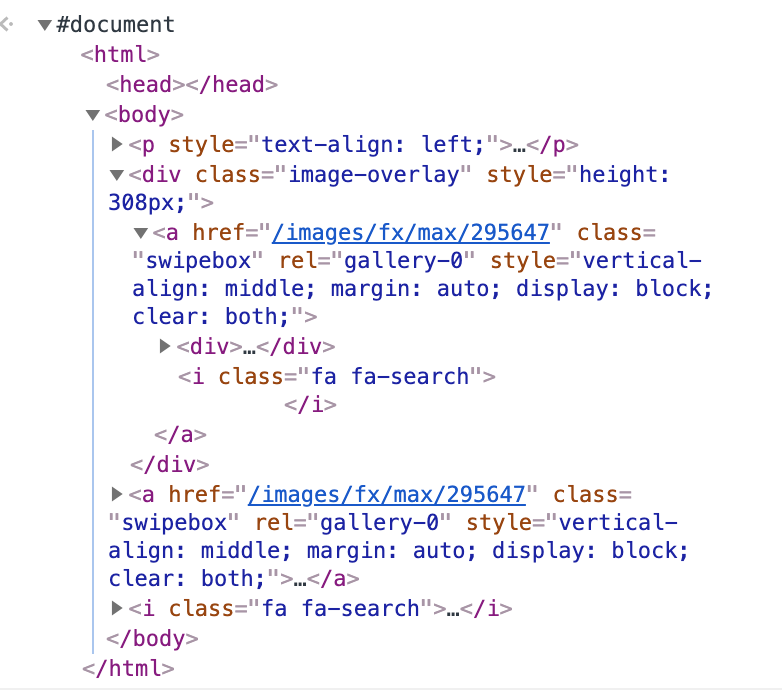
Używam takiego kodu do tworzenia elementów DOM na podstawie stringa:
function getDOMElementFromString(s) {
let element = new DOMParser().parseFromString(s, 'text/html');
return element.body.firstChild;
}
Na wejściu podaję:
<p style="text-align: left;">
<a href="/images/fx/max/295647" class="swipebox" rel="gallery-0" style="vertical-align: middle; margin: auto; display: block; clear: both;">
<img class="internal-image aligncenter" style="vertical-align: middle; margin: auto; display: block;" title="Split payment - przebieg zapłaty" src="/images/fx/max,590,0/295647" alt="Split payment - na czym polega?" data-image-id="274609">
<div class="image-overlay" style="height: 308px;">
<div>
<i class="fa fa-search"/>
</div>
</div>
</a>
</p>
Ale niestety jako element otrzymuję:
<p style="text-align: left;">
<a href="/images/fx/max/295647" class="swipebox" rel="gallery-0" style="vertical-align: middle; margin: auto; display: block; clear: both;">
<img class="internal-image aligncenter" style="vertical-align: middle; margin: auto; display: block;" title="Split payment - przebieg zapłaty" src="/images/fx/max,590,0/295647" alt="Split payment - na czym polega?" data-image-id="274609">
</a>
</p>
Czyli obcina mi diva pod obrazkiem. Dlaczego? Jak temu zaradzić?