Cześć,
Jak przy pomocy wyrażeń regularnych odróżnik liczbę INT od REAL?
Niestety tak napisane wyrażenia:
NUMBER : [+-]?([0-9]*[.])?[0-9]+;
NUMBER_INT : [0-9]+ ;
Powodują, że 23 jest kwalifikowana zarowno jako INT, jak i FLOAT.
0
3
Czym są liczby int, czym są liczby real i czym są liczby float?
1
Po co Ci do tego wyrażenia regularne?
Porównujesz liczbę oryginalną, z liczbą po zaokrągleniu - jeżeli są równe sobie to jest to INT, jeżeli nie, to liczba ma ułamki. W każdym języku jest funkcja do zaokrąglania.
0
Bo buduje wlasny compilator. Uzywam antlera, ktory wykorzystuje wlasnie wyrazenia regularne i nie wiem jak odroznic liczbe calkowita od rzeczywistej :(
1
Powiedziałbym, że float musi mieć kropeczkę czyli:
NUMBER : [+-]?[0-9]*\.[0-9]+;
6
elo_elo_elo napisał(a):
Bo buduje wlasny compilator. Uzywam antlera, ktory wykorzystuje wlasnie wyrazenia regularne i nie wiem jak odroznic liczbe calkowita od rzeczywistej :(
Zbuduj poprawny lekser. Uzyskasz nie tylko typ, ale wartość (i ewentualne atrybuty jak 'b' 'x' - gdybyś tak projektował).
To jest właśnie problem, gdy wyrażenia regularne stosuje się jak religię. Użycie regexów w antlr to jak widelec do zupy (..upy).
0
No niestety, ale jestem cienki na razie :(.
Dopiero tego sie ucze.
https://progur.com/2016/09/how-to-create-language-using-antlr4.html?fbclid=IwAR0q_VrPODcaooz8aNEO0kE0fHqB0UUFazv2x3lHrNR6TMkwUy5KCDm46Zo
Cos takiego chce sobie rozbudowac. Antlr sie dopiero ucze. Jave dopiero poznaje. Ale moze sie uda. :D
@Override
public void exitAssign(AssignContext ctx) {
// This method is called when the parser has finished
// parsing the assign statement
// Get variable name
String variableName = ctx.ID(0).getText();
// Get value from variable or number
String value = ctx.ID().size() > 1 ? ctx.ID(1).getText()
: ctx.NUMBER().getText();
// Add variable to map
if(ctx.ID().size() > 1)
variables.put(variableName, variables.get(value));
else
variables.put(variableName, Integer.parseInt(value));
}
Tutaj wymiękam. Niby antler na drzewie ładnie rozpoznaje liczbe całkowitą i rzeczywistą, ale tutaj zaczynaja sie problemy. Jakie macie pomysly jak to moge przerobic?
3
wykorzystuje wlasnie wyrazenia regularne
No chyba nie. ANTLR wykorzystuje gramatykę LL i nijak się ma to do regexów, ale pewnie mówsz teraz o lexerze a nie parserze. Wiesz ze exampli jest sporo i możesz sprawdzić jak to ktoś zrobił? Zwykle:
- albo ma kropke
- albo ma
e - albo np. w niektórych językach ma
fna końcu
8
tak mi się przypomniało :D

0
Hmm... Jakos dalem rade i moj jezyczek dziala :D mnozy, dodaje, odejmuje, drukuje, przypisuje zmienne...
Ale chcialbym jeszcze wygenerowac kod maszynowy zeby zobaczyc jak to wewnatrz dziala...
clang -emit -llvm -S Main.Java
clang: warning: -llvm: 'linker' input unused [-Wunused-command-line-argument]
clang: warning: Main.java: 'linker' input unused [-Wunused-command-line-argument]
clang: warning: argument unused during compilation: '-e mit' [-Wunused-command-line-argument]
nie dziala :(
Znalazlem jeszcze wtyczke do Intelliji, ale w sumie nie wiem jak tego uzyc, wiec chcialem z wiersza polecen.
1
0
elo_elo_elo napisał(a):
Ale chcialbym jeszcze wygenerowac kod maszynowy zeby zobaczyc jak to wewnatrz dziala...
W rodzinie **Antlr **najłatwiej będzie pozwolić na zbudowanie drzewa, i w oparciu o tą samą bibliotekę zrobić analizator drzewa odwiedzający/wykonujący "atomy" języka. (Czyli po lekserze i analizatorze syntaktycznym trzecia część).
Czyli drzewo jako postać finałowa (tu się różnimy od fabrycznych kompilatorów) ale dająca się wykonać interpreterem.
Zrobiłem tak zw dwa razy, działało.
Wprawa w Antlr jest raczej wymagana, na owe czasy ta trzecia część była znacznie słabiej udokumentowana
Wygenerowanie kodu maszynowego (raczej rozumiem na "meta-maszynę") łatwe nie będzie.
0
Ok. Czyli tego nie zrobie magicznie jedna komenda? :( Mam jakies drzewo narysowane w Antlerze, to o to drzewo chodzi? - elo_elo_elo 36 minut temu
Tak. To drzewo powstało, wyraża program, ale teraz jest "bezużyteczne". Trzeba sprawić, aby było użyteczne.
Np w jakimś elemencie masz symbol WHILE.
W prawym podrzewku masz wyrażenie, które tzreba wykonać (zwartościować)
W lewym sekwencję kodu, która jest zawartością pętli.
I tak od pnia, dla wszystkich symboli. Oczywiście piszę zupełnie z powietrza.
0
@AnyKtokolwiek: No ok. A jak to sie robi? Potrzebuje troche za reke poprowadzenia albo dobrego nakierunkowania. :( Tak, zebym wiedzial, czego musze szukac :(.
Mam taki fragment mojego programu testowego i cos takiego mi antler narysowal.
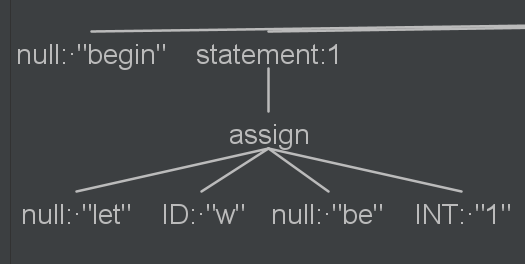
0
elo_elo_elo napisał(a):
@AnyKtokolwiek: No ok. A jak to sie robi? Potrzebuje troche za reke poprowadzenia albo dobrego nakierunkowania. :( Tak, zebym wiedzial, czego musze szukac :(.
Mam taki fragment mojego programu testowego i cos takiego mi antler narysowal.
https://theantlrguy.atlassian.net/wiki/spaces/ANTLR3/pages/2687311/Simple+tree-based+interpeter
No fajnie (za moich czasów tego nie było, podoba mi się)
Czyli
- jednym z możliwych "statemetów" jest "assign"
- "assign" składa się z 4ch elementów
- "let" i "be" są dla nas bezwartościowe (mają być, sprawdzamy (acz niekoniecznie, syntax już sprawdzony) ale nie generujemy dla nich nic)
- bierzemy zmienną "w" i jedynkę (nie wiem co to u ciebie jest w ogólności, jakieś EXPRESSION ???)
I rdzeń interpretera, czyli zakładamy na głowę radiator, i bawimy się w CPU:
- dla "w" tworzymy lub odnajdujemy już otworzoną "komórkę pamięci" (to już jest czysty kod interpretera - jeśli język ma bloki, to w aktualnej ramce bloku itd itp. dbając o typ itd)
- jedynkę (wyrażenie) wykonujemy
- przypisujemy drugie do pierwszego
Oczywiście sporo szczegółów semantycznych dla Twojego języka. Czy komórka "w" może zmienić typ, a jak nie może, to co gdy się różnią itd...
Strasznie to lubiłem, robię to rzadko, może raz na dwa lata, ale sprawia mi frajdę. W porównaniu do lex/yacc to niebo a ziemia