Witam
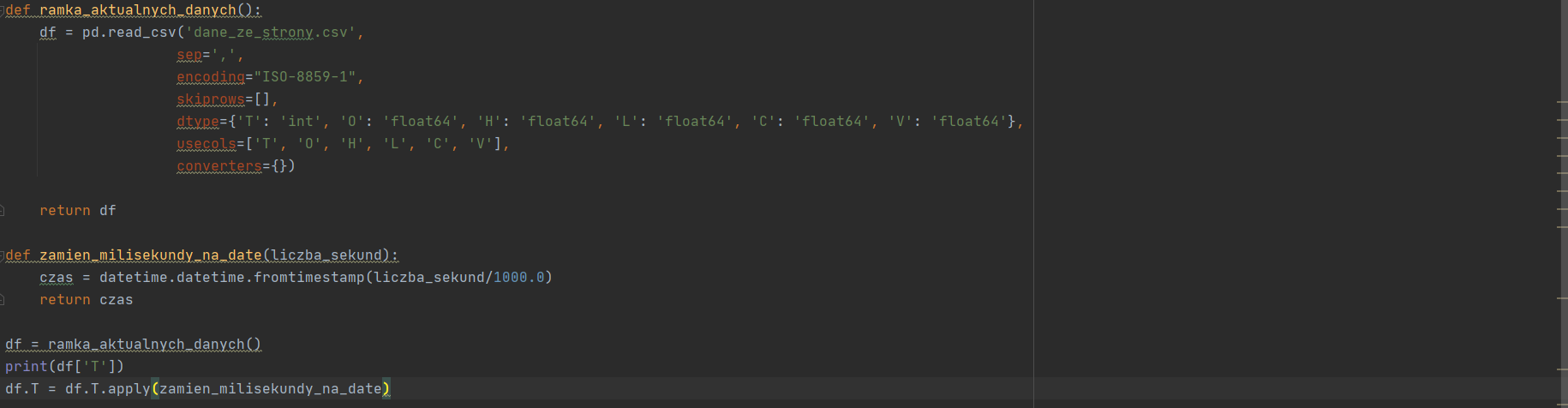
Ładuje plik.csv za pomocą csv_read().
df = pd.read_csv('dane_ze_strony.csv',
sep=',',
encoding="ISO-8859-1",
skiprows=[],
dtype={'T': 'int', 'O': 'float64', 'H': 'float64', 'L': 'float64', 'C': 'float64', 'V': 'float64'},
usecols=['T', 'O', 'H', 'L', 'C', 'V'],
converters={})
W pierwszej kolumnie jest podany czas w milisekundach.
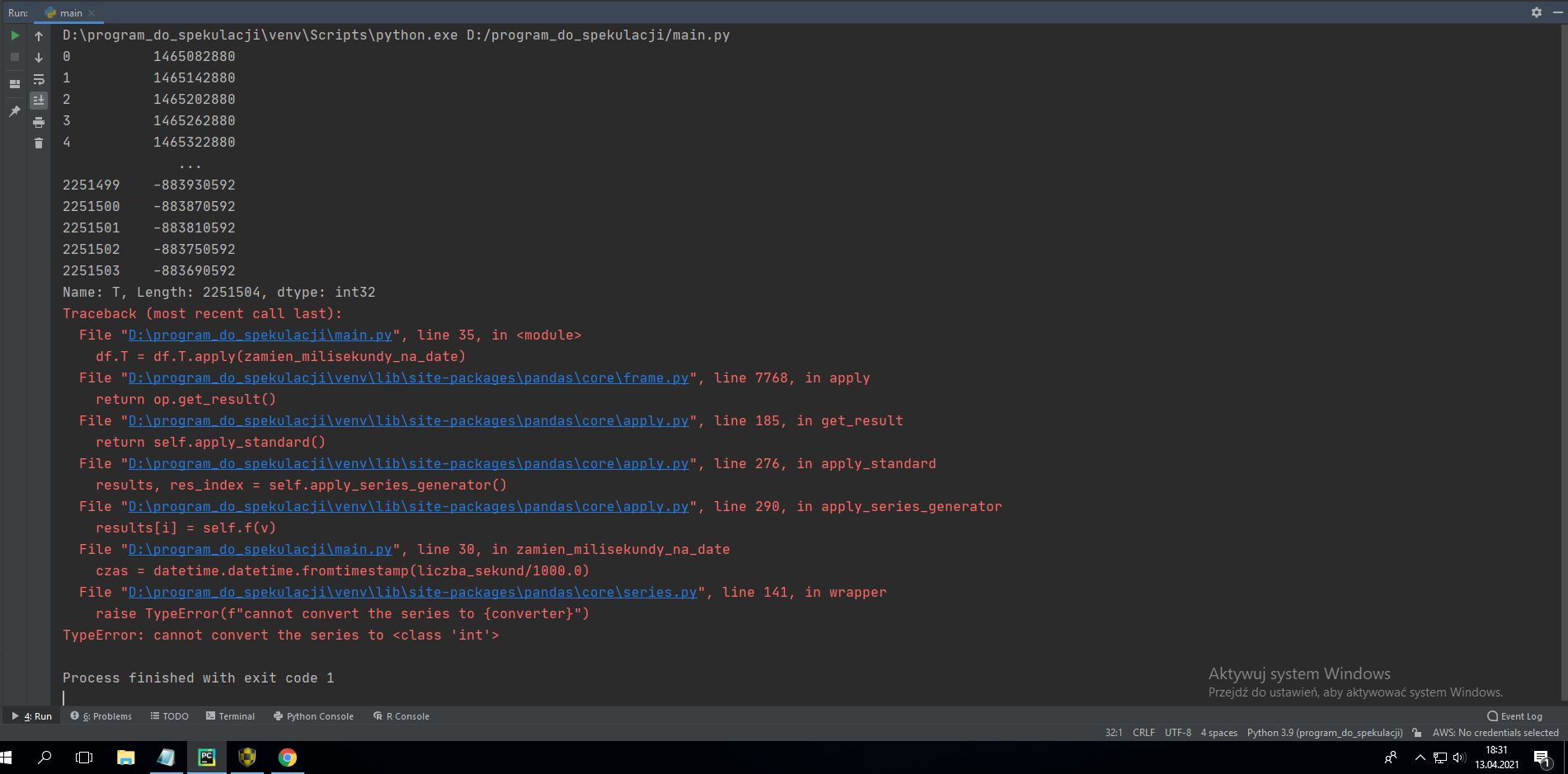
Po użyciu print( df ['T'] ), w konsoli wyświetla:
0 1465082880
1 1465142880
2 1465202880
2251503 -883690592
Name: T, Length: 2251504, dtype: int32
Problem 1
Dlaczego końcowe rekordy są zamieniane na liczbę ujemną, kiedy jest ich dużo?
Przy małej liczbie działa.
Napisałem sobie funkcje przetwarzającą sekundy na date.
def zamien_milisekundy_na_date(liczba_sekund):
czas = datetime.datetime.fromtimestamp(liczba_sekund/1000.0)
return czas
Używam jej przez apply.
df.T = df.T.apply(zamien_milisekundy_na_date)
I dostaje błąd:
cannot convert the series to <class 'int'>
Ale przecież chwile wcześniej przy wyprintowaniu kolumny typ danych był dtype: int32 ?!
Jak użyć DataFrame dla dużej liczby rekordów i jak zmienić sekundy na date??
Dzięki
Pozdrawiam