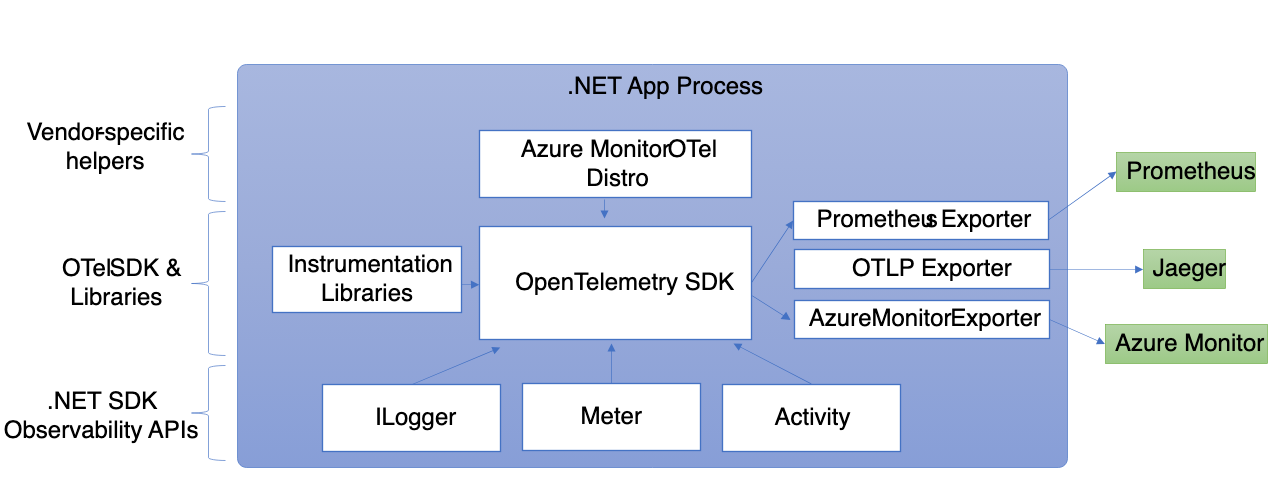
Cześć pytanie o tracing w appce spring bootowej. Jest to nowa apka, którą robimy od zera i potrzebuję dodać tracing do logów.
Mamy eventy w Azure Event Hubs, które na razie (bo nie mamy jeszcze proda - trochę taka zabaw póki co) - generujemy ręcznie poprzez feature Azurowy "Data Generator", gdzie możemy podać jsona i dodać do "kolejki", a w naszej appce spring bootowej consumer sobie je pobiera i wywołuje odpowiednią akcję. Gdzieś w środku logiki uderzamy webclientem do zewnętrznego serwisu.
Jeszcze nie wiadomo w jaki sposób docelowo będą generowane te eventy.
Co potrzebuję:
- Dodać trace id (minimum z wymagań) i jakiś correlation id, te dane muszą być propagowane do każdego z serwisów.
I teraz pytanie, z czego najlepiej skorzystać?
Czytam o Spring Cloud Sleuth oraz Micrometer. Lead coś wspominał, żeby obczaić czy Micrometer nie wystarczy lub coś innego niż Sleuth, ale z tego co ja czytam to Micrometer chyba nie jest do tracingu.
- Potrzebuję zastanowić się jak to zrobić w dwóch przypadkach:
- dla obecnej sytuacji, gdzie generujemy event ręcznie z jsonem - raczej w tym przypadku to nie my powinniśmy generować trace id itd, tylko już po stronie consumera w logice?
- Jeśli jest jakiś producent w appce, który generuje eventy - wtedy już producent będzie tworzył trace id/ correlation id itp.
Powiedzmy, że mam pomysł na otrzymywanie eventu w formie obiektu:
class Request<T> {
String traceId;
String correlationId;
T request; //tutaj json z danymi
}
czy odpalając całe flow w spring appce dla tego eventu, zaczynając od consumera, który wywołuje jakąś logikę (.handle(event)) powinienem do każdej metody przekazywać ten traceId, correlationId, żeby przy uderzeniu do zewnętrznego serwisu posłać te dane?
Nie za bardzo wiem jak to ma działać :)
Będę wdzięczny za jakąkolwiek pomoc, nawet wskazówkę typu "poczytaj o".
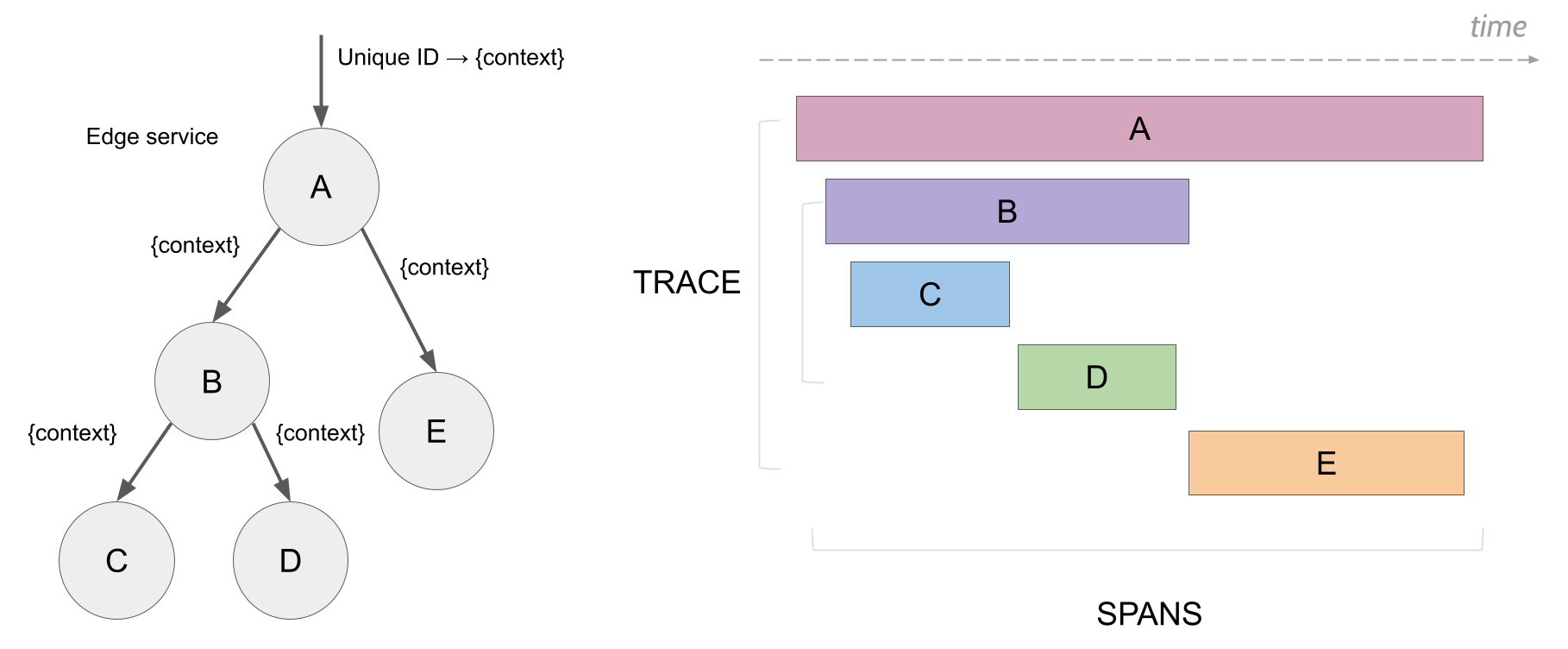
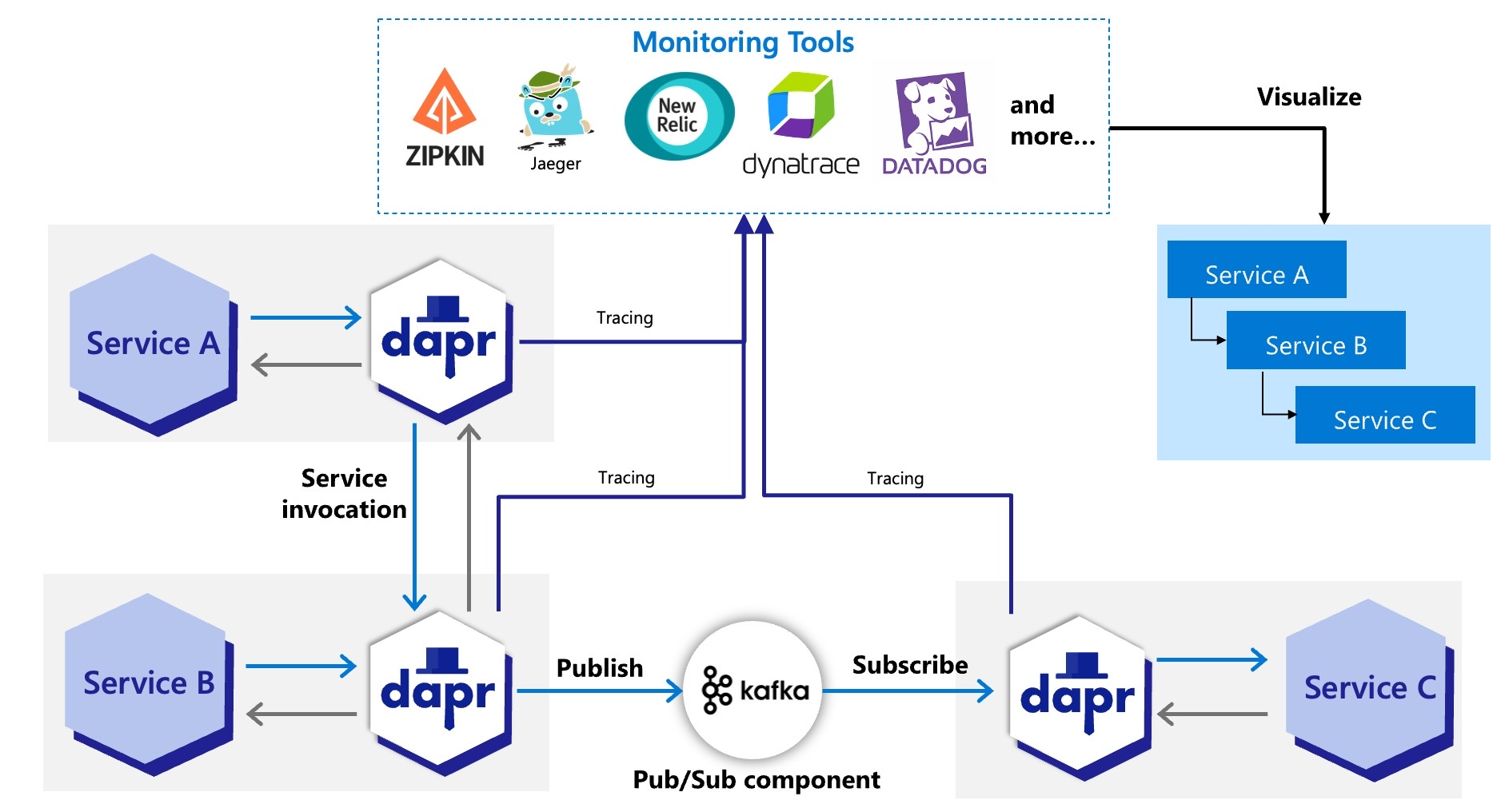
 keep calm :)
keep calm :)