest korzystać z tego co udostępnia język. np. iteratorów i tutaj map.
Coraz częściej w kompilatorach zawarte są optymalizacje dotyczących właśnie takich operacji związanych z wektorami. Stosowana jest architektura SIMD https://en.wikipedia.org/wiki/SIMD
Warto poznać co dany język oferuje w tym temacie, bo sporo obliczeń zaczyna być wykonywanych na wektorach.
Z tego co pamiętam w Rust jest to już optymalizowane. w którejś Javie już jest lub będzie i zapewne w innych językach też.
0
W przypadku pętli - zależnie od kompilatora i sytuacji zysk może być albo zerowy, albo pomijalnie mały. W przypadku iteratorów może to mieć znaczenie ma.
Natomiast jeśli nie jest to problem czysto teoretyczny, a informacja, która według ciebie przyda ci się w rzeczywistości - to źle szukasz.
0
@kamil kowalski:
testujesz wydajność https://en.wikipedia.org/wiki/Dead_code
kamil kowalski napisał(a):
// Type your code here, or load an example.
void square(int num) {
int t[4];
t[0]++;
t[1]++;
t[2]++;
t[3]++;
}square(int):
push rbp
mov rbp, rsp
mov DWORD PTR [rbp-20], edi
mov eax, DWORD PTR [rbp-16]
(...)
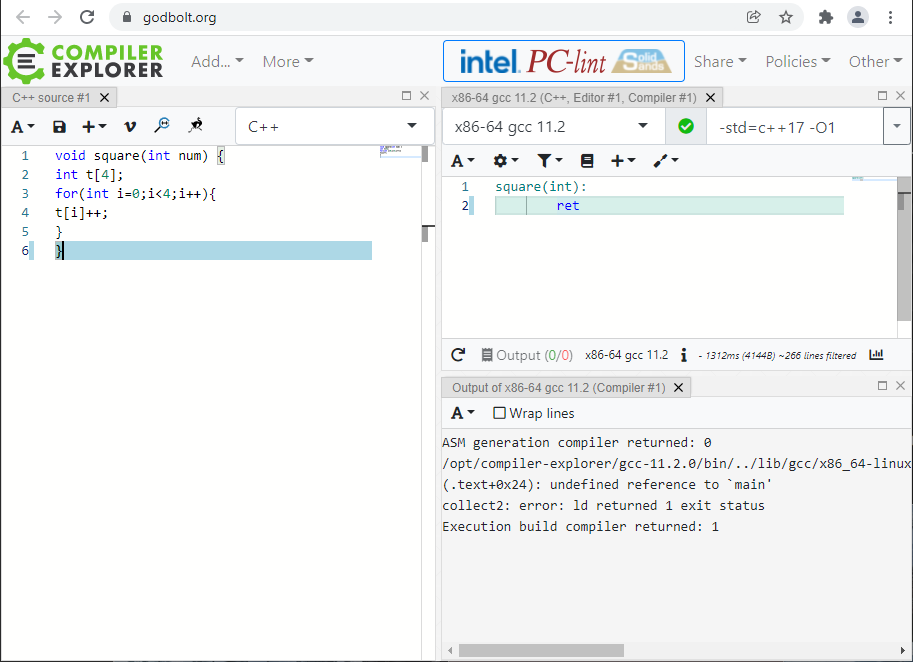
weź włącz jakiekolwiek optymalizacje
z flagą -O1 (najprostsze optymalizacje):
void square(int num) {
int t[4];
t[0]++;
t[1]++;
t[2]++;
t[3]++;
}
daje po kompilacji
square(int):
ret
a
void square(int num) {
int t[4];
for(int i=0;i<4;i++){
t[i]++;
}
}
daje po kompilacji
square(int):
ret
nawet kompilować nie potrafisz
aktualizacja:
tak się włącza podstawowe optymalizacje (-O1), ale tryb release to -O2 albo -O3 (albo może i więcej, np: -Ofast albo jakieś dodatkowe flagi)
0
Robert Karpiński napisał(a):
Warto poznać co dany język oferuje w tym temacie, bo sporo obliczeń zaczyna być wykonywanych na wektorach.
Z tego co pamiętam w Rust jest to już optymalizowane. w którejś Javie już jest lub będzie i zapewne w innych językach też.
W zasadzie wszystkie popularne języki kompilowane (zarówno AOT jak i JIT) mają autowektoryzację, czyli taki implicit SIMD. Oprócz tego jest explicit SIMD, czyli np. compiler intrinsics (np. w C++, C#, Ruście, itd) albo jakieś specjalne API do jawnego SIMDa (np. Vector API z https://openjdk.java.net/projects/panama/ albo nieco bardziej niskopoziomowe SIMD API dla innych języków, np. C++ https://github.com/vectorclass , Rust https://github.com/rust-lang/portable-simd , itp itd)
Żeby zyskać na SIMDach to najpierw trzeba ogarnąć podstawowe mechanizmy optymalizacyjne kompilatora i procesora. Inaczej to błądzenie po omacku i setki egzystencjalnych pytań, których można by uniknąć pochylając się nad podstawami.
0
zrobiłem przykład bez martwego kodu.
bez pętli:
void quad_inc(int * t) {
t[0]++;
t[1]++;
t[2]++;
t[3]++;
}
po kompilacji z -O2
quad_inc(int*):
add DWORD PTR [rdi], 1
add DWORD PTR [rdi+4], 1
add DWORD PTR [rdi+8], 1
add DWORD PTR [rdi+12], 1
ret
po kompilacji z -O3
quad_inc(int*):
movdqu xmm0, XMMWORD PTR [rdi]
paddd xmm0, XMMWORD PTR .LC0[rip]
movups XMMWORD PTR [rdi], xmm0
ret
.LC0:
.long 1
.long 1
.long 1
.long 1
z pętlą:
void quad_inc(int * t) {
for(int i=0;i<4;i++){
t[i]++;
}
}
po kompilacji z -O2
quad_inc(int*):
lea rax, [rdi+16]
.L2:
add DWORD PTR [rdi], 1
add rdi, 4
cmp rdi, rax
jne .L2
ret
po kompilacji z -O3
quad_inc(int*):
movdqu xmm0, XMMWORD PTR [rdi]
paddd xmm0, XMMWORD PTR .LC0[rip]
movups XMMWORD PTR [rdi], xmm0
ret
.LC0:
.long 1
.long 1
.long 1
.long 1
przy użyciu -O3 oba kody wejściowe (z pętlą i bez) dają identyczne kody wynikowe.
0
bo jest sprawdzany warunek a on nie pochłania 0 czasu procesora.
no ok, ale czy tutaj nie wpadnie branch prediction i ugra na wydajności?
1
WeiXiao napisał(a):
bo jest sprawdzany warunek a on nie pochłania 0 czasu procesora.
no ok, ale czy tutaj nie wpadnie branch prediction i ugra na wydajności?
niby ugra, ale i tak przykładowe kody w tym wątku są tak prostackie, że nie ma sensu wyciągać z nich daleko idących wniosków
na nowoczesnym procesorze ta pętelka będzie prawdopodobnie tylko ciut wolniejsza od 4-ech instrukcji mov, ale to niewiele dowodzi
dla laika, najlepszym sposobem na oszacowanie wydajności jest odpalenie kodu w specjalnych środowiskach testowych do mikrobenchmarków:
- dla javy to https://openjdk.java.net/projects/code-tools/jmh/
- dla c++ to nie wiem jaki jest najlepszy czy najczęściej używany, ale znalazłem np. https://github.com/google/benchmark