Mam sobie taki edytorek, do którego dodałem linkowanie. Potem przerabiam go na web component, który pod spodem jest komponentem Vue.
Muszę z linka wydobyć atrybuty, żeby przekazać do komponentu, więc zrobiłem to regexem:
const href = link.match(/(?<=href=").+?(?=")/g)
const title = link.match(/(?<=title=").+?(?=")/g)
const content = link.match(/(?<=>).+?(?=<\/a>)/g)
const webComponent = `<web-component-base-link to="${href}" title="${title}">${content}</web-component-base-link>`
Wszystko spoko, ale oczywiście okazało się, że na IE naszych czasów tj. Srafari lookbehind nie jest wspierany https://caniuse.com/js-regexp-lookbehind
Czy da się jakoś inaczej regexem wyciągnąć te atrybuty?
Proszę o pomoc i serdecznie dziękuję.
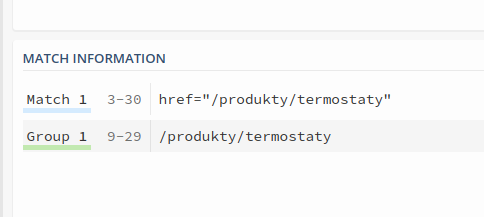
 :
: