Witam serdecznie kolegów i koleżanki,
wiem robię źle i na tym kończą się pomysły. Uparłem się, że to musi być w pythonie. Problem jest taki, mam string w którym są same cyfry, i ten string trzeba zamienić na kody ascii oddzielone przecinkiem.
Program testowy postarałem się żeby był przejrzysty:
import re
input_string = "000123259300269299255000"
numbers = [int(match) for match in re.findall(r'([3-9]\d{1}|[1-9]\d{2}|0)', input_string) ]
result = ','.join(map(str, numbers))
print(result)
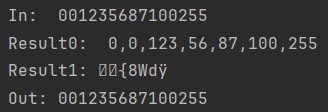
W rezultacie wykonania programu otrzymuje: 0,0,0,123,259,30,0,269,299,255,0,0,0
Jak widać pierwsze trzy zera prawidłowo rozpoznane, 123 również jednak kolejne 259 jest błędne prawidłowo powinno być 25 a później 93 bo każdy wynik cząstkowy nie może być większy niż 255. Prawidłowy wynik parsowania ascii powinien wyglądać tak: 0,0,0,123,25,93,0,0,26,92,99,255,0,0,0.
Z góry dziękuje (thanks from mountain) za każdą podpowiedz jak to prosto wygenerować.
Pozdrawiam serdecznie...