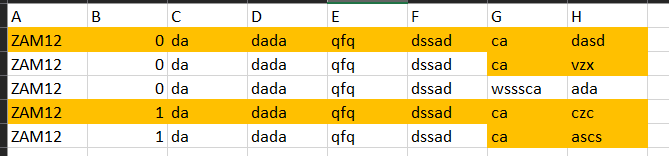
Przerzucam dane z pliku csv do exceli. Dokładnie wygląda to tak że z jednego dużego pliku który zawiera bardzo dużą ilosć zamówien i mam wyciągnąć każde zamówienei do osobnego pliku. Z tym że w przypadku kiedy zamowienie się powiela cześć danych z kolumn sprowadzam to do jednego wiersza( np. kolumy od A do F). Wstępnie było to tak że z koluny A była pobierana nazwa i jak się dublowała to zawijałem wiersze do tej kolumny F. Teraz doszło mi coś takiego że dubluje się jedynie wtedy kiedy w kolumnie A i B są te same dane. I w tej chwili nadpisuje mi się rekord a nie zawija czyli dostaje zawsze nagłówki + jedną linie rekordu. Poniżej wklejam kod może ktoś podpowie co jest nie tak ?
private void process(List<CSVRecord> entries, Path directoryPath, Path inputPath) throws IOException {
logger.info("Preparation of order");
List<String> headers = getHeaders(inputPath);
LinkedHashMap<String, List<List<Object>>> res = new LinkedHashMap<>();
LinkedHashMap<String, String> orders = new LinkedHashMap<>();
HashSet<String> revision = new HashSet<>();
entries.forEach(entry -> {
int cutoff = 0;
if (orders.keySet().contains(entry.get(0))) {
cutoff = 7;
}
revision.add(entry.get(1));
orders.put(entry.get(0), entry.get(1));
List<String> csvTokens = Streams.stream(entry.iterator()).collect(Collectors.toList());
List<String> secondPart = csvTokens.subList(cutoff, csvTokens.size());
Stream<Object> nulls = Collections.nCopies(cutoff, null).stream();
List<Object> result = Stream.concat(nulls, secondPart.stream()).collect(Collectors.toList());
List<List<Object>> x = res.getOrDefault(entry.get(0), new ArrayList<>());
x.add(result);
res.put(entry.get(0) + "_" + entry.get(1), x);
});
res.entrySet().forEach(it -> {
Path csvPath = null