w kontekście dekodowania ich
czy chodzi tylko o parallelizowalność?
w kontekście dekodowania ich
czy chodzi tylko o parallelizowalność?
to niepotrzebne marnowanie krzemu, zwiększanie poboru prądu i skomplikowania dekodera (bardziej skomplikowany układ = więcej okazji do zrobienia błędów)
Np. nie możesz tego wygodnie zrównoleglić? Jak masz instrukcje stałej długości to możesz na ślepo pociąć je na kawałki i dekodować równolegle.Jak masz instrukcje różnej długości to się tak nie da, bo nie wiesz gdzie będzie kolejna instrukcja zanim nie sparsujesz poprzedniej.
da się zrównoleglić. od dawna dekodery dekodują po kilka instrukcji x86 naraz. mimo wszystko inwestowanie w skomplikowane dekodery oznacza, że mniej zainwestujemy w inne części procesora.
w jakby użyć heurystyk i mielić do przodu zakładając że np. next instrukcja ma długość X i jeżeli faktycznie tak będzie, to mamy policzone do przodu
mimo wszystko inwestowanie w skomplikowane dekodery oznacza, że mniej zainwestujemy w inne części procesora.
co masz na myśli? man hours?
co masz na myśli?
wszystko. robocizna, łatanie błędów, grzanie się układu, zwiększony koszt wytwarzania, itd
skomplikowany dekoder to też większe wewnętrze opóźnienia, widoczne np. przy źle przewidzianych skokach
https://www.anandtech.com/show/16881/a-deep-dive-into-intels-alder-lake-microarchitectures/3
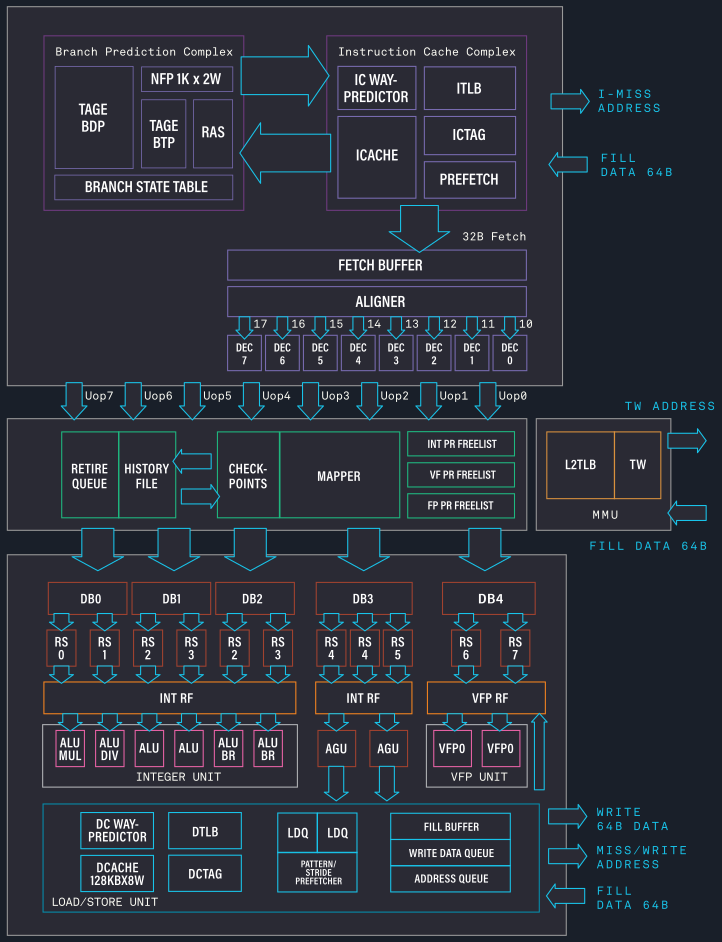
Starting off with the directly most obvious change: Intel is moving from being a 4-wide decode machine to being a 6-wide microarchitecture, a first amongst x86 designs, and a major design focus point. Over the last few years there had been a discussion point about decoder widths and the nature of x86’s variable length instruction set, making it difficult to design decoders that would go wider, compared to say a fixed instruction set ISA like Arm’s, where adding decoders is relatively easier to do. Notably last year AMD’s Mike Clarke had noted while it’s not a fundamental limitation, going for decoders larger than 4 instructions can create practical drawbacks, as the added complexity, and most importantly, added pipeline stages. For Golden Cove, Intel has decided to push forward with these changes, and a compromise that had to be made is that the design now adds an additional stage to the mispredict penalty of the microarchitecture, so the best-case would go up from 16 cycles to 17 cycles. We asked if there was still a kind of special-case decoder layout as in previous generations (such as the 1 complex + 3 simple decoder setup), however the company wouldn’t dwell deeper into the details at this point in time. To feed the decoder, the fetch bandwidth going into it has been doubled from 16 bytes per cycle to 32 bytes per cycle.
Intel states that the decoder is clock-gated 80% of the time, instead relying on the µOP cache. This has also seen extremely large changes this generation: first of all, the structure has now almost doubled from 2.25K entries to 4K entries, mimicking a similar large increase we had seen with the move from AMD’s Zen to Zen2, increasing the hit-rate and further avoiding going the route of the more costly decoders.
Intel states that the decoder is clock-gated 80% of the time, instead relying on the µOP cache. - to jest bardzo ważny mechanizm, bo bez niego dekoder zżerałby znacznie więcej prądu.
coś nt. tego kosztu prądowego
https://www.usenix.org/system/files/conference/cooldc16/cooldc16-paper-hirki.pdf
It has been a common myth that x86-64 processors
suffer in terms of energy efficiency because of their com-
plex instruction set. In this paper, we aim to investigate
whether this myth holds true, and determine the power
consumption of the instruction decoders of an x86-64
processor. To that end, we design a set of microbench-
marks that specifically trigger the instruction decoders by
exceeding the capacity of the decoded instruction cache.
We measure the power consumption of the processor
package using a hardware-level energy metering model
called the Running Average Power Limit (RAPL), which
is supported in the latest Intel architectures. We leverage
linear regression modeling to break down the power con-
sumption of each processor component, including the in-
struction decoders. Through a comprehensive set of ex-
periments, we demonstrate that the instruction decoders
can consume between 3% and 10% of the package power
when the capacity of the decoded instruction cache is ex-
ceeded. Overall, this is a somewhat limited amount of
power compared with the other components in the pro-
cessor core, e.g., the L2 cache. We hope our finding can
shed light on the future optimization of processor archi-
tectures.
Our core idea is to design microbench-
marks that exhaust the micro-op cache, thus trigger-
ing the instruction decoders. This allows us to specifi-
cally measure the power consumed by the instruction de-
coders.
super, że intelowi udało się okiełznać pobór prądu
https://www.usenix.org/system/files/conference/cooldc16/cooldc16-paper-hirki.pdf
| Microbenchmark: | #1 | #2 |
|---|---|---|
| Type: Floating-point Integer | ||
| Instructions per cycle: | 1.67 | 3.86 |
| Uncore (W): | 6.0 | 6.0 |
| Cores (W): | 22.1 | 22.1 |
| Execution units (W): | 4.9 | 10.4 |
| Instruction decoders (W): | 1.8 | 4.8 |
| L1 cache (W): | 4.8 | 3.8 |
| L2 & L3 cache (W): | 11.2 | 0.1 |
| Micro-op cache hit ratio: | 44.8% | 29.6% |
hmm, z jakiegoś powodu nie zeszli z micro-op cache hit ratio do 0%, więc w zasadzie nie wyizolowali dokładnie wpływu dekodera
trzeba wziąć kilka rzeczy pod uwagę:
Shalom napisał(a):
Np. nie możesz tego wygodnie zrównoleglić? Jak masz instrukcje stałej długości to możesz na ślepo pociąć je na kawałki i dekodować równolegle. Jak masz instrukcje różnej długości to się tak nie da, bo nie wiesz gdzie będzie kolejna instrukcja zanim nie sparsujesz poprzedniej.
@Shalom: Ale parsowanie to jeszcze nie wykonywanie. Podziałem kodu na poszczególne instrukcje może się zajmować osobny dekoder, który nic innego nie potrafi jak stawiać kreski na granicach instrukcyj. No ale to "marnowanie krzemu" – w skali procesora chyba niewielkie.
Problemem jest też trwające wiele lat kombinowanie w x86 gdzie by tu umieścić kolejny zestaw SSE, XOP czy AVX, przez co dekodowanie stało się zadaniem mega skomplikowanym. Czasami można tę samą operację zakodować na kilka sposobów, co może mieć znaczenie: niektóre instrukcje mają subtelnie różne działanie w zależności od tego czy są zakodowane wg. schematu VEX, czy „po staremu”..
No i na pewno nie pomaga fakt, że procesor x86 potrzebuje obsłużyć trzy wersje architektury: 16, 32 i 64-bitową.
Azarien napisał(a):
stawiać kreski na granicach instrukcyj. No ale to "marnowanie krzemu" – w skali procesora chyba niewielkie.
to już było
https://www.agner.org/optimize/microarchitecture.pdf
dotyczy https://en.wikipedia.org/wiki/AMD_K8 i amd k10
Predecoding and instruction length decoding
An instruction can have any length from 1 to 15 bytes. The instruction boundaries are
marked in the code cache and copied into the level-2 cache. Instruction length decoding is
therefore rarely a bottleneck, even though the instruction length decoder can handle only
one instruction per clock cycle.
The level-1 code cache contains a considerable amount of predecode information. This
includes information about where each instruction ends, where the opcode byte is, as well
as distinctions between single, double and vector path instructions and identification of
jumps and calls. Some of this information is copied to the level-2 cache, but not all. The low
bandwidth for instructions coming from the level-2 cache may be due to the process of
adding more predecode information.
nowoczesną alternatywą jest https://en.wikipedia.org/wiki/CPU_cache#Micro-operation_(%CE%BCop_or_uop)_cache
https://chipsandcheese.com/2021/07/13/arm-or-x86-isa-doesnt-matter/
IC: You’ve spoken about CPU instruction sets in the past, and one of the biggest requests for this interview I got was around your opinion about CPU instruction sets. Specifically questions came in about how we should deal with fundamental limits on them, how we pivot to better ones, and what your skin in the game is in terms of ARM versus x86 versus RISC V. I think at one point, you said most compute happens on a couple of dozen op-codes. Am I remembering that correctly?
JK: [Arguing about instruction sets] is a very sad story. It's not even a couple of dozen [op-codes] - 80% of core execution is only six instructions - you know, load, store, add, subtract, compare and branch. With those you have pretty much covered it. If you're writing in Perl or something, maybe call and return are more important than compare and branch. But instruction sets only matter a little bit - you can lose 10%, or 20%, [of performance] because you're missing instructions.
For a while we thought variable-length instructions were really hard to decode. But we keep figuring out how to do that. You basically predict where all the instructions are in tables, and once you have good predictors, you can predict that stuff well enough. So fixed-length instructions seem really nice when you're building little baby computers, but if you're building a really big computer, to predict or to figure out where all the instructions are, it isn't dominating the die. So it doesn't matter that much.
(...)
Now the new predictors are really good at that. They're big - two predictors are way bigger than the adder. That's where you get into the CPU versus GPU (or AI engine) debate. The GPU guys will say ‘look there's no branch predictor because we do everything in parallel’. So the chip has way more adders and subtractors, and that's true if that's the problem you have. But they're crap at running C programs.
(...)
The main findings from our study are:
– Large performance gaps exist across implementations, although average cycle count gaps are <= 2.5x.
– Instruction count and mix are ISA-independent to the first order.
– Performance differences are generated by ISA-independent microarchitectural differences.
– The energy consumption is again ISA-independent.
– ISA differences have implementation implications, but modern microarchitecture techniques render them moot; one ISA is not fundamentally more efficient.
– ARM and x86 implementations are simply design points optimized for different performance levels
@WeiXiao: gdzie tam jest mowa o zajętości krzemu przez dekodery czy o zwiększonych opóźnieniach spowodowanych przez (stosunkowo) dużą liczbę dekoderów instrukcji zmiennej długości? to ważne sprawy. z tego co zacytowałeś widzę tylko it isn't dominating the die - nie nastraja to specjalnie optymistycznie.
właśnie natknąłem się na ciekawy artykuł:
https://wccftech.com/intel-x86s-paves-way-for-64-bit-only-architectures-removing-legacy-modes-simplifying-design/ prowadzący do https://www.intel.com/content/www/us/en/developer/articles/technical/envisioning-future-simplified-architecture.html
intel szkicuje projekt uproszczenia x86, tzn. usunięcia trybów 16- i 32-bitowych całkowicie. nie wygląda to na uproszczenie zestawu instrukcji 64-bitowych, ale skoro odpadają instrukcje z trybów 16- i 32-bitowych to pewnie dekoder się co nieco uprości tak czy siak.
Bardziej tutaj chodziło o zmierzenie się z powszechną opinią jako to ARM (ISA) samo w sobie oferuje lepszą wydajność ze względu na brak narzutu dekodera
WeiXiao napisał(a):
Bardziej tutaj chodziło o zmierzenie się z powszechną opinią jako to ARM (ISA) samo w sobie oferuje lepszą wydajność ze względu na brak narzutu dekodera
hmm, no to skonfrontuj to:
The main findings from our study are:
– Instruction count and mix are ISA-independent to the first order.
z tym, że apple w swoich prockach ma znacznie więcej dekoderów niż intel. apple od dekady jest o 2-3 dekodery do przodu względem intela. wydajność na takt jest najwyższa u apple'a - przynajmniej w skalarnym kodzie, bo intel ma szerokie jednostki wektorowe. intel za to ma znacznie wyższe taktowania, więc ostatecznie wydajność bezwzględna jest podobna.
nawet procek od jima kellera planowany na chyba 2025 rok ma 8 dekoderów:
https://tenstorrent.com/risc-v/
zobaczymy jak wypadnie w porównaniu z prockami intela, amd i apple. apple trzyma zegary nisko, intel i amd żyłują wysoko ile się da w limicie energetycznym.
ogólnie cały problem jest podobny do szklanki wody - jest do połowy pełna czy do połowy pusta? praktyka wskazuje, że dekodowanie x86 jest trudniejsze niż dekodowanie arma, ale intel staje na głowie, żeby polepszyć swoje dekodery i nie zwiększyć przepaści do topowych risców (czyli aktualnie apple'a). można to interpretować jako słabość x86, albo siłę intela. jak kto woli.
p.s.
samo dokładanie dekoderów, jednostek wykonawczych, cache'u itp itd niekoniecznie satysfakcjonująco zwiększa wydajność, jeśli mamy jakieś wąskie gardła ograniczające wydajność. samsung tworzył swój procek armowy (mongoose), który był bardzo rozbudowany i wydajny na papierze, ale w praktyce był prądożerny i mało wydajny.
To też nie problem w przypadku samego procesora, przy statycznej analizie często też nie idzie znaleźć pewnych funkcji, bo mogą być przesunięte o bajta i cały kod dezasemblowany będzie bez sensu.
Five stage pipeline robi tak, że pierwsza instrukcja przy clocku, rozkodowuje pierwszą i przy następnym clocku robi następną.
Jeśli były by wszystkie równej długości instrukcje, to każda by miała minimum 10 bajtów, gdyż jest więcej niż 255 instrukcji i adresacja 64bit, czyli 8 bajtów, to średnio powinno być te 10 bajtów na instrukcję.
Ale plusy powinny być takie, że moglibyśmy np. 1-5 instrukcji do przodu na raz wykonywać i jeśli by nie miały jakichś wcześniejszych zależności zależnych od poprzednich tych 5 instrukcjach to teoretycznie można by było je wykonać, ale wcześniejsze instrukcje nie mogły by zależeć od innych wykonywanych w tym batchu, ale już modyfikacje mogły by być wykonywane gdyż dopiero następny clock sprawi, że flip flopy zapiszą wartości, a prąd będzie już tam dochodził wcześniej, ale następny clock dopiero zapisze tą wartość.
Jedyna korzyść to jak będzie 5 instrukcji, które modyfikują rejestry, których inne nie wykorzystują to wtedy będzie wykonane 5 instrukcji w jednym clocku, tak mi się wydaje żadnego zysku w wydajności nie będzie.
Chodź 5 stage pipeline wykonuje optymalizacje na poziomie mikroinstrucji, to wie kiedy jest przełączenie flip flopów i dopóki nie dojdzie do tego momentu, to wczytanie i zdekodowanie może być wykonane, a reszta operacji jest zamrożona do czasu spełnienia zależności.
Z tymi flip flopami jest ciekawie, bo robimy dodawanie +1 i teraz mamy rejestr z flip flopów, który ma wartość 0001 i teraz do zapisu dochodzi prąd z wartością 0010, ale dopiero przy następnym ticku zegara zostanie zapisana ta wartość, ale obliczona jest do przodu, hardware tak wszystko step ahead wykonuje.
Tak na chłopski rozum to jak różnica w układaniu Tetrisa za pomocą jednego klocka vs za pomocą wielu różnych. Zawsze znajdzie się jakieś nieoptymalne wykorzystanie zasobów.
arm pozbywa się macro-op cache (hmm, u intela to jest nazwane micro-op cache, nie wiem skąd inna nazwa), czyli pamięci podręcznej dla zdekodowanych instrukcji:
https://fuse.wikichip.org/news/7531/arm-introduces-the-cortex-x4-its-newest-flagship-performance-core/
Front-End
Arm says that the front-end of the Cortex-X4 has seen some significant changes. The instruction fetch delivery has been completely redesigned. As with the Cortex-A715, it seems that the Cortex-X followed suit and also dropped the macro-operations cache entirely. Instead, the Cortex-X4 widened the pipeline to support up to 10 instructions. The instruction cache was also enhanced accordingly. With a bandwidth increasing to 10 instructions per cycle.
dekodowanie 64-bitowych instrukcji armowych jest tak tanie, że aż tańsze niż trzymanie pamięci podręcznej dla zdekodowanych instrukcji i to zarówno pod względem rozmiaru jak i prądożerności.
(obsługa trybu 32-bitowego jest porzucona w nowych wysokowydajnych rdzeniach od arma)
