Witam wszystkich.
Zmieniłem pracę i na nowym stanowisku mam do czynienia z MSSQL. Do tej pory wystarczało robienie mniej lub bardziej prostych zapytań.
Ale powoli zwiększa mi się zakres i do moich obowiązków doszło tworzenie raportów. Te które wymagają SELECT który wyświetli żądane dane nie są wielkim problemem. Ale trafił mi się do wykonania raport wymagający utworzenia procedury zawierającej tworzenie tabel tymczasowych i pętli. Pętle są dla mnie nowym zagadnieniem i robiąc ten raport na bieżąco się uczę, ale nie wiem jak podejść do problemu który mam i liczę na jakieś wskazówki, tudzież podpowiedzi z waszej strony. Proszę też o wyrozumiałość jeśli rozwiązanie jest banalne, a mimo wszystko nie wpadłem na nie.
A więc tak. Z tego co wiem od administratorów to całość działa na MS SQL Server 2012. Wyciągane dane dotyczą zamówień i danych transportowych w kontekście jednego zlecenia transportowego.
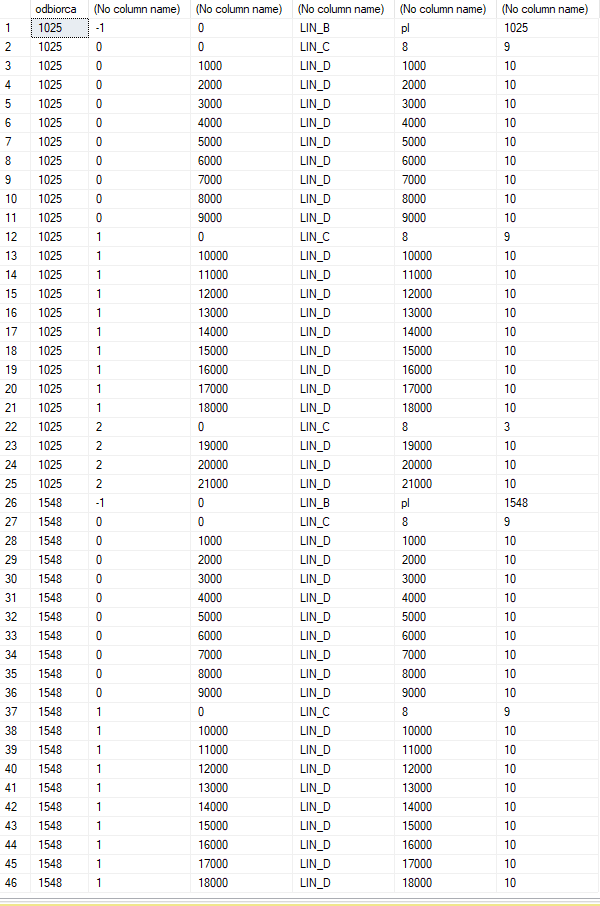
Raport wynikowo składa się z pięciu rodzajów sekcji, które zawierają odpowiednie dla siebie dane i poza pierwszą i ostatnią sekcją które zawsze występują pojedynczo ilość sekcji w środku jest uzależniona od ilości odbiorców zamówień i ilości samego towaru (dokładnie zależności opiszę poniżej).
Całość składa się z dwóch części:
- Procedura w której jest tworzona tabela tymczasowa, uzupełniana danymi z zapytania, po czym następuje pętla w której jest tworzona i odpowiednio uzupełniana druga tabela tymczasowa.
- Raport tworzony w Report Builder 3.0 w którym jest wczytywana i wykonywana procedura pod kątem jednego parametru - NR_TRANSPORTU
Docelowo użytkownik będzie sam generować sobie wyniki w SSRS.
Jako pomoc na wzór dostałem do podpatrzenia inny raport którego zasada działania jest podobna, ale nie zwraca on tylu rodzajów unikalnych danych w kontekście konkretnych odbiorców, a z tymi unikalnymi danymi mam problem.
Procedurę oparłem na nim dostosowując ją pod swoje potrzeby, ale powiedziano mi że tamten mechanizm pętli był tworzony na szybko i niekoniecznie się sprawdzi w moim przypadku.
Ogólny wynikowy schemat wygląda następująco:
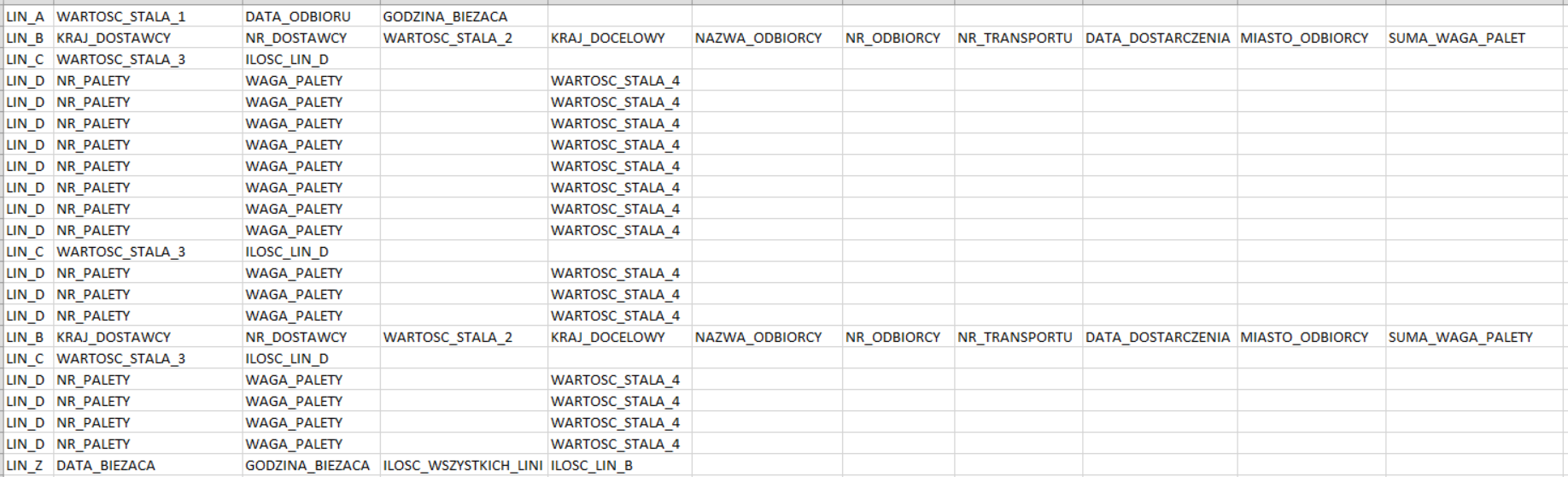
WARTOSC_STALA_1, WARTOSC_STALA_2, WARTOSC_STALA_3, WARTOSC_STALA_4 są uzupełnione na sztywno w Report Builder, więc nie bierzemy ich pod uwagę.
Tak wygląda przykładowo uzupełniony raport:
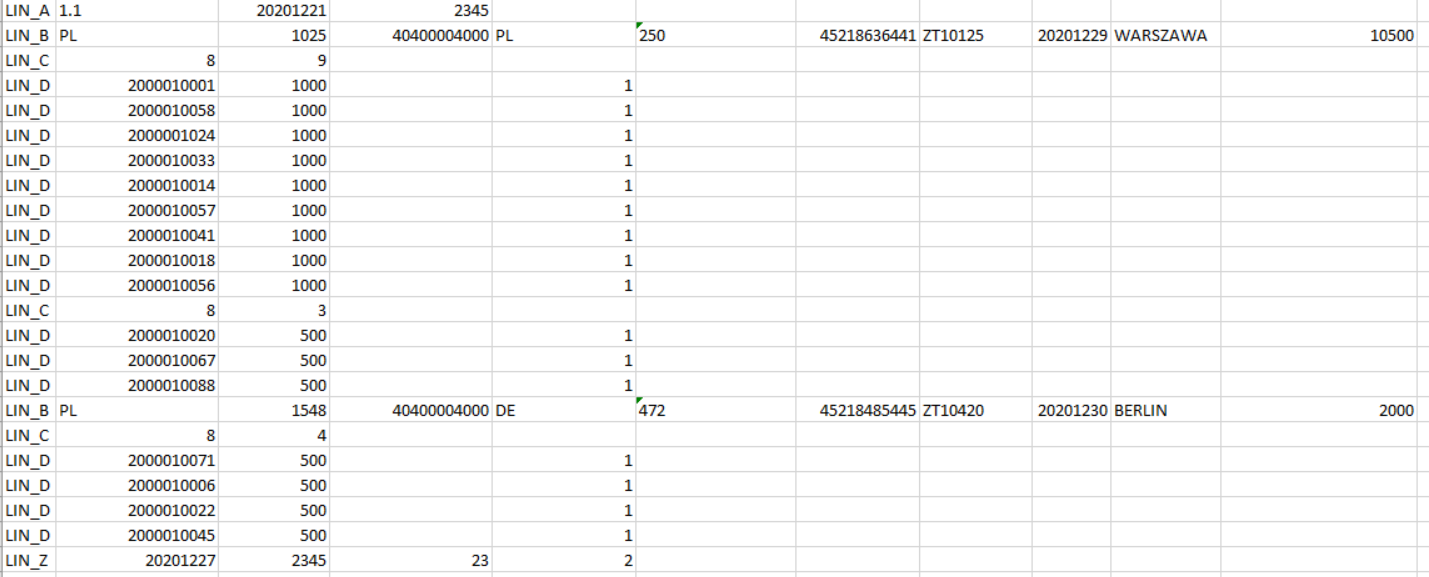
Teraz objaśnię o co chodzi z liniami/sekcjami LIN_B/C/D:
-
LIN_B generuje się w kontekście numeru odbiorcy i poza danymi identyfikacyjnymi zawiera sumę wagową wszystkich zamówień które do niego jadą (bo ktoś mógł złożyć więcej niż jedno zamówienie, są to zazwyczaj sklepy).
-
LIN_C poza wartością stałą zawiera informacje o ilości sekcji LIN_D. I tu ważna informacja, maksymalna ilość sekcji LIN_D to 9. Jeśli jest ich więcej to po wylistowaniu pierwszych dziewięciu LIN_D generowana jest kolejna sekcja LIN_C z informacją o pozostałej ilości sekcji LIN_D.
-
LIN_D wymienia każdą paletę z osobna, stąd WARTOSC_STALA_4 zawsze jest równa 1.
Mój problem dotyczy LIN_D. NR_PALETY i WAGA_PALETY w kontekście odbiorcy/zamówień zawsze mają te same dane i jest to pierwszy wynik. Podejrzewam że wynika to z konstrukcji outer apply(select top 1) i nie mam pomysłu jak to rozwiązać.
Tak to wygląda:
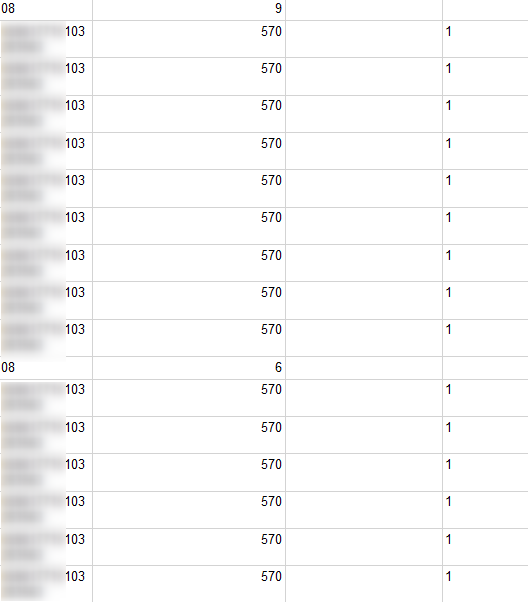
A docelowo dane te powinny być unikalne (SELECT z bazy danych na ten samego odbiorce w kontekście zamówień):
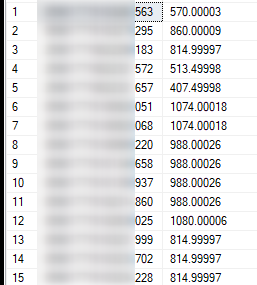
W załączeniu kod obecnej procedury.
kod-procedura.txt
Zastanawiałem się też czy można to wykonać inaczej niż w pętli.
Za wszelakie wskazówki i podpowiedzi z góry bardzo dziękuje.