Buduję model (oparty o regresję logistyczną), który ma klasyfikować dane (4 klasy; w zasadzie są to 4 modele, każdy skupiający się na jednej z klas). Głównym problemów jest mała ilość próbek dla jednej z klas. Proste strategie under/over samplingu nie pomagają. Wygląda, że klas nie da się liniowo odseparować (załączony poglądowy obrazek dla 2 klas w ujęciu: FiczerA vs FiczerB, FiczerA vs FiczerC, FiczerC vs FiczerD itd., a sytuacja z pozostałymi wygląda podobnie).
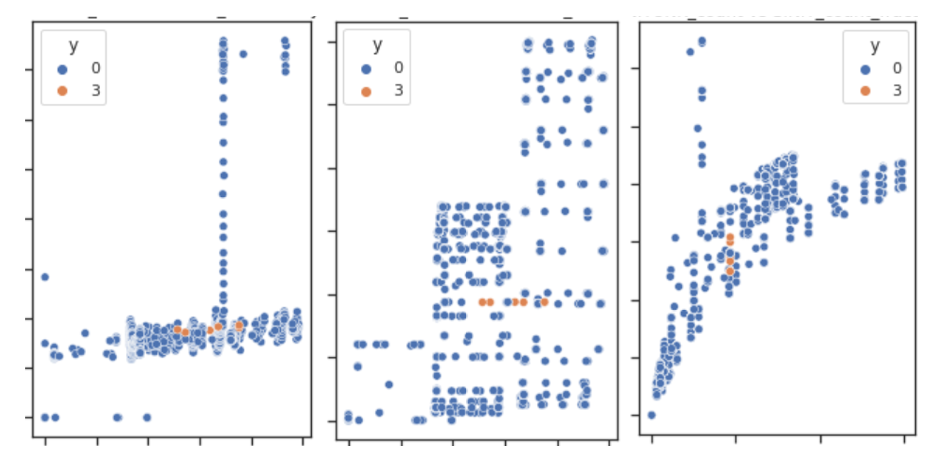
Można powiedzieć, "dobra nic się nie da zrobić", no ale może się da?
To czego próbowałem to zwiększenia ilości features w zbiorze danych i wprowadzenia prostych nieliniowych zależności (exp(-x^2), logx, x^2, x^3, ...) ale bez rezultatu (tu motywacja jest taka: z przestrzeni N wymiarowej przechodzimy do N+M wymiarowej i w tej N+M mamy separację liniową). Nadal nie widać czegoś co pozwalałoby odseparować te klasy liniowo.
To czego jeszcze nie próbowałem, to inne klasy nieliniowe, np. patrząc na 3-ią wizualizację, można by się zastanowić, a może by tak rozciągnąć przestrzeń w poziomie i ścisnąć w pionie?
Ale jak? Bo liniowo bez sensu ;) Wydaje mi się, że zachowanie takiego przekształcenia powinno zależeć od otoczenia punktu (coś w stylu punkty klasy y=0 się odpychają, z punkty klasy=3 się przyciągają).
Jak sobie radzicie z takim i problemami nieliniowej separacji klas? Czy są jakieś terminy statystyczne/teorio informacyjne/... , które pomogłyby wprowadzić takie dodatkowe features dla opisanego przypadku? Wiem, że mogę sobie inne modele popróbować, ale interesuje mnie to z perspektywy feature engineering w kontekście regresji logistycznej.