Witam,
chciałbym napisać skrypt w pythonie, który
-otworzy plik txt (raport ZUS przekonwertowany do pliku tekstowego)
-przeiteruje po każdej linii w poszukiwaniu danych osoby i okresów ubezpieczenia
-zapisze rekordy w json
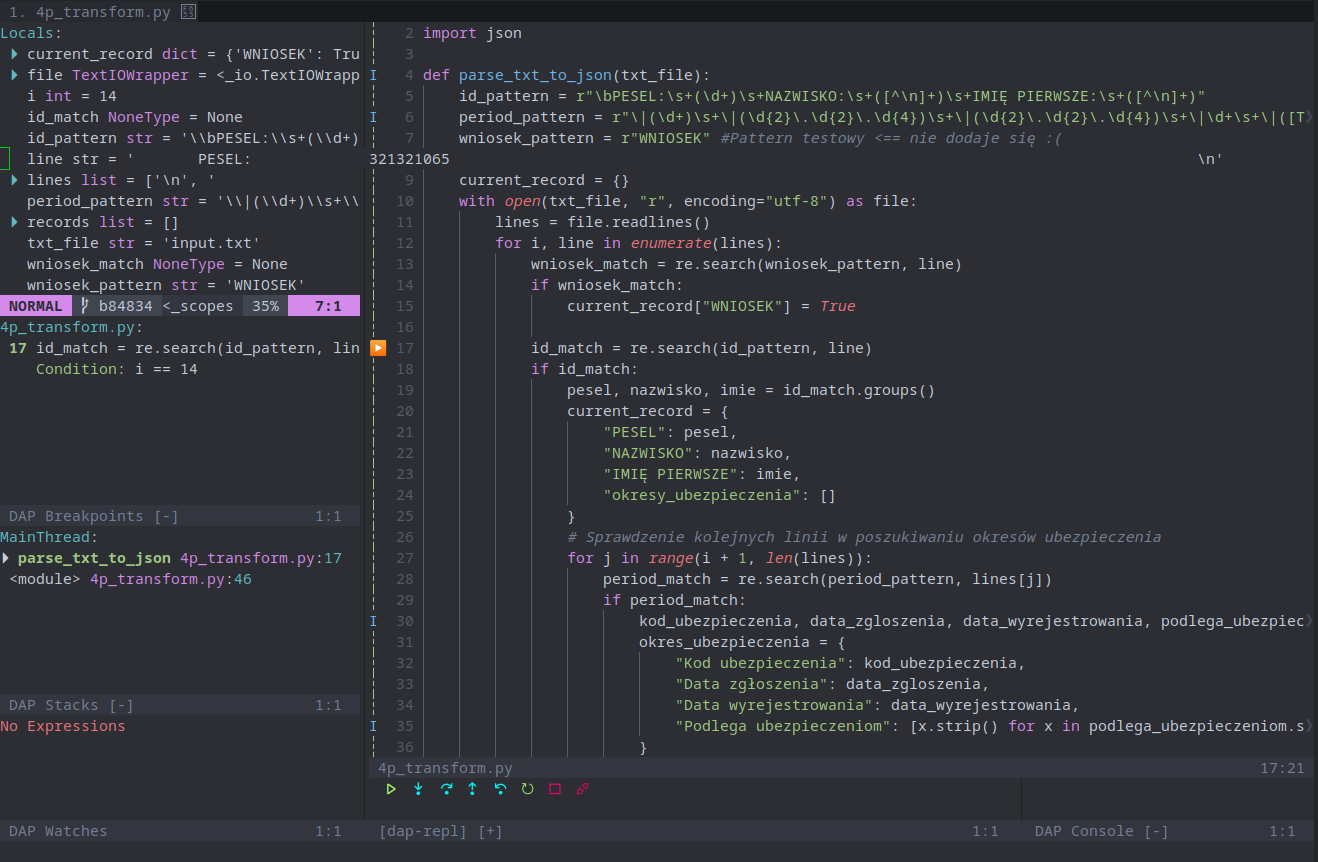
Próbowałem to zrobić na różne sposoby, cały czas kończy się na tym samym problemie.
Po odpaleniu skrypt, tworzy mi pusty plik. Do tej pory myślałem, że problem leży w regexach, ale to chyba nie to.
Poniżej jedna z prób, oraz input.
Nie oczekuję gotowych rozwiązań tylko podpowiedzi jak ten temat ugryźć. :)
import re
import json
def parse_txt_to_json(txt_file):
id_pattern = r"\bPESEL:\s+(\d+)\s+NAZWISKO:\s+([^\n]+)\s+IMIĘ PIERWSZE:\s+([^\n]+)"
period_pattern = r"\|(\d+)\s+\|(\d{2}\.\d{2}\.\d{4})\s+\|(\d{2}\.\d{2}\.\d{4})\s+\|\d+\s+\|([TAK\s\|]+)\|"
wniosek_pattern = r"WNIOSEK" #Pattern testowy <== nie dodaje się :(
records = []
current_record = {}
with open(txt_file, "r", encoding="utf-8") as file:
lines = file.readlines()
for i, line in enumerate(lines):
wniosek_match = re.search(wniosek_pattern, line)
if wniosek_match:
current_record["WNIOSEK"] = True
id_match = re.search(id_pattern, line)
if id_match:
pesel, nazwisko, imie = id_match.groups()
current_record = {
"PESEL": pesel,
"NAZWISKO": nazwisko,
"IMIĘ PIERWSZE": imie,
"okresy_ubezpieczenia": []
}
# Sprawdzenie kolejnych linii w poszukiwaniu okresów ubezpieczenia
for j in range(i + 1, len(lines)):
period_match = re.search(period_pattern, lines[j])
if period_match:
kod_ubezpieczenia, data_zgloszenia, data_wyrejestrowania, podlega_ubezpieczeniom = period_match.groups()
okres_ubezpieczenia = {
"Kod ubezpieczenia": kod_ubezpieczenia,
"Data zgłoszenia": data_zgloszenia,
"Data wyrejestrowania": data_wyrejestrowania,
"Podlega ubezpieczeniom": [x.strip() for x in podlega_ubezpieczeniom.split("|")]
}
current_record["okresy_ubezpieczenia"].append(okres_ubezpieczenia)
else:
break
records.append(current_record)
json_data = json.dumps(records, ensure_ascii=False, indent=2)
return json_data
plik_txt = "Baza_TEST_KOA.txt"
json_data = parse_txt_to_json(plik_txt)
with open("dane.json", "w", encoding="utf-8") as json_file:
json_file.write(json_data)
Input txt
WNIOSEK O UPORZĄDKOWANIE OKRESÓW PODLEGANIA UBEZPIECZENIOM
BEZPOŚREDNIO NA KONCIE UBEZPIECZONEGO
Dane identyfikacyjne płatnika:
NIP: RODO
REGON: RODO
NAZWA SKRÓCONA: RODO
Proszę o uporządkowanie okresów podlegania ubezpieczeniom społecznym i ubezpieczeniu zdrowotnemu na koncie
ubezpieczonego:
Dane identyfikacyjne ubezpieczonego:
PESEL: 321321065
NAZWISKO: Testowy
IMIĘ PIERWSZE: Adam
TYP oraz SERIA i NUMER dokumentu tożsamości:
Oświadczam, że ww. ubezpieczony podlegał ubezpieczeniom społecznym i/lub ubezpieczeniu zdrowotnemu zgodnie
z niżej wymienionymi danymi:
---------------------------------------------------------------------------------------------------------
|Kod tytułu |Data |Data |Kod przyczyny | Podlega ubezpieczeniom |
|ubezpiecz. |zgłoszenia |wyrej. od |wyrejestrow. | |
---------------------------------------------------------------------------------------------------------
Emer. | Rent. | Chor. | Wyp. | Zdr. |
-------------------------------------------------------
|091100 | 01.01.1999 | 14.03.2003 |100 | - | - | - | - | TAK |
|091100 | 11.08.2003 | 14.03.2005 |100 | - | - | - | - | TAK |
|091100 | 09.11.2005 | 03.04.2006 |100 | - | - | - | - | TAK |
|091100 | 03.10.2006 | 11.10.2006 |600 | - | - | - | - | TAK |
|091000 | 11.10.2006 | 16.10.2006 |100 | TAK | TAK | - | - | TAK |
|091000 | 03.04.2007 | 10.09.2007 |100 | TAK | TAK | - | - | TAK |
|091100 | 25.02.2008 | 03.07.2008 |100 | - | - | - | - | TAK |
|091100 | 02.07.2009 | 28.10.2009 |600 | - | - | - | - | TAK |
|091101 | 28.10.2009 | 10.11.2009 |100 | - | - | - | - | TAK |
|091101 | 21.12.2009 | 02.05.2011 |100 | - | - | - | - | TAK |
|091101 | 06.09.2011 | 13.12.2011 |100 | - | - | - | - | TAK |
|091101 | 17.04.2013 | 10.05.2013 |100 | - | - | - | - | TAK |
|091101 | 20.12.2013 | 05.02.2014 |100 | - | - | - | - | TAK |
----------------------------------------------------------------------------------------------------------
Podpis płatnika lub osoby upoważnionej
............................. 13.07.2023
....................