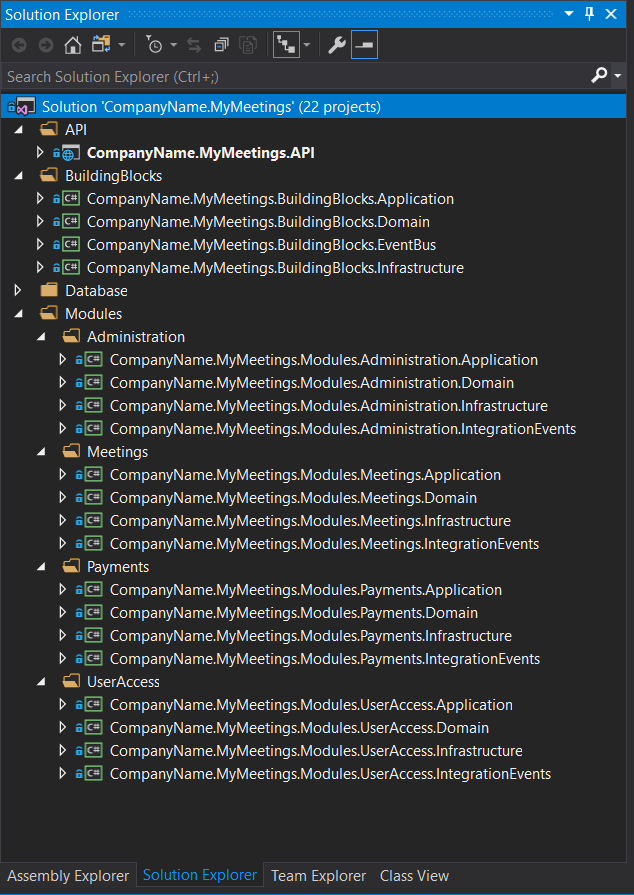
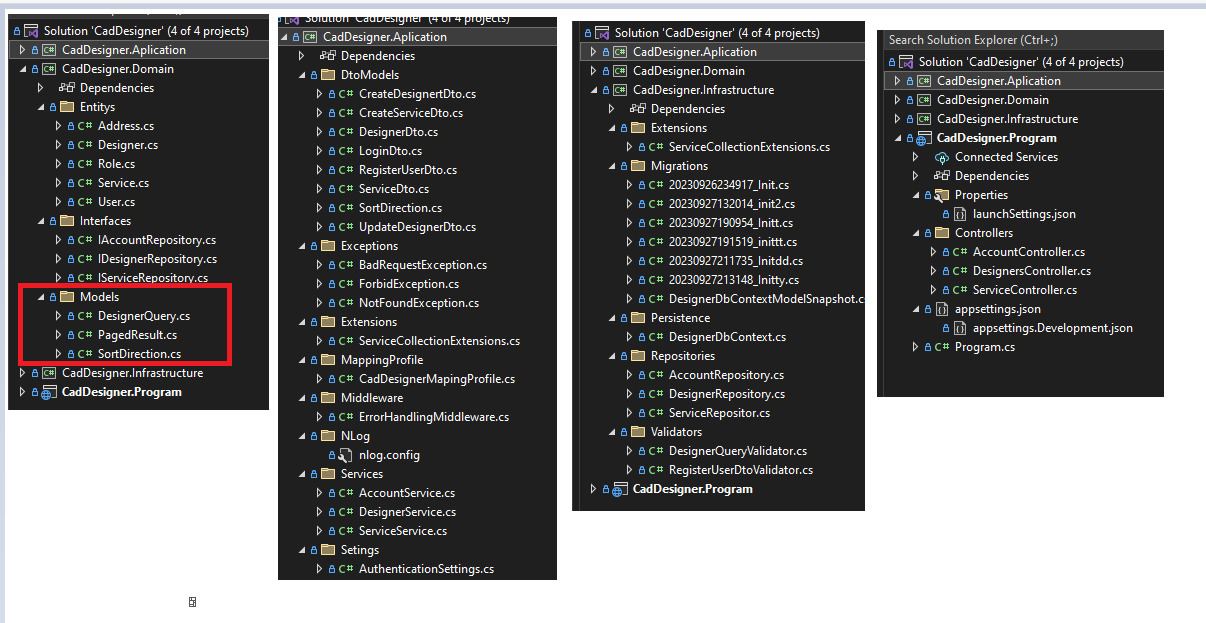
Mam kilka WebApi zrobionych "tradycyjnie" czyli w oparciu o kontrolery i serwisy odpowiedzialne za logikę. Obecnie już wystartowałem z nowym projektem w którym bazuje na o Clean Code/Clean Architecture. Niestety widzę, że nie jest to takie proste i wiele rzeczy robię na tzw. czuja. Jak to mówią pierwsze koty za płoty. Liczę, że potem będzie tylko lepiej aczkolwiek cały czas nie widzę po co stosować tą architekturę. Mam nadzieje, że w końcu załapię ;)
Chciałem powiedzieć że porywasz się z motyką na słońce, i prościej byłoby do tego podejść np z toolem albo programem CLI.
Podpowiedz mi z jakimi problemami mogę się zderzyć?
No moim zdaniem główny problem jaki znam, to to że w imię clean code'a ludzie wsadzają abstrakcje w nieodpowienie miejsca (tam gdzie nie powinni), ale za to omijają odpowiednie (nie wkłajadają tam gdzie powinni). Czyli innymi słowy - abstrakcje są wrzucane na opak.
Wiesz zapewne tak jak mówisz na początku było by łatwiej zrobić coś konsolowego ale nie wiem też do końca co masz na myśli. Chodzi Ci o to, że przy aplikacji konsolowej łatwiej zrozumieć jak tworzy się CleanCod?
Tak myślę, bo jest mniej zależności. W aplikacji webowej masz oprócz domeny: klient, static filesy, js, na pewno jakiś framework js, biblioteki klienta, .env, klucze, shareowanie kluczy, autoryzacja, http, rest, api, controllery, framework backendowy, bazę danych, orm'a, na pewno system budowania, dodatkowe biblioteki, masa rzeczy, które się przeplatają ze sobą. Wszystkie te rzeczy, idealnie powinny być od siebie poprawnie oddzielone w racjonalnych proporcjach, i nie jest to łtawe.
W aplikacji konsolowej masz tak na prawdę tylko domenę i interfejs stdio. Oddzielenie tego jest bardzo łatwe, i testowanie tego też jest łatwe.
Mi wydaje się, że to już rozgryzłem. Obecnie mam problem z interpretacją do jakiej warstwy upchnąć daną funkcjonalność.
No i to jest zupełnie odwrotne działanie. Najpierw powinieneś napisać jakiś kod, i potem spróbować zastanowić się jaką warstwę reprezentuje ten kod. Jak już zrozumiesz do jakiej warstwy należy kod, powinieneś w tym miejscu dodać odpowiednie abstrakcje. Oczywiście może być tak, że kod napisałeś jest pomieszany i należy do kilku warstw na raz. To jest wtedy trudniejsze zadanie bo wtedy najpierw trzeba "rozplątać" ten kod, na osobne warstwy, i dopiero potem je oddzielać. to miałem na myśli że jest to trudniejsze, jak masz dużo zależności, np w aplikacji webowej.
A nie, że myślisz "gdzie by tu wsadzić ten kod". To jest trochę odwrócone wnioskowanie.
Z drugiej strony jeśli coś pójdzie nie tak to pracuje nad swoim projektem, a nie komercyjnym za czyjeś pieniądze bo ja nawet nie jestem juniorem i zapewne najbliższym czasie ten stan rzeczy nie uległ zmianie w związku z obecną sytuacją w IT, ale mam wizję swojej apki i cisnę z nią dalej aby koniec końców ją uruchomić :)
Działanie aplikacji to jedno. To czy jest dobrze napisana to inne. Jest masa działających apek które są napisane jak shit.
Jest cytat od Roberta Martina, autora książki "Clean Code".
If the program works, but I don't understand it, as soon as the requirements change, that program is useless. If a given program doesn't work or even compile, but I can understand it and reason through its logic, I can fix any non-working program you throw at me.
To jest trochę rozszerzenie filozofii ownowania swojego kodu i nie bania się zmian.
Dla przykładu, znalazłem na stack overflow taką prostą gierkę w zgadywanie liczb: https://stackoverflow.com/questions/9086168/random-number-guessing-game
Niby kod na 30 linijek, ale jednak widać tu trzy poziomy abstrakcji:
- Sama gra
- Losowanie liczb pseudolosowych
- Interfejs konsolowy
Gdzie są poszczególne warstwy? Otóż tutaj:

Dobre rozdzielenie tych odpowiedzialności nie jest proste.
PS: Tak, Main() nie należy do domeny gry tylko do interfejsu.