Siemano.
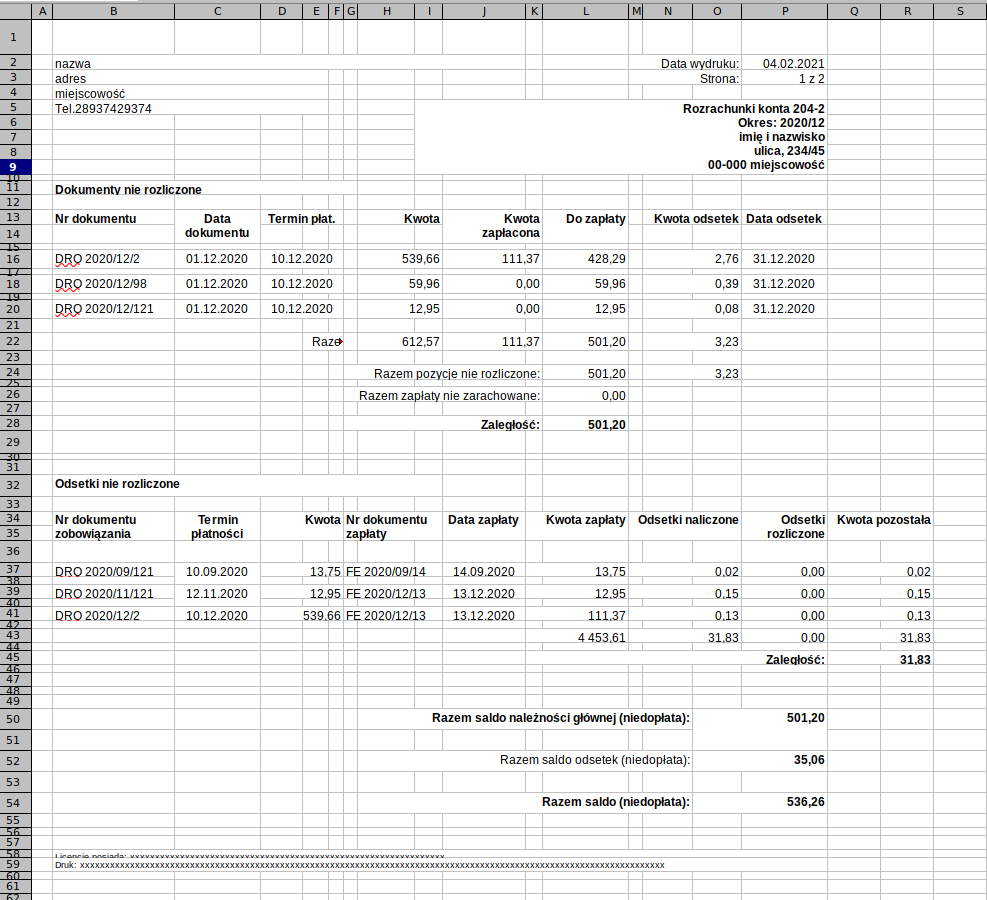
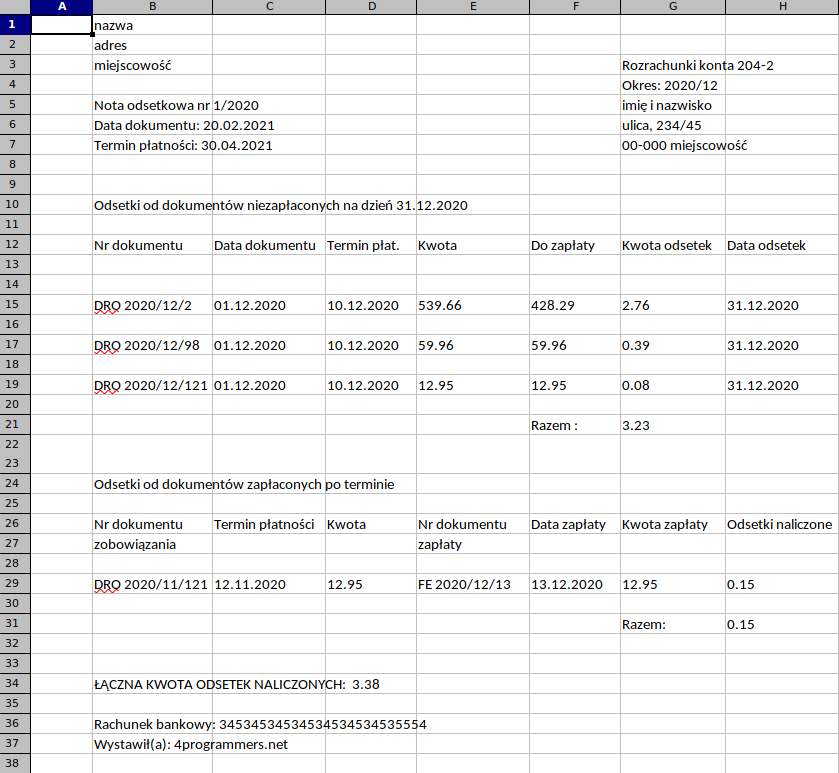
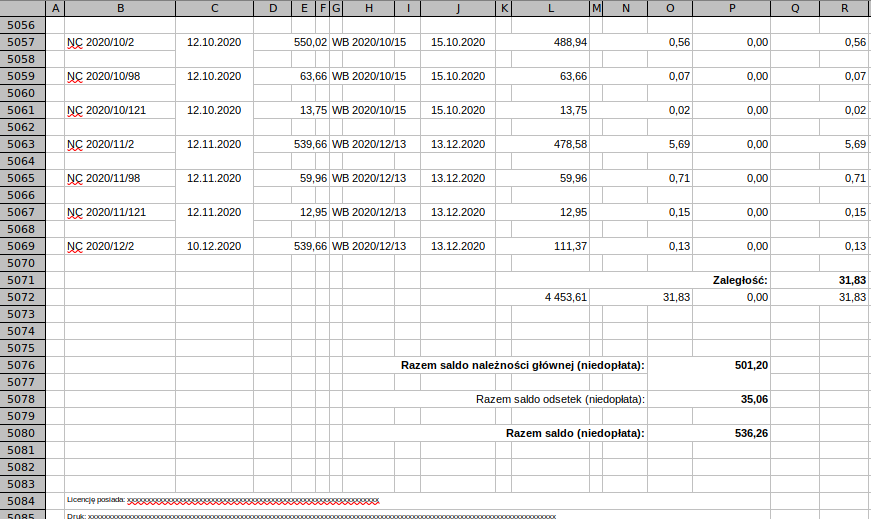
Uczę się pythona od kilku mc dopiero, niecałe pół roku. Zrobiłem sobie jakiś kurs na yt, rozwiązałem testy zadaniowe na Codingbat i i Pythonprinciples. Oraz niezliczona ilość mniejszych materiałów na yt i duckduckgo.com. Pierwszy mój projekt zaczął się od jakiegoś filmiku na yt. Trwał od 4 godziny, Gościu pisał program ale popełniał dużo błędów w sumie to był nawet projekt z jakiegoś wcześniej płatnego kursu. Gościu tam zaczął od python'a3 po 15min miał problem i wrócił do pythona2. Ja leciałem dalej na 3 i w związku z kilkoma różnicami oraz licznymi innymi jego błędami. Napisanie gotowego projektu z tamtego 4h filmiku mi zajęło ponad tydzień ale zrobiłem dużo lepszy efekt końcowy. Program przedstawiony poniżej jest mój, Początkowo miał to był program w którym podaję się nazwę do pliki exela potem podaje się nazwę wyjściową do zapisu i miało to być tyle. Program napisałem dla koleżanki, która pracuje w księgowości. Projekt zacząłem od zera. Czyli wyszukaniu modułu to odrobienia pliku exela. Kod zrobił się pokaźny. Wyszkoliłem sobie dużo informacji które wcześniej zdobyłem. Dokument w exelu jest wygenerowany z innego programu. W który panuje mega burdel, Mój program go porządkuje, W skrócie jest dokument który mieści się na jednej kartce a4. Program jest tylko do jednego typu faktur i docelowego będzie używany, przed dwie księgowe. Tak w sumie to mogą wystąpić trzy różne wersje tego dokumentu. Podzieliłem sobie ten dokument, na jakby trzy części. Górna, środkowa i dolna. W części górnej każdy typ faktur posiada dane w dokładnie tych samych komórkach. Do indexu 14 wszędzie jest to samo. Dla danych z lewej strony, każda linijka się zaimportowała w osobnym indexie, tylko zastąpiłem pustym miejscem interesującą mnie lokalizację. . W kolumnie 8 pierwotnie był zamieszczony w 5 linijkach adres składający się z 98 znaków. Po zapisaniu do nowego dokumentu robił się z tego string, stwierdziłem że najlepiej będzie to rozłączyć na osobny index. pierwsza i druga oraz ostatnia linijka, zawsze mają tyle samo znaków więc to było stosunkowo łatwe to rozdzielenia. Ale już 4 i 5 linijka w każdym dokumencie była inna. Nad adresem były dwie linijki z informacją o Dacie wydruku oraz stronie które zastąpiłem pustym miejscem. Środkowa część jest bardziej skomplikowana, Na sam początek, w dwóch przypadkach dokumenty zastępują index innym wpisem niż ten który jest pierwotnie a jeden zostaje taki jak był. Następnie jest 8 wypełnionych kolumn z tego z zauważyłem to nie ma tam więcej jak max 10 indexów, które się ciągną aż do kolumny 16. Tutaj każdy index jest wypełniony co drugą linię, I tu zaczyna się liczenie pustych miejsc w każdym dokumencie liczenie jest w tym samym miejsc dla każdego dokumentu linia nr 14. Po wyliczeniu indexów, Program po kolei od 14 indexu do indexu wyliczonego dzięki pętli przenosi wszystkie kolumny, Po drodze pomija jedną z nich. Problem był przy kolumnach w których były daty, pandas przekręcił kolejność roku miesiąca i dnia oraz dodał po dacie 0000. Znalazłem na to sposób i udało się to ogarnąć. Pod tymi stosunkowo krótkimi informacjami a następnymi kolumnami poniżej, Niezależnie ile indexów jest zapełnionych to do następnego jest zawsze 14. Także od początku dokumentu do indexu w kolumnie jest 14lini plus następne 14 od końca do następnego i plus wyliczona ilość daje miejsce od którego zaczyna się następne liczenie. I tutaj powtarza się czynność liczenie indexów co drugi aż do momentu kiedy będzie wartość jako pusty dokument == True, Zebrana wartość zostaje dodawana i już mam wartość od którego do którego indexu program ma porządkować kolumny. Na samym dole w odpowiedniej linii pod wartościami zachowany jest ten sam odstęp i dodane dodatkowe informacje wprowadzone przez cmd. W międzyczasie program porównuje z całych dat miesiące i jeśli są one takie same to wywala cała linie plus linie następną z racji że wypełnione są co drugie. To taki mega skrót opisu tego co program oferuje. Program działa i nie potrzebuje żadnych poprawek. Może aż trochę za bardzo nie lubię robienia czegoś na odczep i starałem się go zrobić dosyć porządnie. Jeśli ktoś to przeczyta to moja rzecz. Jako że jestem początkujący i jest to mój pierwszy samodzielny projekt. Fajnie jakby ktoś dał sugestie w jakim kierunku idzie moje programowanie. Czy idę w dobrym kierunku, czy może jednak zwracać uwagę na coś? Program nie posiada klas, ponieważ od początku miał być to mały programik a nabrał rozmachu z czasem i już mi się nie chciało go przerabiać, bo mam inne rzeczy do nauki. Jak już to przeczytałeś to zostaw jakaś opinie:) Pozzdrooo;) po dodaniu kod chyba się trochę rozjechał.
#!/usr/bin/python3
import pandas as pd
import os
import getpass
import time
def zapis():
df.pop('Unnamed: 4')
df.pop('Unnamed: 6')
df.pop('Unnamed: 8')
df.pop('Unnamed: 11')
df.pop('Unnamed: 12')
df.pop('Unnamed: 13')
df.pop('Unnamed: 14')
df.pop('Unnamed: 15')
df.pop('Unnamed: 16')
nazwa = input('Podaj nazwę do zapisania pliku: ')+".xlsx"
print('\n')
zapis = pd.ExcelWriter(nazwa, engine='xlsxwriter' )
df.to_excel(zapis , sheet_name='Sheet1', index=False , header=False)
worksheet = zapis.sheets['Sheet1']
worksheet.set_column("B:B", 16)
worksheet.set_column('C:C', 15)
worksheet.set_column('D:D', 12)
worksheet.set_column('E:E', 15)
worksheet.set_column(5, 5, 12)
worksheet.set_column(6, 6, 14)
worksheet.set_column(7, 7, 15)
zapis.save()
def dok_nie_rozliczne():
global kwota_sumy
global o
global i
nr_dok = df.iloc[14::2 ,1].isnull()
for i , row in enumerate(nr_dok):
if row == True :
break
df.iloc[11,5] = df.iloc[11,7]
df.iloc[11,7] = df.iloc[11,11]
df.iloc[11,9] = df.iloc[11,13]
df.iloc[14+i*2,7] = "Razem :"
df.iloc[14+i*2,9] = str(round(df.iloc[14+i*2,13],2))
tb2 = 14
for tylko_data in df.iloc[14:13+i*2:2,2]:
tylko_data = pd.to_datetime(tylko_data).date()
df.iloc[tb2 , 2] = str(tylko_data.strftime('%d.%m.%Y'))
tb2 += 2
tb3=14
for tylko_data in df.iloc[14:13+i*2:2,3]:
tylko_data = pd.to_datetime(tylko_data).date()
df.iloc[tb3,3] = str(tylko_data.strftime('%d.%m.%Y'))
tb3+=2
tb5=14
for kazdy in df.iloc[14:13+i*2:2,7]:
df.iloc[tb5,5] = str(round(kazdy,2))
tb5+=2
tb7=14
for kazdy in df.iloc[14:13+i*2:2,11]:
df.iloc[tb7,7] = str(round(kazdy,2))
tb7+=2
tb9=14
for kazdy in df.iloc[14:13+i*2:2,13]:
df.iloc[tb9,9] = str(round(kazdy,2))
tb9+=2
tb11 = 14
for tylko_data in df.iloc[14:13+i*2:2,15]:
tylko_data = pd.to_datetime(tylko_data).date()
df.iloc[tb11 , 10] = str(tylko_data.strftime('%d.%m.%Y'))
tb11 += 2
df.iloc[17+i*2,1] = "Odsetki od dokumentów zapłaconych po terminie"
df.iloc[11,10] = 'Data odsetek'
df.iloc[19+i*2,1] = 'Nr dokumentu'
df.iloc[20+i*2,1] = 'zobowiązania'
df.iloc[19+i*2,2:4] = df.iloc[26+i*2,2:4]
df.iloc[19+i*2,5] = 'Nr dokumentu '
df.iloc[20+i*2,5] = "zapłaty"
df.iloc[19+i*2,7] = "Data zapłaty"
df.iloc[19+i*2,9] = "Kwota zapłaty"
df.iloc[19+i*2,10] = "Odsetki naliczone"
drugi = df.iloc[29+i*2::2,1].isnull()
for o , rzad in enumerate(drugi):
if rzad == True :
break
tab1 = 22+i*2
for kazdy in df.iloc[29+i*2:29+i*2+o*2:2,1] :
df.iloc[tab1,1] = str(kazdy)
tab1 += 2
df.iloc[29+i*2:29+i*2+o*2:2,1] = ""
tab2 = 22+i*2
for tylko_data in df.iloc[29+i*2:29+i*2+o*2:2,2] :
tylko_data = pd.to_datetime(tylko_data).date()
df.iloc[tab2,2] = str(tylko_data.strftime('%d.%m.%Y'))
tab2 += 2
df.iloc[29+i*2:29+i*2+o*2:2,2] = ""
tab3 = 22+i*2
for kazdy in df.iloc[29+i*2:29+i*2+o*2:2,3] :
df.iloc[tab3,3] = str(round(kazdy,2))
tab3 += 2
df.iloc[29+i*2:29+i*2+o*2:2,3] = ""
tab6 = 22+i*2
for kazdy in df.iloc[29+i*2:29+i*2+o*2:2,6] :
df.iloc[tab6,5] = str(kazdy)
tab6 += 2
df.iloc[29+i*2:29+i*2+o*2:2,5] = ""
tab9 = 22+i*2
for tylko_data in df.iloc[29+i*2:29+i*2+o*2:2,9] :
tylko_data = pd.to_datetime(tylko_data).date()
df.iloc[tab9,7] = str(tylko_data.strftime('%d.%m.%Y'))
tab9 += 2
df.iloc[29+i*2:29+i*2+o*2:2,9] = ""
tab10 = 22+i*2
for kazdy in df.iloc[29+i*2:29+i*2+o*2:2,10] :
df.iloc[tab10,9] = str(round(kazdy,2))
tab10 += 2
df.iloc[29+i*2:29+i*2+o*2:2,10] = ""
tab12 = 22+i*2
for kazdy in df.iloc[29+i*2:29+i*2+o*2:2,12] :
df.iloc[tab12,10] = str(round(kazdy,2))
tab12 += 2
tab_usun = 22+i*2
for g,(j,d) in enumerate(zip(df.iloc[22+i*2:22+i*2+o*2:2,2],df.iloc[22+i*2:22+i*2+o*2:2,7])):
if j[3:5] == d[3:5]:
G = g*2
tab_usun += G
df.drop([tab_usun,tab_usun+1],axis=0,inplace=True)
tab_usun -= G
drugi = df.iloc[29+i*2::2,1].isnull()
for o , rzad in enumerate(drugi):
if rzad == True :
break
kwota_sumy = 0
for kazdy in df.iloc[22+i*2:22+i*2+o*2:2,10] :
kwota_sumy += float(kazdy)
df.iloc[21+i*2+o*2:,1:] = ""
df.iloc[22+i*2+o*2,9] = 'Razem:'
df.iloc[22+i*2+o*2,10] = str(round(kwota_sumy,2))
kwota = float(df.iloc[14+i*2,9]) + kwota_sumy
df.iloc[25+i*2+o*2,1] = 'ŁĄCZNA KWOTA ODSETEK NALICZONYCH: ' + str(round(kwota ,2))
df.iloc[28+i*2+o*2,1] = 'Wystawił(a): ' + imie
while True:
rachunek = input('Podaj nr rachunku bankowego: ')
if len(rachunek) == 26:
df.iloc[27+i*2+o*2,1] = "Rachunek bankowy: "+rachunek
zapis()
print('''Lista plików:\n\n \\/\n''')
katalog()
break
elif len(rachunek) > 26:
print('Podany numer ma',len(rachunek),'znaków, o',len(rachunek) - 26,'za dużo.')
else:
print('Podany numer ma',len(rachunek),'znaki, o' ,26 - len(rachunek),'za mało.')
def ods_nie_rozliczne():
df.iloc[9,2:] = ''
df.iloc[11,1] = 'Nr dokumentu'
df.iloc[11,2] = 'Data dokumentu'
df.iloc[11,3] = 'Termin płat.'
df.iloc[11,5] = 'Kwota'
df.iloc[11,7] = "Do zapłaty"
df.iloc[11,9] = 'Kwota odsetek'
df.iloc[11,10] = 'Data odsetek'
df.iloc[13,1:] = '--------'
df.iloc[16,1] = "Odsetki od dokumentów zapłaconych po terminie"
df.iloc[18,1] = 'Nr dokumentu'
df.iloc[19,1] = 'zobowiązania'
df.iloc[18,2] = 'Termin płatności'
df.iloc[18,3] = 'Kwota'
df.iloc[18,5] = 'Nr dokumentu '
df.iloc[19,5] = "zapłaty"
df.iloc[18,7] = "Data zapłaty"
df.iloc[18,9] = "Kwota zapłaty"
df.iloc[18,10] = "Odsetki naliczone"
global kwota_sumy
global o
nr_dok = df.iloc[26::2 ,1].isnull()
for i , row in enumerate(nr_dok):
if row == True :
break
tab1 = 21
for kazdy in df.iloc[26:26+i*2:2,1] :
df.iloc[tab1,1] = str(kazdy)
tab1 += 2
df.iloc[22:22+i*2:2,1] = ""
tab2 = 21
for tylko_data in df.iloc[26:26+i*2:2,2] :
tylko_data = pd.to_datetime(tylko_data).date()
df.iloc[tab2,2] = str(tylko_data.strftime('%d.%m.%Y'))
tab2 += 2
df.iloc[22:22+i*2:2,2] = ""
tab3 = 21
for kazdy in df.iloc[26:26+i*2:2,3] :
df.iloc[tab3,3] = str(round(kazdy,2))
tab3 += 2
df.iloc[22:22+i*2:2,3] = ""
tab6 = 21
for kazdy in df.iloc[26:26+i*2:2,6] :
df.iloc[tab6,5] = str(kazdy)
tab6 += 2
df.iloc[22:22+i*2:2,5] = ""
tab9 = 21
for tylko_data in df.iloc[26:26+i*2:2,9] :
tylko_data = pd.to_datetime(tylko_data).date()
df.iloc[tab9,7] = str(tylko_data.strftime('%d.%m.%Y'))
tab9 += 2
df.iloc[26:26+i*2:2,9] = ""
tab10 = 21
for kazdy in df.iloc[26:26+i*2:2,10] :
df.iloc[tab10,9] = str(round(kazdy,2))
tab10 += 2
df.iloc[26:26+i*2:2,10] = ""
tab12 = 21
for kazdy in df.iloc[26:26+i*2:2,12] :
df.iloc[tab12,10] = str(kazdy)
tab12 += 2
tab_usun = 21
for g,(j,d) in enumerate(zip(df.iloc[21:21+i*2:2,2],df.iloc[21:21+i*2:2,7])):
if j[3:5] == d[3:5]:
G = g*2
tab_usun += G
df.drop([tab_usun,tab_usun+1],axis=0,inplace=True)
tab_usun -= G
nr_dok = df.iloc[26::2 ,1].isnull()
for i , row in enumerate(nr_dok):
if row == True :
break
kwota_sumy = 0
for kazdy in df.iloc[21:21+i*2:2,10] :
kwota_sumy += float(kazdy)
df.iloc[22+i*2:,1:] = ""
df.iloc[21+i*2,9] = 'Razem:'
df.iloc[21+i*2,10] = str(round(kwota_sumy,2))
df.iloc[24+i*2,1] = 'ŁĄCZNA KWOTA ODSETEK NALICZONYCH: ' + str(round(kwota_sumy ,2))
df.iloc[27+i*2,1] = 'Wystawił(a): ' + imie
while True:
rachunek = input('Podaj nr rachunku bankowego: ')
if len(rachunek) == 26:
df.iloc[26+i*2,1] = "Rachunek bankowy: "+rachunek
zapis()
print('''Lista plików:\n\n \\/\n''')
katalog()
break
elif len(rachunek) > 26:
print('Podany numer ma',len(rachunek),'znaków, o',len(rachunek) - 26,'za dużo.')
else:
print('Podany numer ma',len(rachunek),'znaki, o' ,26 - len(rachunek),'za mało.')
def albo_albo():
if df.iloc[9,1][:9] == "Dokumenty":
df.iloc[9,1]="Odsetki od dokumentów niezapłaconych na dzień 31.12.2020"
dok_nie_rozliczne()
print('\nPlik zapisany pod nazwą '+nazwa)
elif df.iloc[9,1][:7] == "Zapłaty":
dok_nie_rozliczne()
print('\nPlik zapisany pod nazwą '+nazwa)
else:
df.iloc[9,1]="Odsetki od dokumentów niezapłaconych na dzień 31.12.2020"
ods_nie_rozliczne()
print('\nPlik zapisany pod nazwą '+nazwa)
def katalog():
i = 0
for x in sorted(os.listdir()):
i += 1
print(str(i)+".",x)
def sprawdz():
licz = 0
global nazwa
print('''Lista plików:\n\n \\/\n''')
katalog()
while True:
print('\nLiczba not, które zrobiliśmy:',licz)
nazwa = input('Podaj nazwę pliku (bez rozszerzenia): ')+'.xls'
if nazwa == "q.xls":
quit()
elif nazwa == "pomoc.xls":
print('''\n Program jest przeznaczony tylko do "not odsetkowych".
Po uzupełnieniu podpisu oraz nazwy ulicy, dane te będą używane do każdego
dokumentu. Po przejściu do następnego kroku program zapyta o wpisanie nazwy
dokumentu do otwarcia. Plik programu musi być w tym samym folderze co pliki
wygenerowane w rozszerzeniu exela. Nazwe pliku należy wpisać bez rozszerzenia
".xls". Następnie należy wpisać numer numer noty.
Fukcja wyświetli wszystki pliki w katalogu
po lewej stronie a przykładowo jeden z plików to "NO 13.xls" wtedy wystarczy
wpisać "NO 13" i przejdzie do dalszej częsci. Potem będzie trzeba uzupełnić
nr konra bankowego, każdego właściciela za kadym razem bo każdy ma swój
indywidualny. Potem już tylko trzeba podać nazwę pliku do jakiego ma być
zapisany poprawiony plik, też bez rozszerzenia, program ma ustawiony
domyślny format ".xlsx". Jeśli wszystko zostało wpisane poprawnie, nowy
plik zsotanie wygenerowany w tym samym folderze. Zalecam wpisane innej
nazwy nowego pliku. Jeśli coś będzie nie tak, to program wyświetli
komunikat. Program przewiduje sytuacje, w której właściciej nieruchomości
ma uregulowane wszystkie faktury. Teoretycznie nie powinno być niespodzianek.
Praktycznie program został sprawdzony i działał w każdej swojej opcji.
W celach edukacyjnych można mu wpisać cokolwiek a on się nie obrazi a można
sobie spradzić jak działa :)
1. Dane uzupełnione na samym początku progamu, będą zapamiętane do momentu wyłączenia programu:
- Data dokumentu
- Termin płatności
- Tylko rok noty odetkowej(nr za każdym razem będzie dopisywany indywidualnie)
- Nazwe ulicy wspólnoty
- Podpis pod dokumentem, osoby wystawiającej
2. Podanie nazwy pliku, bez rozszerzenia.
3. Numer noty odsetkowej.
4. Podanie numeru konta bankowego.
5. Podanie nazwy do zapisania pliku, również bez rozszerzenia.
''')
elif os.path.isfile(os.getcwd() + "/" + nazwa):
licz += 1
global df
df = pd.read_excel(nazwa)
df.iloc[3,1] = ""
df.iloc[5,1] = 'Data dokumentu: '+data_dokumentu
df.iloc[6,1] = 'Termin płatności: '+termin_plt
try:
all = df.iloc[3,8]
df.iloc[2,9] = all.split('\nOkres')[-2]
len1 = len(all.split('Okres')[-2])
len2 = len1+15
df.iloc[4,9] = all.split('\n'+uli)[-2][len2:]
len3 = len(all.split(uli)[-2])
df.iloc[5,9] = all.split('\n03-288')[-2][len3:]
len4 = len(all.split('03-288')[-2])
df.iloc[6,9] = all[-15:]
df.iloc[3,9] = all[len1:len1+14]
nr_noty = input('Nota odsetkowa nr: ')+'/'
df.iloc[4,1] = 'Nota odsetkowa nr '+ nr_noty + rok_noty
except :
print('\n Zła nazwa ulicy')
time.sleep(5)
quit()
albo_albo()
else:
print('Nie ma takiego pliku.')
def druk():
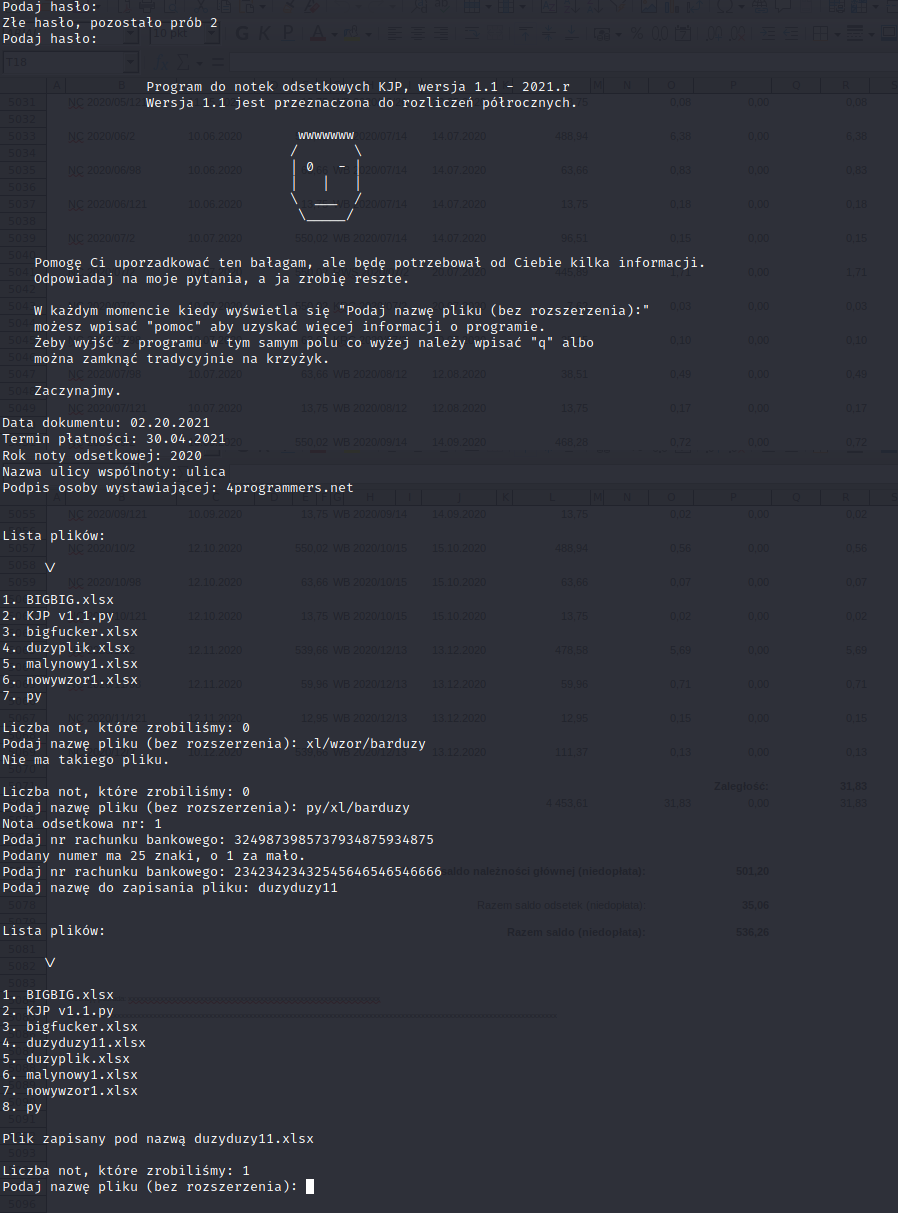
print(''' \n\n Program do notek odsetkowych KJP, wersja 1.1 - 2021.r
Wersja 1.1 jest przeznaczona do rozliczeń półrocznych.''')
print('''
wwwwwww
/ \
| 0 - |
| | |
\\ ___ /
\\ _____ /\n
Pomogę Ci uporzadkować ten bałagam, ale będę potrzebował od Ciebie kilka informacji.
Odpowiadaj na moje pytania, a ja zrobię reszte.
W każdym momencie kiedy wyświetla się "Podaj nazwę pliku (bez rozszerzenia):"
możesz wpisać "pomoc" aby uzyskać więcej informacji o programie.
Żeby wyjść z programu w tym samym polu co wyżej należy wpisać "q" albo
można zamknąć tradycyjnie na krzyżyk.
Zaczynajmy.
''')
global imie
global uli
global data_dokumentu
global termin_plt
global rok_noty
data_dokumentu = input('Data dokumentu: ')
termin_plt = input('Termin płatności: ')
rok_noty = input('Rok noty odsetkowej: ')
uli = input('Nazwa ulicy wspólnoty: ')
imie = input('Podpis osoby wystawiającej: ')
print('\n')
proba = 3
while proba > 0:
haslo = getpass.getpass('Podaj hasło: ')
if proba == 0 :
break
elif haslo == '':
druk()
sprawdz()
else:
proba -= 1
print('Złe hasło, pozostało prób', proba)