Gdy pobieram automatycznie plik za pomocą send_keys() to problemu nie ma, ale plik ma automatycznie nadawaną nazwę. Gdy chce zapisać go z wybraną nazwą w wybranej lokalizacji to zapisuje się on ale jest pusty.
Poniżej fragment kodu. Z góry dziękuje za wskazówki.
import requests
from time import sleep
from selenium import webdriver
from selenium.webdriver.common.by import By
filepath = r'C:\Users\xxx\OneDrive\Desktop\test.xlsx'
browser = webdriver.Edge()
-----------------------------------
file_url = download_limits1.get_attribute("href")
while True:
response = requests.get(file_url, stream=True)
if response.status_code == 200:
with open(filepath, 'wb') as file:
for chunk in response.iter_content(8192):
file.write(chunk)
break
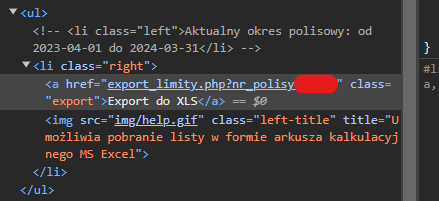
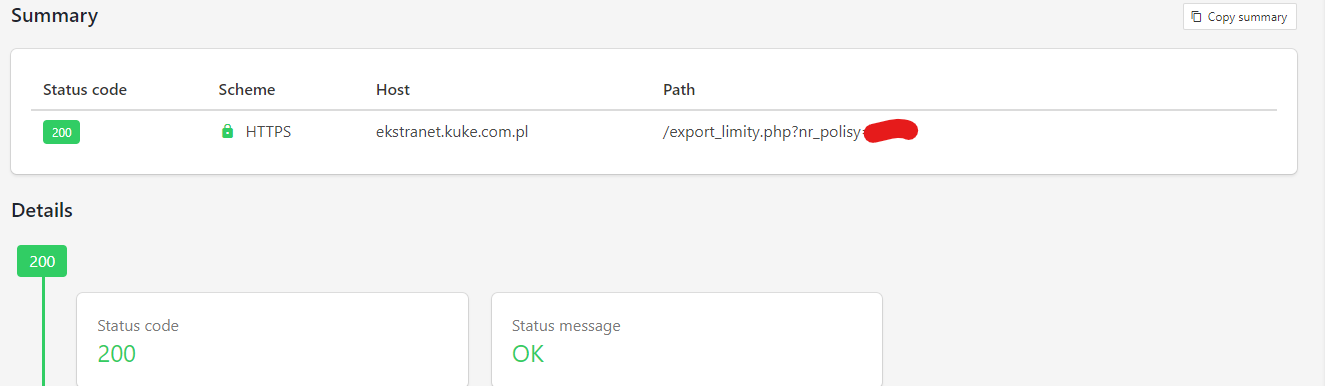 ).
).