Bardziej mi zależy no obliczaniu tej wartości co zapytanie
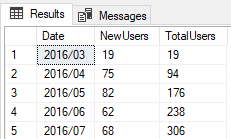
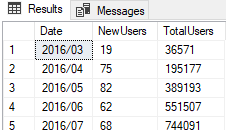
Pytanie jeszcze, czy chcesz to mieć w taki sposób przedstawione, jak podałeś wyżej - czyli dla każdego miesiąca liczbę nowych plus całkowitą?
Jeśli tak, to chyba najprościej będzie nie robić jednego zapytania, które by to ogarnęło (co pewnie jest do zrobienia, ale na szybko nie przychodzi mi żadne rozwiązanie do głowy) co zrobienie w pętli serii zapytań - każde obliczające wartość nowych userów dla jednego okresu. Zauważ, że liczba całkowita jest po prostu zwykłą sumą poprzedniej liczby wszystkich oraz nowych w danym okresie.
Bierzesz od początku historii - pierwszy miesiąc, podliczasz ilu userów w tym okresie się przyłączyło. Potem wypluwasz na ekran wartości total oraz new, które w pierwszym okresie oczywiście będą takie same. Następnie obliczasz liczbę nowych userów w kolejnym okresie i ponownie - wypluwasz wartość nowych, a potem sumujesz wartość nowych z total z poprzedniego okresu i w ten sposób masz całkowitą liczbę. Następnie liczysz kolejny okres i znowu, poprzez zwiększenie wartości **total **z poprzedniego etapu o liczbę nowych w bieżącym okresie, masz wartość wszystkich userów.
Tylko zauważ, że to rozwiązanie jest obciążające dla bazy. Nawet jakby to zrobić tak, jak napisał @BlackBad to za każdym razem baza musi to obliczyć. Przy niewielkiej bazie to nie jest większy problem, ale jeśli historia będzie sięgać wielu miesięcy czy lat wstecz, userów będą tysiące, a samo wyświetlanie historii będzie odpalane w miarę często, to niepotrzebnie będziesz dowalać bazie niepotrzebne obliczenia.
Trzymanie raz wyliczonych wyników cząstkowych jest o wiele lepszą opcją. Zresztą ten problem jest bardzo podobny do tego wątku - Saldo użytkowników na własnej stronie baza danych MySQL. Tam także powinno się pewne dane raz wyliczyć i zachować, a nie obliczać za każdym razem od nowa.