Piszemy taki mikroserwis A, który wystawia pewne API.
Przed tym mikroserwisem jest BFF (który też piszemy), który m.in. komunikuje się
z tym mikroserwisem A można powiedzieć, że API A i BFF jest 1:1.
Natomiast ten BFF to ma nie być tylko przelotka w opisie story jest,
że zanim wywoła nasz backend A ma sprawdzić stan środków na koncie
wywołując powiedzmy 2 inne serwisy. Czy takie wykonywanie logiki biznesowej w BFF
według was jest ok czy to już patologia?
0
0
Nie znam definicji BFF, ale w takiej stuacji czym się różni BBF od zwykłego mikroserwisu? Może tym że nie ma dostępu do żadnej bazy bezpośrednio?
Z drugiej strony jakby BBF był zwykłą przelotką to po co go pisać? Żeby zmienić format odpowiedzi?
2
Czytam definicję - BFF przypomina mi warstwę kontrolera w starych architekturach z generowaniem HTMLa na backendzie - z założenia kontrolery miały być głupie a większość roboty miał robić model
Tylko że teraz nie jest rozróżnienie twardy klient - miekki klient, a klient webowy vs klient mobilny.
- Model (normalne mikroserwisy) - powinieny mieć wspólną logikę używaną przez wszystkich klientów
- kontrolery (BFF) - powinny miec logikę dedykowaną dla klienta (webowego, mobilnego)
Tak to widzę. Chociaż pewnie masz tylko klienta webowego i te rozważania sią bezsensowne
5
Z definicji może zawierać taką logikę. Z tą różnicą że dla mnie jest to logika aplikacyjna nie biznesowa. BFF jest takim orkiestratorem, który woła pod spodem inne serwisy, które zawierają już właściwą logikę biznesową (oblicz wartość zamówienia, oblicz rabat, etc).
1
Zależy. Jak to sprawdzenie ma na celu jedynie przyśpieszone uwalenie zapytania to czemu nie. Jeśli BFF nie wprowadza nic nowego tj. bez BFF można osiągnąć tą samą logikę bez pisania logiki BFF w innym serwisie/froncie to jest ok
0
Pytanie czy rolą trzymania jakichś reguł biznesowych nie powinien być sam backend
a BFF powinien być odpowiedzialny tylko za składanie wyniku a nie jeszcze za jakąś
walidację biznesową. Przynajmniej ja tak rozumiałem ten pattern do tej pory.
2
Poczytaj czym się różni logika aplikacji od logiki biznesowej. BFF zapewnia logikę aplikacji, logika biznesowa siedzi normalnie w serwisach. Orkiestracja procesu to nie logika biznesowa.
0
Ok ale backend też może robić orkiestrację procesu w jakimś serwisie aplikacyjnym dlaczego do BFF to pchać? Jakaś autoryzacja, logi tak
ale reguły w BFF w stylu jeśli user nie ma wystarczających środków na koncie to nie przepuszczaj dalej to dla mnie trochę dziwne.
1
Gdzie w monolicie byś umieścił tą logikę? W warstwie aplikacji czy dziedziny?
0
Nie wiem co konkretnie masz na myśli pod pojęciem aplikacja i dziedzina.
Ja bym pewnie miał jakiś serwis, który najpierw by zawołał klienta do zewnętrznego mikroserwisu,
który by mi zwrócił informację w jakimś dto czy user ma wystarczającą ilość środków jeżeli ma to bym
pchnął proces biznesowy dalej jeżeli nie zwróciłbym błąd z api.
3
Nie chce mi się pisać książki, ale w skrócie współczesne architektury takie jak Onion/Clean/Hexagonal wyróżniają cztery warstwy:
- Presentation Layer: Provides an interface to the user. Uses the Application Layer to achieve user interactions.
- Application Layer: Mediates between the Presentation and Domain Layers. Orchestrates business objects to perform specific application tasks. Implements use cases as the application logic.
- Domain Layer: Includes business objects and the core (domain) business rules. This is the heart of the application.
- Infrastructure Layer: Provides generic technical capabilities that support higher layers mostly using 3rd-party libraries.
Po więcej zachęcam do poczytania w sieci bo to są podstawy architektury oprogramowania.
Co do różnic pomiędzy logiką aplikacji a logiką dziedzinową to poczytaj tutaj https://enterprisecraftsmanship.com/posts/what-is-domain-logic/
Jeżeli czujesz że twój use case jeśli user nie ma wystarczających środków na koncie to nie przepuszczaj dalej jest logiką dziedzinową, a nie aplikacyjną, to macie źle podzielone usługi i coś co nazywa się rozproszonym monolitem, bo w tej sytuacji ten przypadek użycia prawdopodobnie powinien być częścią jednego serwisu. Ale nie znam specyfiki waszego biznesu i jakie macie procesy, więc nie odpowiem ci jak to zrobić zgodnie z waszymi wymaganiami.
Najważniejsze to wiedzieć czy ten use case jest logiką dziedzinową, czy aplikacyjną i dopiero na tej podstawie podejmować decyzje, w której warstwie ten przypadek ma być zaimplementowany. Być może ma być osobną usługą, nie wiem bo nie znam waszej domeny biznesowej.
Z perspektywy BFF to ten serwis przed serwisami dziedzinowymi pełni rolę orkiestratora i odpowiada za komunikację z serwisami poniżej aby zaimplementować use case na poziomie logiki aplikacyjnej. Logika dziedzinowa siedzi w serwisach poniżej.
0
Z artykułu:
Your domain model is responsible for generating business-critical decisions while all other parts of your code base just interpret those decisions or provide input needed to make them.
Wychodzi na to, że jeżeli dobrze rozumiem to mój use case nie jest logiką dziedzinową tylko
aplikacyjną ponieważ ja się pytam o to innego mikroserwisu, czyli gdzie indziej podejmowana
jest decyzja czy user ma środki czy nie a ja wynik traktuję jako input do podjęcia innej decyzji.
Czy nie ma nic złego w tym, że logika aplikacyjna jest w taki sposób rozpraszana i część jest
w backend a część a BFF?
3
Zasadnicze pytanie to czy macie więcej niż jedną aplikację, która musi obsłużyć ten proces. BFF stosuje się aby mieć dedykowane API dla przykładowo aplikacji webowej i dedykowane API dla aplikacji mobilnej, które współdzielą logikę biznesową (serwisy domenowe). Innego powodu do stosowania BFF nie ma.
Jeżeli umieścisz tą logikę w serwisie BFF obsługującym aplikacje webową to musisz zrobić duplikację w serwisie BFF dla aplikacji mobilnej. Stąd prosty wniosek, że możecie mieć źle wydzielone odpowiedzialności usług i rozproszony monolit, który nie ma żadnych zalet a wszystkie wady monolitu i mikroserwisów i że ta operacja powinna być częścią usługi domenowej i zawierać się w pojedyńczej usłudze.
Żeby zobrazować to lepiej to możemy przyjąć założenie, że w sytuacji, gdy serwis A mocno zależy od B aby wykonać jakąś operację to nie powinny one być od siebie rozdzielone a powinny stanowić całość.
Przykład.
Składam zamówienie i teraz pytanie czy jeżeli serwis do wysyłania powiadomień email nie działa, to czy blokuje to główny serwis odpowiedzialny za obsługę zamówienia żeby obsłużyć mój request? Oczywiście, że nie. Zamówienie zostanie złożone, stany magazynowe się zaktualizują, na ekranie dostanę potwierdzenie, że zamówienie zostało przyjęte, ale email z potwierdzeniem przyjdzie za 30 minut albo za godzinę jak go ktoś podniesie po awarii. Widać jasno w tej sytuacji, że serwis do zamówień i serwis do wysyłania powiadomień email z potwierdzeniem mogą być od siebie niezależne i funkcjonować jako dwie aplikacje.
Gdyby w przykładzie powyżej proces obsługi zamówienia był rozbity na dwa lub więcej usług, które są ze sobą ściśle powiązane, tak, że awaria jednej sprawia, że nie działają pozostałe (np. nie mogę obsłużyć zamówienia bo nie mogę sprawdzić czy mam towar na stanie, bo usługa dostarczająca informacje o stanach magazynowych padła) to miałbym poważny problem i jest to sygnał do tego, że nieprawidłowo pociąłem aplikację na usługi.
Ty możesz mieć podobny przypadek, że ktoś nieprawidłowo podzielił aplikację na serwisy i teraz jesteś w sytuacji w której musisz robić takie fikołki jak dalsze rozsmarowywanie logiki po usługach i sprawiać, że jeszcze bardziej od siebie zależą.
Ale tak jak pisałem wyżej nie wiem co tam macie i jak wasze procesy biznesowe wyglądają, dlatego wszystko co piszę to są moje rozważania w oparciu o niepełne dane i musisz sobie wnioski wyciągnąć sam na podstawie swojej wiedzy domenowej.
0
nie mogę obsłużyć zamówienia bo nie mogę sprawdzić czy mam towar na stanie, bo usługa dostarczająca informacje o stanach magazynowych padła
Tak akurat mogłoby się zdarzyć chociaż apka wydaje mi się, że jest dobrze pocięta tj. mamy jakiś order-service i inventory-service.
Aby temu zapobiec możemy np. przeskalować albo przetwarzać asynchronicznie eventami.
1
lukascode napisał(a):
Natomiast ten BFF to ma nie być tylko przelotka w opisie story jest,
że zanim wywoła nasz backend A ma sprawdzić stan środków na koncie
wywołując powiedzmy 2 inne serwisy. Czy takie wykonywanie logiki biznesowej w BFF
według was jest ok czy to już patologia?
Jest błędne. API A powinno być w stanie samo wykonać przypadek użycia, a w tej sytuacji nie jest to możliwe. W celu wykonania przypadku użycia jest się uzależnionym od BFF, czyli de facto od aplikacji klienckiej użytkownika.
0
somekind napisał(a):
Jest błędne. API A powinno być w stanie samo wykonać przypadek użycia, a w tej sytuacji nie jest to możliwe. W celu wykonania przypadku użycia jest się uzależnionym od BFF, czyli de facto od aplikacji klienckiej użytkownika.
A jak to się ma do tego co napisał @markone_dev, że jeżeli to jest logika aplikacyjna to może być w BFF?
2
To jest architekt, on nie utrzymuje tego, co wymyśli. ;)
API samodzielnie powinno realizować przypadki użycia ze swojego obszaru odpowiedzialności. W tym celu zawiera zarówno logikę aplikacyjną jak i biznesową.
Być może jakaś logika aplikacyjna może być w BFF, ale zakładałbym, że to logika konieczna do realizacji potrzeb frontendu, a nie jest częścią biznesowych przypadków użycia.
1
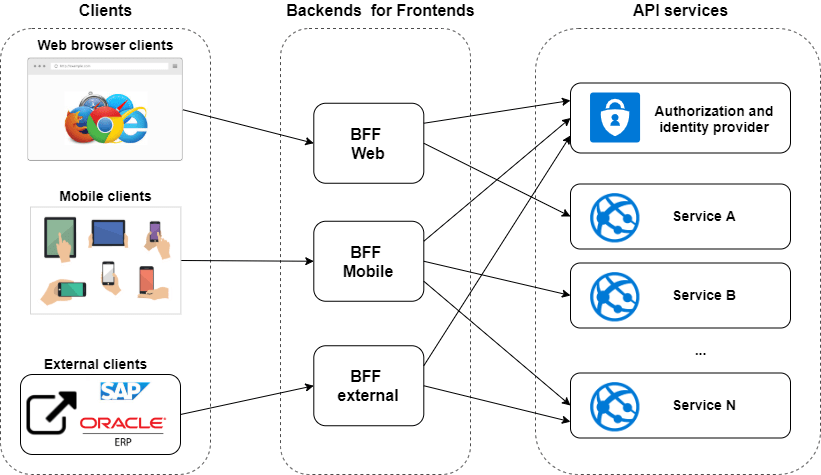
wygląda to strasznie (a w szczególności ta nazwa backends for frontends :D) - w jakiego typu produktach to ma sens?
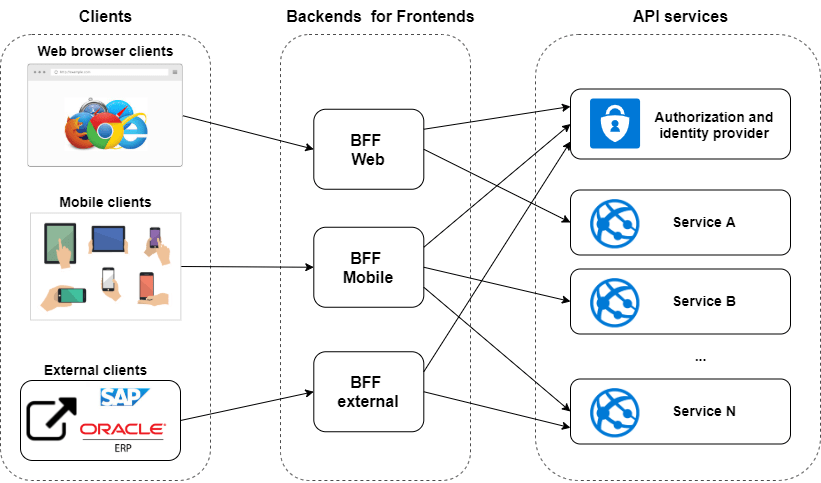
3
We wszystkich, które nie są konsolą i desktopem. Chodzi o to, żeby klient (czy to webowy czy mobilny) wchodził z interakcję z jednym API, a nie ich dziesiątkami/setkami. Myślę, że tak jest znacznie prościej dla frontendowców.
3
w jakiego typu produktach to ma sens?
W takich że masz na przykład aplikacje mobilną która wywołuje ileś serwisów pod spodem. Nie dość że jest jedno API, to zapewnia większą to większą stabilizację - można podmienić spokojnie wersje endpointu docelowego mając ciągle te samo API dla aplikacji mobilnej
czyli można przejść z
aplikacja mobilna -> gateway /v1/something -> serviceX v1/something na
aplikacja mobilna -> gateway /v1/something -> serviceX v2/something
w sposób przeźroczysty dla apki mobilnej
No i jeszcze jest kwestia bezpieczeństwa, dzięki takiemu podejściu możesz ukryć jakies bebechy tj systemy wewnętrzne za takim proxy.
0
@somekind: @scibi_92
to rozumiem, ale skąd ta potrzeba na rozdzielenie tej nakładki na web, mobilke, itd? aż taki duży rozjazd w danych jest pomiędzy stronką i mobilką?
4
Web i mobile może dotyczyć zupełnie czego innego i mieć zupełnie inny cel biznesowy. Może być aplikacja mobilna dla klientów firmy oraz osobny backend nie wiem, dla ludzi z obsługi klienta.
4
1a2b3c4d5e napisał(a):
@somekind: @scibi_92
to rozumiem, ale skąd ta potrzeba na rozdzielenie tej nakładki na web, mobilke, itd? aż taki duży rozjazd w danych jest pomiędzy stronką i mobilką?
To ja mogę się podzielić projektem który realizowałem w duchu BFF (bo BFF to nie tylko podział web/mobile), gdzie były dwa różne API jedno do aplikacji nazwijmy je wewnętrznych i drugie dla klientów zewnętrznych, głównie use case'y integracyjne. I to drugie API było całkiem inaczej zbudowane niż pierwsze, inaczej wersjonowane, itd. Obydwa API wołały pod spodem te same usługi biznesowe.
Jako ciekawostkę dodam, że przez pewien czas mieliśmy 3 API 2xHTTP i 1xSOAP dla starych klientów.
1
W architekturze mikrofrontendowej stosuje się BFFy a w zasadzie to ciężko inaczej
2
1a2b3c4d5e napisał(a):
@somekind: @scibi_92
to rozumiem, ale skąd ta potrzeba na rozdzielenie tej nakładki na web, mobilke, itd? aż taki duży rozjazd w danych jest pomiędzy stronką i mobilką?
Ale to jest pytanie do biznesu. :)
Pracowałem kiedyś w firmie, w której było nawet kilka bffów dla różnych klientów mobilnych, bo inaczej działały te tworzone wewnątrz firmy, a inaczej takie wystawiane do "publicznego użytku" przez innych klientów.
Interfejsów webowych też może być wiele.