Cześć,
Tytuł wątku może trochę pokręcony - już spieszę wyjaśnić w czym potrzebuję porady.
Założenia aplikacji są takie:
- Aplikacja, to taki "core" spinający w logiczną całość mikroserwisy odpowiadające za API do user'a (test logger), zapis do bazy i kolejkowanie message'y w razie potrzeby.
- Każdy z naszych zespołów testerskich, może dopisać swój API endpoint i backend wzorując się na ogólnym templat'e i podpiąć się łatwo i szybko do tego "core".
- Może zajść potrzeba skalowania różnych elementów (API, workerów zapisujących do bazy).
- Niby standard, przyznam jednak, że mając małe doświadczenie z takim uniwersalnym dla wszystkich API i chcąc zabezpieczyć się kolejką na wypadek dużego trafficu, przydałoby się móc skalować np. API albo workery w zależności od obciążenia.
Zastanawiam się nad taką "architekturą" składającą się upraszczając z 3-ech głównych punktów:
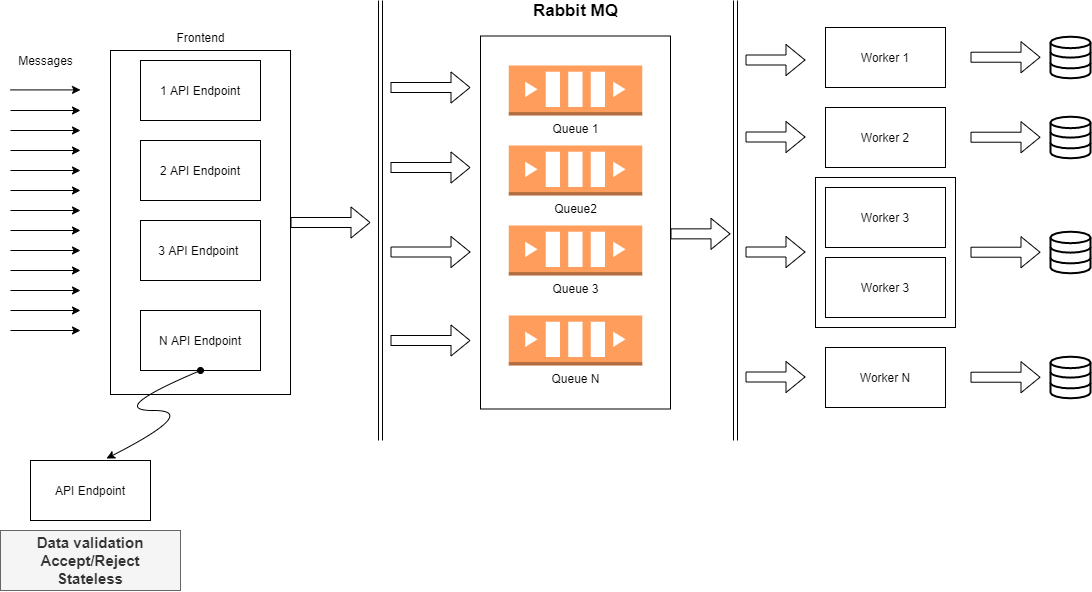
pt. 1. Frontend
Zajmujący się HTTP API, walidacją danych i przesyłaniem do kolejki. Chodzi mi po głowie zastosowanie na przykład: https://fastapi.tiangolo.com ale to jest chyba drugorzędna sprawa tutaj.
pt. 2. Kolejka / Message Broker:
Myślałem o zastosowaniu RabbitMQ. Każdy API endpoint będzie mógł mieć 1 (albo więcej) kolejkę, do której tylko wrzuca dane. Po wrzuceniu message'a do kolejki frontend ma wolne, a RabbitMQ współpracuje już tylko z workerem pt. 3.
Nie chce mi się pisać kolejkowania od zera, a RabbitMQ wydaje się prosty w obsłudze, skalowalny i ma nawet ładny dashboard.
pt. 3. Worker:
Czyli obsługujący konkretną kolejkę w RabbitMQ i wrzucający dane do "swojej" bazy danych. To jedyne zadania tej części.
Zalety tego rozwiązania jakie mi się nasuwają:
- skalowalność frontendów, które są bezstanowe - to tylko przekaźniki i cenzorzy :)
- skalowalnośc workerów - zależnie od trafficu, można zwiększać ich ilość per kolejka
- mniejsza ilość połączeń do bazy? 1 conncection/worker
Minusy:
- pada jeden element (environment fault, bug, etc.) to message giną w akcji...
- trochę to rozwlekłe, zastanawiam się czy zwykłe REST API by nie wystarczyło bez żadnych kolejek itp.
Pytania:
- krytyka mile widziana
- czy RabbitMQ ma tutaj jakieś zalety? Czy prościej, napisać zwykłą kolejkę np. w Javie, Pythonie i obsługiwać ja tymi workerami?
- czy w ten sposób niweluję delikatnie wąskie gardło jakim może być zapis do bazy danych (mam na myśli możliwość kolejkowania dużego trafficu)?