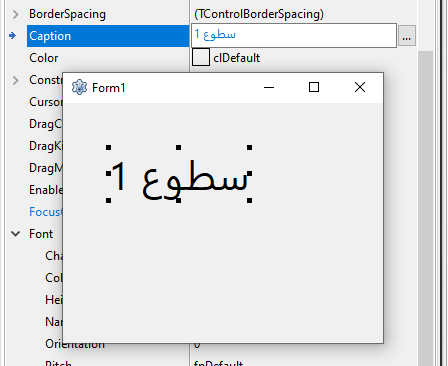
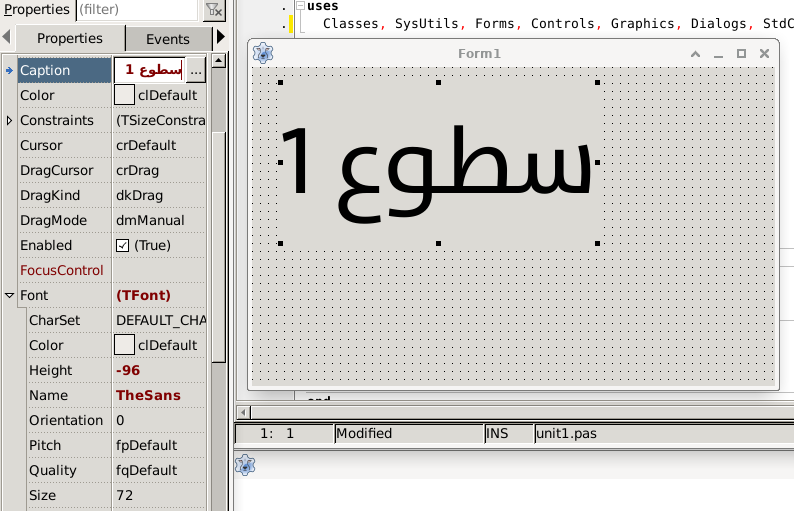
Próbuje wyświetlić tekst : "سطوع 1"
w aplikacji napisanej w Lazarus
powinno to wyglada tak:

A wyglada tak:

https://arbfonts.com/the-sans-plain-3-font-download.html?preview=%D8%B3%D8%B7%D9%88%D8%B9+1
W słowie arabskim ostatnia litera po prawej ma ciekawą właściwość
w zależności gdzie jest w słowie to wygląda inaczej


Jak ta funkcja się nazywa ze znak może różnie wyglądać i czy można to jakoś włączyć w lazarus aby poprawnie wyświetlał teksty arabskie ?
Bo z tego co widzę ze lazarus jest zafiksowany i wyświetla literę w jeden sposób niezalezienie gdzie jest w słowie