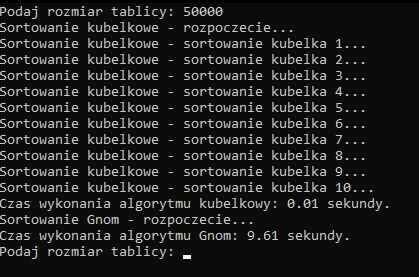
Cześć, przychodzę z problemem, mam zrobić projekt mający porównać dwa typy sortowania: Kubełkowe i Gnoma. program generuje dwie losowe tablice, chodzi mi o tablicę z dużą ilością elementów np. 100000 200000, później przekazuje je dla odpowiednich algorytmów, sortuje wypisuje do plików tekstowych i pokazuje czas wykonania dla obu algorytmów. Niestety czas dla algorytmu kubełkowego jest niepoprawny? Czy wie ktoś gdzie lezy temu przyczyna?
#include <iostream>
#include <fstream>
#include <vector>
#include <chrono>
#include <cstdlib>
#include <ctime>
#include <iomanip>
#include <algorithm>
using namespace std;
void saveArrayToFile(const vector<int>& arr, const string& filename) {
ofstream file(filename);
if (file.is_open()) {
for (int num : arr) {
file << num << " ";
}
file.close();
} else {
cerr << "Unable to open file: " << filename << endl;
}
}
void saveDurationToFile(double duration, const string& filename) {
ofstream file(filename, ios::app);
if (file.is_open()) {
file << fixed << setprecision(2) << duration << " seconds\n";
file.close();
} else {
cerr << "Unable to open file: " << filename << endl;
}
}
void printElapsedTime(const string& algorithm, const chrono::high_resolution_clock::time_point& start, const chrono::high_resolution_clock::time_point& end) {
auto duration = chrono::duration_cast<chrono::microseconds>(end - start);
cout << "Czas wykonania algorytmu " << algorithm << ": " << fixed << setprecision(2) << duration.count() / 1000000.0 << " sekundy.\n";
}
void generateRandomArray(vector<int>& arr, int size, unsigned int seed) {
srand(seed);
for (int i = 0; i < size; ++i) {
int randomNum = rand() % 1000; // Zakres od 0 do 999
arr.push_back(randomNum);
}
}
// Algorytm kubełkowy
void SortowanieKubelkowe(vector<int>& tab, int liczbaKubelkow) {
// Znajdź wartość maksymalną w tablicy
int maxVal = *max_element(tab.begin(), tab.end());
// Utwórz kubełki
vector<vector<int>> kubele(liczbaKubelkow);
// Rozdziel elementy do kubełków
for (int i = 0; i < tab.size(); ++i) {
int index = (int)((double)liczbaKubelkow * tab[i] / (maxVal + 1));
kubele[index].push_back(tab[i]);
}
// Sortuj każdy kubełek
for (int i = 0; i < liczbaKubelkow; ++i) {
cout << "Sortowanie kubełkowe - sortowanie kubełka " << i + 1 << "...\n";
sort(kubele[i].begin(), kubele[i].end());
}
// Sklej kubełki w posortowaną tablicę
int index = 0;
for (int i = 0; i < liczbaKubelkow; ++i) {
for (int j = 0; j < kubele[i].size(); ++j) {
tab[index++] = kubele[i][j];
}
}
}
// Algorytm Gnom
void SortGnom(vector<int>& tab) {
const int n = tab.size();
int index = 0;
while (index < n) {
if (index == 0 || tab[index] >= tab[index - 1]) {
index++;
} else {
swap(tab[index], tab[index - 1]);
index--;
}
}
}
int main() {
const int liczba_testow = 5; // liczba testów
const int liczbaKubelkow = 10; // liczba kubełków w algorytmie kubełkowym
for (int test = 0; test < liczba_testow; ++test) {
int n;
cout << "Podaj rozmiar tablicy: ";
cin >> n;
vector<int> A, B;
// Generowanie dwóch różnych pseudolosowych tablic
unsigned int seedA = static_cast<unsigned int>(time(0) + test); // Ziarno dla tablicy A
generateRandomArray(A, n, seedA);
unsigned int seedB = static_cast<unsigned int>(time(0) + 1 + test); // Ziarno dla tablicy B
generateRandomArray(B, n, seedB);
// Zapis tablic do plików wejściowych
saveArrayToFile(A, "input_kubelkowe.txt");
saveArrayToFile(B, "input_gnoma.txt");
// Pomiar czasu dla algorytmu kubełkowego
auto start1 = chrono::high_resolution_clock::now();
cout << "Sortowanie kubełkowe - rozpoczęcie...\n";
SortowanieKubelkowe(A, liczbaKubelkow);
auto end1 = chrono::high_resolution_clock::now();
printElapsedTime("kubełkowy", start1, end1);
// Zapis wyników sortowania i czasu do pliku output_kubelkowe.txt
saveArrayToFile(A, "output_kubelkowe.txt");
saveDurationToFile(chrono::duration_cast<chrono::microseconds>(end1 - start1).count() / 1000000.0, "output_kubelkowe.txt");
// Pomiar czasu dla algorytmu Gnom
auto start2 = chrono::high_resolution_clock::now();
cout << "Sortowanie Gnom - rozpoczęcie...\n";
SortGnom(B);
auto end2 = chrono::high_resolution_clock::now();
printElapsedTime("Gnom", start2, end2);
// Zapis wyników sortowania i czasu do pliku output_gnoma.txt
saveArrayToFile(B, "output_gnoma.txt");
saveDurationToFile(chrono::duration_cast<chrono::microseconds>(end2 - start2).count() / 1000000.0, "output_gnoma.txt");
}
return 0;
}
Jeśli ktoś by miał pytanie to chętnie udziele, dzięki