to już lata temu mógł wziąć bibliotekę do optionali i używać ich zamiast zwykłych referencji
aby były prawdziwe optionale, to chcą mieć najpierw dyskryminowane związki ;)
Raczej nie było presji aby wrzucić Optional<T> bo jak sam napisałeś, mogłeś sobie wziąć libkę.
Optionale zmieniają podejście do programowania, a wymuszanie na tak ogromną skalę zmiany podejścia jest raczej bardzo, bardzo słabe.
Nullable ref types są bardziej naturalne dla środowiska - wyobraź sobie jakby Ci teraz cały kod frameworka / corowych bibliotek zmienili na Optional<T> - cały istniejący kod by przestał działać, a podnoszenie wersji wiązałoby się z ogromnymi kosztami dostosowania, pewnie byłaby sytuacja jak z pythonem.
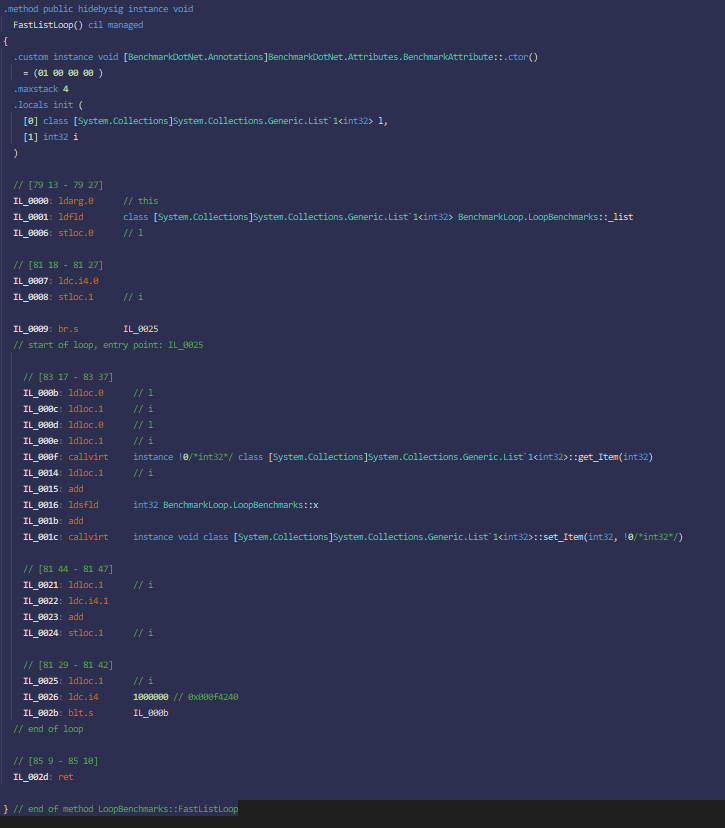
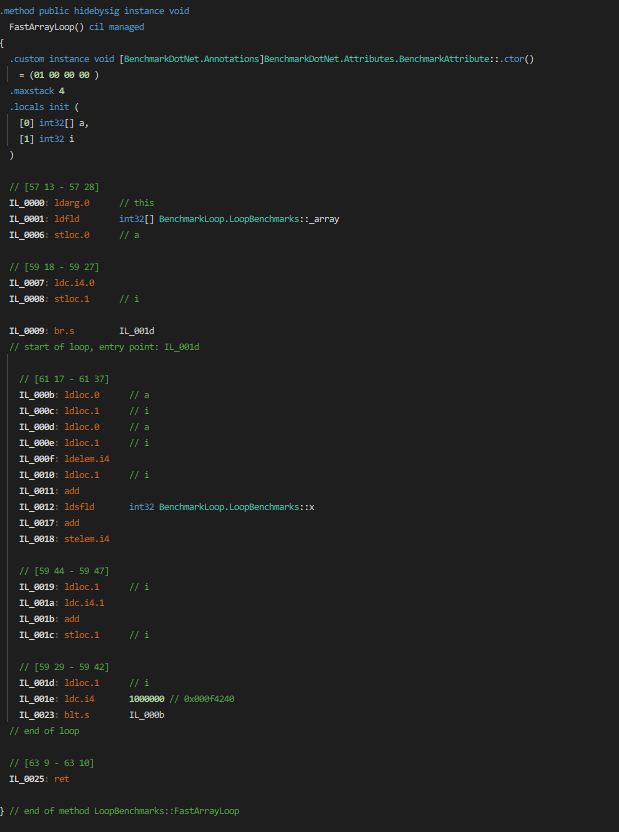
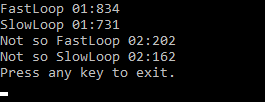
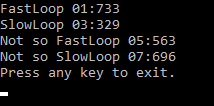
Wystarczyło nie robić nullable references, a kasę w to władowaną przeznaczyć na rozwój GC, żeby wreszcie wyciągnąć porządny interfejs, sensowną implementację i wejść w obszar sparka. Albo w JIT-a, żeby dotnet umiał inline'ować gettery.
skąd pomysł że kasa jest problemem
Spark dla .NET Developerów w przykładach dla .NET Core via Asseco
patrz, w polskim faamgu już to mają.