@W2K, @Varran, sorry że tak długo, ale nie mogłem znaleźć weny do rysowania. ;)
Może o jakiś prosty diagram bym poprosił ;-)
Zakładając, że celem jest izolacja logiki biznesowej od warstwy dostępu do danych w przypadku code first wygląda to jak na poniższym diagramie:
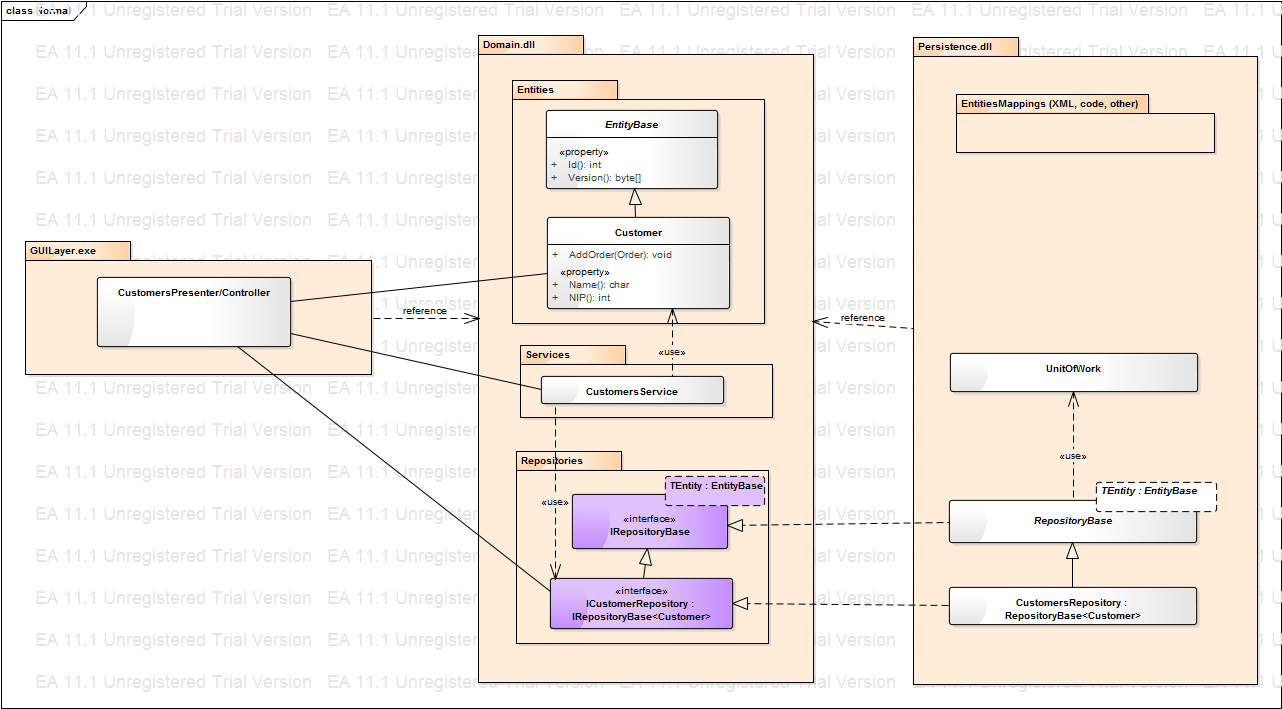
Mamy naszą domenę, w której znajdują się: encje, serwisy i repozytoria. Repozytoria są oczywiście interfejsami, a ich konkretne implementacje znajdują się w warstwie składowania. Tam też znajduje się konfiguracja mapowań (XML, klasy mapujące, konwencje - zależy co chcemy i na co pozwala nam nasz ORM). Wszystko tu jest czytelne i oczywiste, w jednym module mamy klasy odpowiedzialne za logikę biznesową, w drugim za dostęp do bazy, logika biznesowa nic o bazie nie wie.
W przypadku Entity Framework i Database First sprawa się komplikuje, bo kod z generatora jest pomieszaniem encji - czyli logiki biznesowej z kontekstem i informacjami o mapowaniach, czyli warstwą bazodanową. Żeby osiągnąć efekt, o który nam chodzi, musimy się napracować więcej, co obrazuje poniższy diagram:
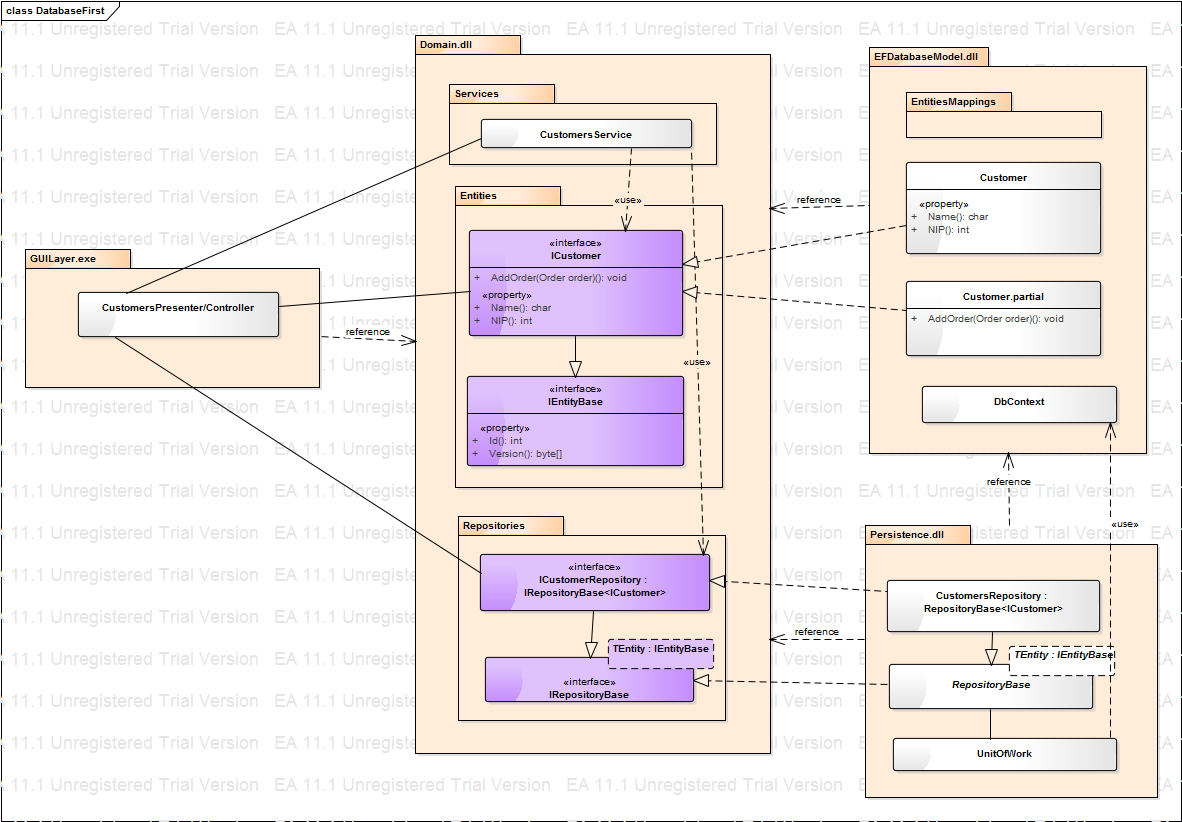
Model EF jest nienaruszalny, więc musimy zmieniać domenę. Encje w niej nie są już klasami lecz interfejsami, które są implementowane przez encje z EF. Właściwości są w klasach wygenerowanych automatycznie, natomiast dodatkowe metody dopisujemy do klas partial. Repozytoria też musiały się zmienić - operują na interfejsach encji, a nie ich implementacjach. Warstwa składowania zmieniła się o tyle, że korzysta z modułu z modelem EF, w którym znajdują się mapowania i DbContext, z którego korzystają implementacje repozytoriów. Model z EF nie może znajdować się w tym samym module, co repozytoria, gdyż spowodowałoby to cykliczną zależność między Domain.dll i Persistence.dll, dlatego niestety musi być w oddzielnym module.
A co do Database Firrst, to myśałem że w sumie to się najczesciej stosuje w praktyce ?
Trudno mi powiedzieć, czy najczęściej. Ale zapewne wiele osób, które uważają, że tworzenie aplikacji trzeba zaczynać od bazy, tak właśnie robi. Tylko, że to nie jest wydajna metoda tworzenia oprogramowania. Zaczynając od kodu, można łatwo wprowadzać zmiany w domenie, np. dodanie nowej właściwości albo zmiana powiązania między klasami jest szybka. Można stosować podejście TDD, pisać testy przed implementacją i osiągnąć wysoki poziom pokrycia testami. Możemy nawet zbudować prototyp aplikacji, pokazać go klientowi, a dopiero gdy stwierdzi, że mu wszystko pasuje, wygenerować bazę danych.
Jeśli zaczynamy od bazy, to każdą zmianę w modelu danych najpierw musimy wprowadzić w bazie, a potem odświeżamy model, co zazwyczaj wymaga późniejszych ręcznych poprawek. Głupia zmiana nazwy/typu właściwości zajmuje kilka minut zamiast sekund.
Jak w praktyce rozwiązuje się problem z połączniem logiki z bazą danych jeśli mamy już gotową baze ?
Jak kto woli. Moim zdaniem to, co narysowałem na diagramie, to przesada. Trzeba dopisać sporo rzeczy, które właściwie dublują już istniejący kod. Zmiany też trzeba będzie wprowadzać w kilku miejscach.
Osobiście przy database first wolę zostawić wygenerowany przez EF model (nawet nie dopisywać do niego żadnych metod), opakować go w serwisy biznesowe, a bardziej skupić się na odizolowaniu warstwy GUI od encji. Mam na myśli to, że obiekty wyświetlane i edytowane w GUI nie są encjami lecz jakimiś ViewModelami, które dopiero w warstwie biznesowej mapowane są na encje. Zmiany w strukturze danych, poza koniecznością odświeżenia modelu z bazy, powodują wyłącznie zmiany w serwisach biznesowych. Nie jest to co prawda szczyt inżynierii oprogramowania, ani nawet programowania obiektowego, daleko temu do DDD, ale jak pisałem - próba zrobienia z database first czegoś sensownego to gra raczej nie warta świeczki.

