Piszę bibliotekę do event sourcingu i mam dylemat jakie podejście zastosować. Sprawa jest więc prosta- proszę abyście zaznaczyli które podejście jako konsument biblioteki preferujecie, i w miarę możliwości uargumentowali jakoś swój wybór.
Chodzi o odbudowywanie stanu z eventów. Umyślnie nie podaję kodu wywołującego te stany (obiekty), ponieważ zależy mi na Waszej opinii z perspektywy konsumenta biblioteki.
Opcja 1
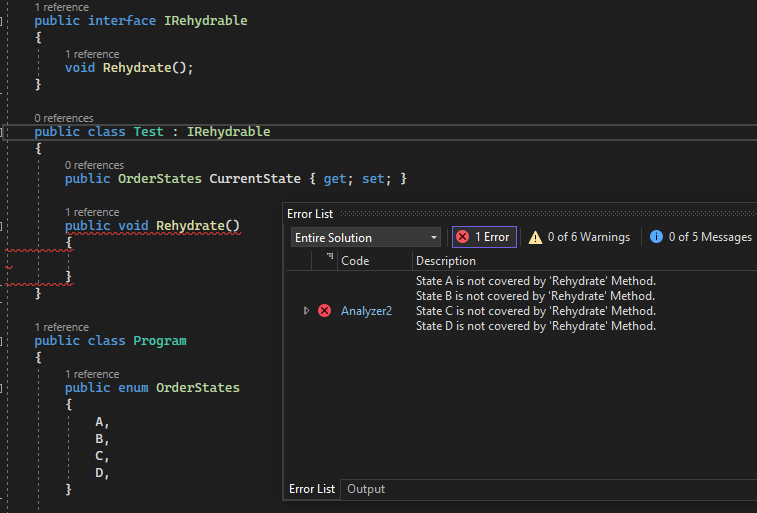
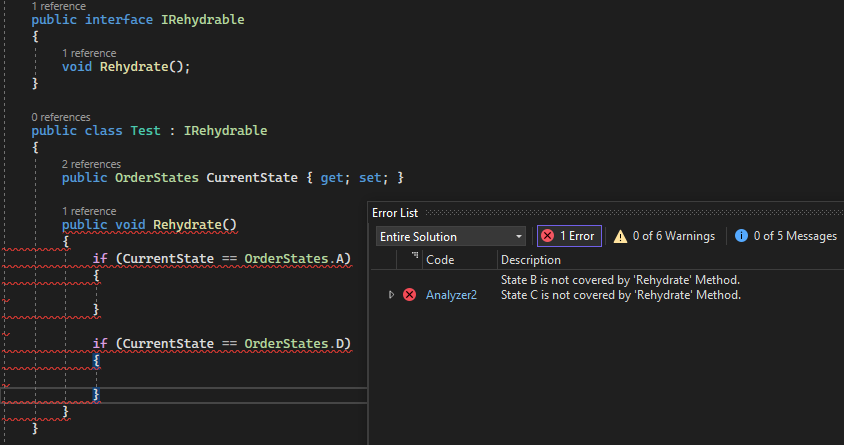
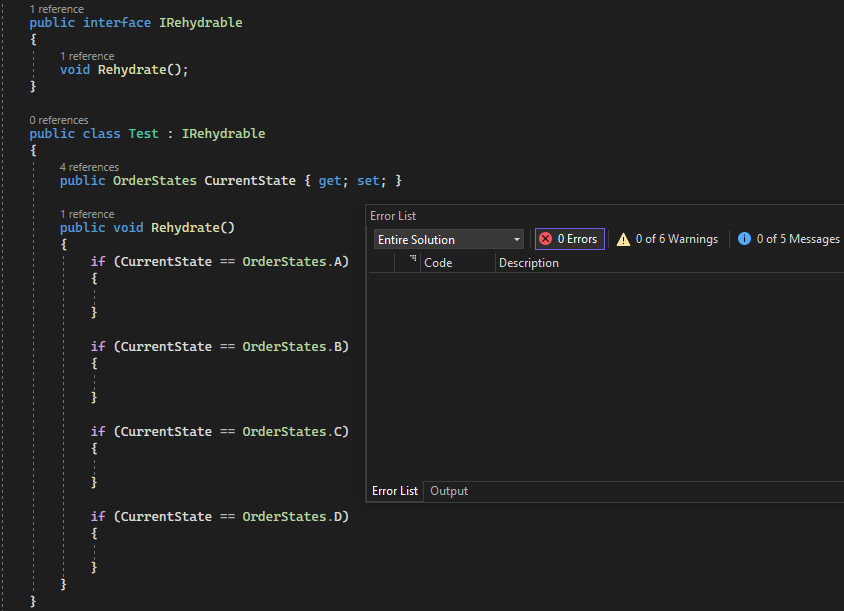
Wymóg aby każdy stan implementował poniższy interfejs. Oczekuje się że metoda Rehydrate zwróci nową instancję stanu, ale oczywiście nie da się tego zagwarantować i implementacja zależy od klienta.
public interface IAggregateState
{
IAggregateState Rehydrate(IEvent @event);
}
Oraz sama klasa stanowa:
public record OrderState : IAggregateState
{
public string OrderId { get; init; } = string.Empty;
public OrderStatus Status { get; init; } = OrderStatus.InProgress;
public IAggregateState Rehydrate(IEvent @event) =>
@event switch
{
OrderPlaced e => this with { OrderId = e.OrderId, Status = OrderStatus.Placed },
OrderDispatched e => this with { Status = OrderStatus.Dispatched },
OrderDelivered e => this with { Status = OrderStatus.Delivered },
_ => this
};
}
Zauważcie, że używam w przykładzie C# 10, stąd mogę napisać bardziej zwięzły kod. Klient korzystający z biblioteki może nie mieć takiej możliwości, więc wtedy trzeba by to napisać inaczej.
Opcja 2
Wymóg aby dla każdego eventu klasa stanowa posiadała publiczną metodę Apply, ale brak wymogu implementacji interfejsu. Wywołanie Apply odbywa się "magicznie", coś jak w przypadku ConfigureServices czy Configure w ASP Core:
public record OrderState
{
public string OrderId { get; private set; } = string.Empty;
public OrderStatus Status { get; private set; } = OrderStatus.InProgress;
public void Apply(OrderPlaced @event)
{
OrderId = @event.OrderId;
Status = OrderStatus.Placed;
}
public void Apply(OrderDispatched @event)
{
Status = OrderStatus.Dispatched;
}
public void Apply(OrderDelivered @event)
{
Status = OrderStatus.Delivered;
}
}