To, że danych jest mnóstwo, nie znaczy, że je masz ;-) Ktoś je musi wyciągnąć, ktoś je musi przeanalizować (zbudować model) i finalnie napisać program, który będzie korzystał z modelu.
Podstawą są dane, dużo danych.
W takim razie trzeba zacząć od tego żeby ktoś "wyciagnal" takie dane, tzn żeby ten "model" pobierał je z ogólnodostępnych stron i sam się aktualizował. Jest to możliwe?
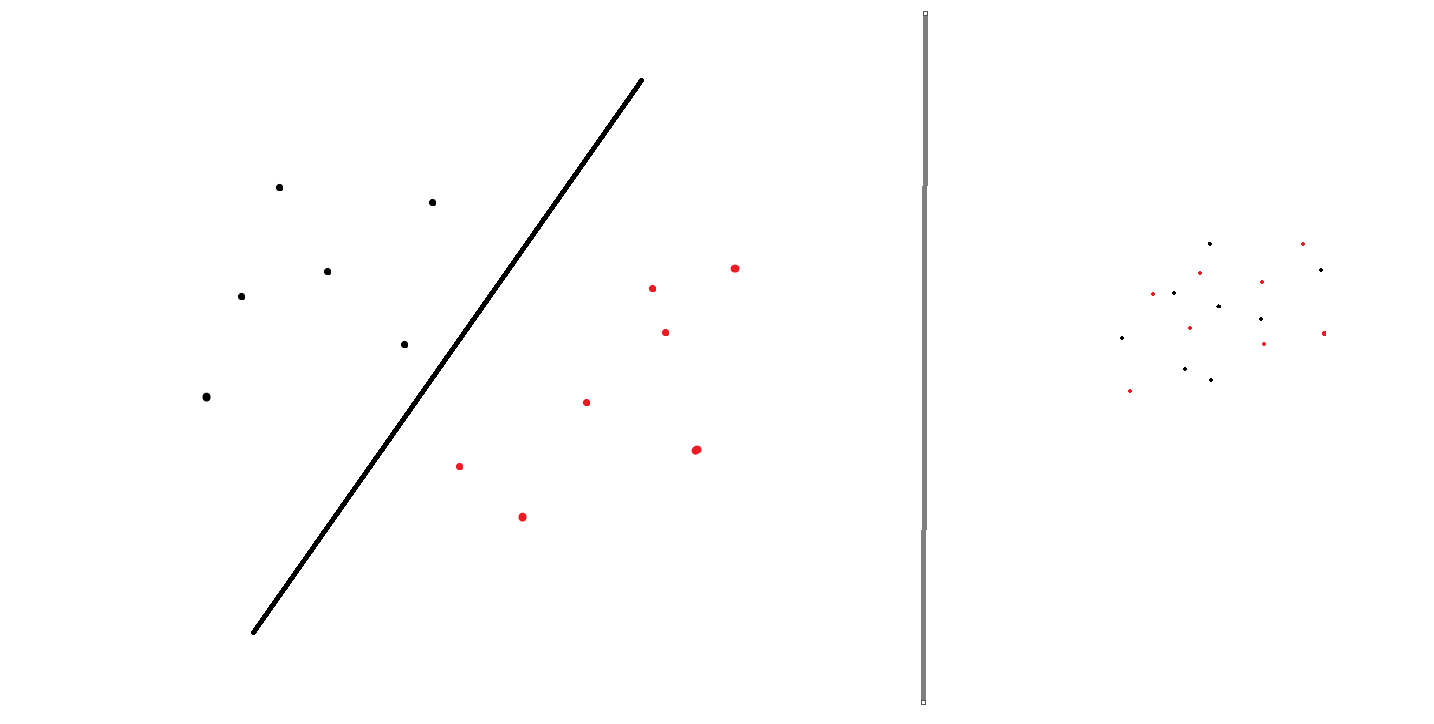
Model nic nie pobiera, bo w uproszczeniu jest to funkcja matematyczna. Tak jak np. funkcja liniowa f(x)=ax+b. Ta funkcja nic nie pobiera z ogólnodostępnych stron i się sama nie aktualizuje.
Zbierasz dane/masz dane -> poddajesz analizie -> proponujesz model matematyczny -> programujesz model -> karmisz go danymi wejściowymi -> model produkuje wynik -> obliczone coś jest bliskie rzeczywistości albo nie jest, tyle jeśli chodzi o "sztuczną inteligencję".
Taki model, np. perceptron możesz aktualizować, w tym sensie, że jak będziesz miał nowe dane, to możesz jeszcze raz taki model wytrenować, co będzie skutkowało pewną korektą wyuczonych parametrów.
Same wyniki meczów moim zdaniem nie wystarczą i powinieneś zbierać informacje kto z kim gra, ile ma lat, o której gra, w jakiej strefie geograficznej, z jakiej strefy przyjechał, jaka jest pogoda w trakcie meczu (wpływa na samopoczucie, a to na sprawność), ile meczy rozegrał/wygrał/przegrał, jaką ma passę itd., jak wygrywa/przegrywa itp., opinie dziennikarzy, bukmacherów itd. Dopiero z tej masy danych maszyna może odkryć jakieś zależności.