Jeju... Jak to czytam to mam wrażenie że nikt nie wie o czym pisze. X86 to CISC - czyli długie rozkazy, których jest od groma do wszystkiego. Tysiące opcodow. Rozkaz może trwać kilka cykli zegara jak złożona funkcja i powstaje nawet maszynowo implementowany mikrokod do tworzenia takich instrukcji. Pamięć nie jest za to bardzo obciążana. RISC to krótkie instrukcje mieszczące się w słowie maszynowym (64b) i przetworzenie ich zajmuje 1 cykl zegara. Tutaj jest nastawienie na optymalizacje przez kompilatory w postaci używania krótkich instrukcji. Zużycie ramu jest większe. ARM to skrót od Advanced RISC Machine. Czyli ARM to RISC. Przez to ze mniej implementuje - raptem garść jednocyklowych rozkazów jest prostszy w konstrukcji i zużywa mniej energi.
To brzmi jak jakieś mity i legendy. ARM ISA to garść jednocyklowych rozkazów? Hmm, popatrzmy co Arm Armv9-A A64 Instruction Set Architecture nam oferuje: https://developer.arm.com/documentation/ddi0602/latest . Ja tam widzę masę instrukcji (chyba setki, jeśli połączyć wszystkie ich rodzaje), włącznie z dzieleniem i to nawet wektorowym dzieleniem liczb całkowitych (o ile dobrze rozumiem). Nawet x86 tego nie ma. Jeśli to jest "garść jednocyklowych rozkazów" to szacun dla Arma.
https://developer.arm.com/documentation/ddi0602/latest/SVE-Instructions/UDIV--Unsigned-divide--predicated--?lang=en
https://developer.arm.com/documentation/ddi0602/latest/SVE-Instructions/SDIV--Signed-divide--predicated--?lang=en
Obecnie główne różnice między ARM, a x86 to nie liczba instrukcji (w obu architekturach jest masa instrukcji), a raczej kodowanie instrukcji (x86 ma skomplikowane kodowanie ze względów historycznych) czy model pamięci (x86 ma silniejsze gwarancje dotyczące widoczności modyfikacji pamięci, ARM potrzebuje większej liczby memory barriers).
O ile dobrze zrozumiałem artykuły o ARMie to Scalable Vector Extension (SVE) ma swoje korzenie w superkomputerach. Fujitsu produkuje superkomputery, które do niedawna były oparte o architekturę SPARC (od Suna, a później Oracle), dla której Fujitsu rozwijało rozszerzenia wektorowe. Niedawno Oracle zarzuciło całkowicie rozwój SPARCa i Fujitsu przeniosło się na ARMa, przenosząc przy okazji swoje mechanizmy obliczeń wektorowych. Dokładniej rzecz biorąc to SVE nie jest własnościowym rozszerzeniem Fujitsu tylko zostało we współpracy z Armem włączone do standardowej ARM ISA.
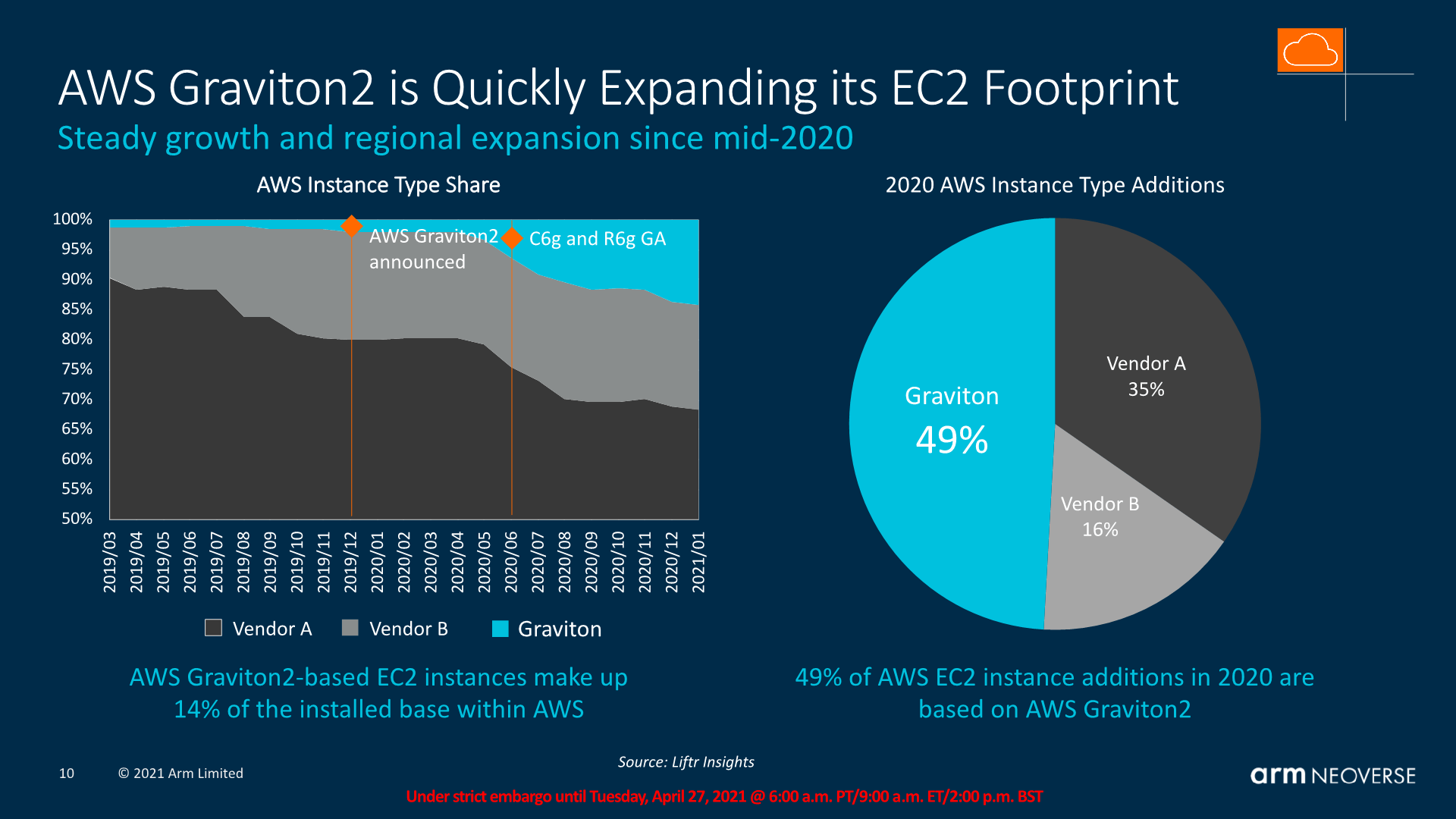
Co do ARMów w serwerowniach/ chmurach obliczeniowych, to sztandarowym przykładem sukcesu jest AWS Graviton:
Z innych ciekawostek, to procki ARMowe też mają dekodery instrukcji i tłumaczą z RISC na RISC. Cortex-A77 i późniejsze (obok pamięci podręcznej dla niezdekodowanych instrukcji) mają pamięć podręczną dla zdekodowanych instrukcji (micro-op cache, analogicznie jak w x86). Procki ARMowe potrafią nawet kompresować instrukcje, by zwiększyć efektywną pojemność wewnętrznych buforów procesora:
https://www.anandtech.com/show/16693/arm-announces-mobile-armv9-cpu-microarchitectures-cortexx2-cortexa710-cortexa510/2
The core also increases its out-of-order capabilities, increasing the ROB (reorder buffer) by 30% from 224 entries to 288 entries this generation. The effective figure is actually a little bit higher still, as in cases of compression and instruction bundling there are essentially more than 288 entries being stored. Arm says there’s also more instruction fusion cases being facilitated this generation.
(notabene: Intel Skylake ma ROB o rozmiarze 224, a u Apple M1 pojemność ROB to podobno ponad 600)
