Cześć,
jak mierzymy wydajność dysku to bierzemy pod uwagę szybkość odczytu (oraz zapisu) sekwencyjnego oraz losowego.
Jeśli kupię sobie 4 dyski i zrobię sobie RAIDa to zwiększy mi się szybkość jedynie odczytu sekwencyjnego.
Pytanie: jeśli dysk ma służyć pod bazę danych (relacyjną) to większe znaczenie ma odczyt sekwencyjny czy losowy?
Moje wątpliwości wynikają z tego, że raz dane zapisuję do jednej tabeli a raz do drugiej i mam wątpliwość czy jak będę wydobywał dane z jednej tabeli to czy te dane będą pobierane jeszcze sekwencyjnie czy już bardziej losowo?
Zastanawiam się również czy RAID powinien zwiększyć wydajność bazy danych?
Czy dyski nvme robią różnicę w stosunku do zwykłych ssd (SATA) - w kontekście baz danych?
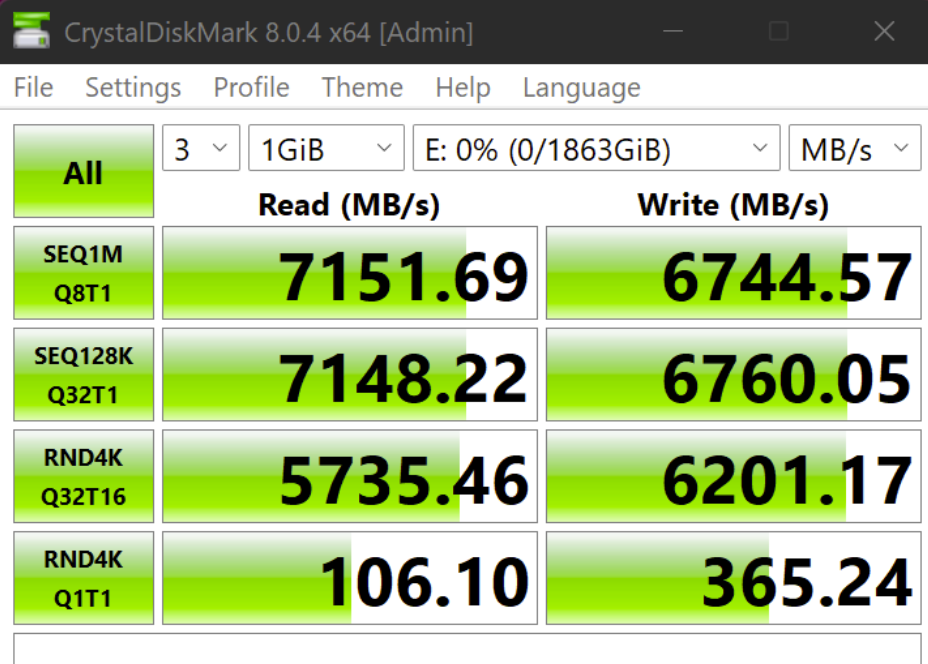
Poniżej zdjęcie z testów jednego z dysków: który parametr jest kluczowy w kontekście baz danych:
Z góry dziękuję za wyjaśnienie tematu.