Hej, napisałem dwa skrypty ogólnie pobrania kodu html ze strony i wyszukiwania odpowiedniego teksu w nim.
Skrypt 1:
Jeśli znajdzie szukaną frazę otwiera skrypt drugi.
<?php
$file = fopen("page.php", "w");
$c = curl_init();
curl_setopt($c, CURLOPT_URL, "https://www.meczyki.pl/wyniki-na-zywo/crystal-palace-manchester-city/3450528.html");
curl_setopt($c, CURLOPT_FILE, $file);
curl_exec($c);
$plik = file_get_contents('page.php');
if(preg_match_all('/<div class="stats-row-middle" data-v-08ffb7ec data-v-51055d8c>Strzały</', $plik)) //
{
include ('skrypt2.php');
}
else{
}
curl_close($c);
fclose($file);
?>
Skrypt 2:
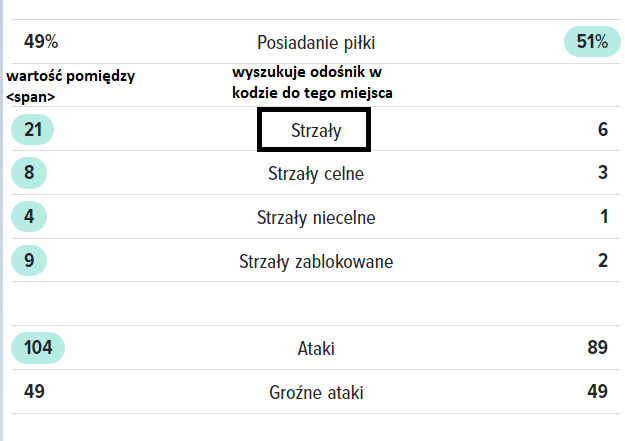
Przed każdą z wartości statystyk jest wartość zmiennej $tresc, już wiem że zrobiłem błąd bo chciałem aby po wyszukani frazy z 1 skryptu znaleźć położenie wartości statystyki strzały dla jednej i drugiej strony która w kodzie znajduje się równolegle przed (mb_strrpos() i po (mb_strripos() "strzały".
<?php
$tresc = print "<span data-v-08ffb7ec data-v-51055d8c>";
$plik = file_get_contents('page.php');
$pos1 = mb_stripos($plik, $tresc);
$pos2 = mb_strrpos($plik, $tresc);
if
($pos1 === false AND $pos2 === false) { // nie
print "Szukany tekst nie został odnaleziony.";
} else { // tak
if ($pos1 !== false) { // pierwsze
print "Pierwsze wystąpienie ciągu znaków \"$tresc\" ";
print "zostało odnalezione na pozycji nr $pos1";
}
print "\n";
if ($pos2 !== false) { // ostatnie
print "Ostatnie wystąpienie ciągu znaków \"$tresc\" ";
print "zostało odnalezione na pozycji nr $pos2";
}
}
?>
Teraz tylko ciekawi mnie ten wynik, bo nie mogę dojść co mi daje. Macie może jakiś pomysł jak to rozwiązać od tego etapu w którym jestem? potrzebuje te statystyki potem wrzucić do db.
Pierwsze wystąpienie ciągu znaków "1" zostało odnalezione na pozycji nr 241 Ostatnie wystąpienie ciągu znaków "1" zostało odnalezione na pozycji nr 620788