Moja teza jest taka - zamiast chodzić po polu minowym i rozwijać umiejętności saperskie można po prostu te pola omijać.
Wiedza nt tego co można a co nie można jest kluczowa; raz nabyta z Tobą zostaje, kiedy się już nauczysz co może coś zepsuć a co nie, to już będzie potem prosto.
To nie jest tak, że jak skorzystasz z biblioteki to ona machnie magiczną różdżką, i już możesz być bezmuzgiem który tylko jej użyje. Nawet jak korzystasz z perfekcyjnego narzędzia, musisz mieć z tyłu głowy to co on za Ciebie robi; i co mogłoby się stać jeśli byś go nie użył; ewentualnie co musiałbyś sam zrobić, żęby znaleźć alternatywę.
Dodatkowe biblioteki owszem, są pomocne w utrzymaniu; ale nie są cudownymi dżinami dzięki którym amator lub ktoś bez know-how może być tak samo wydajny jak ekspert.
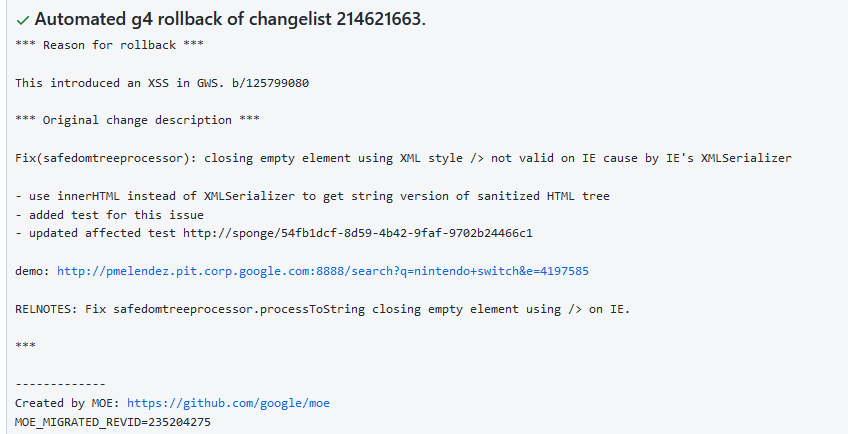
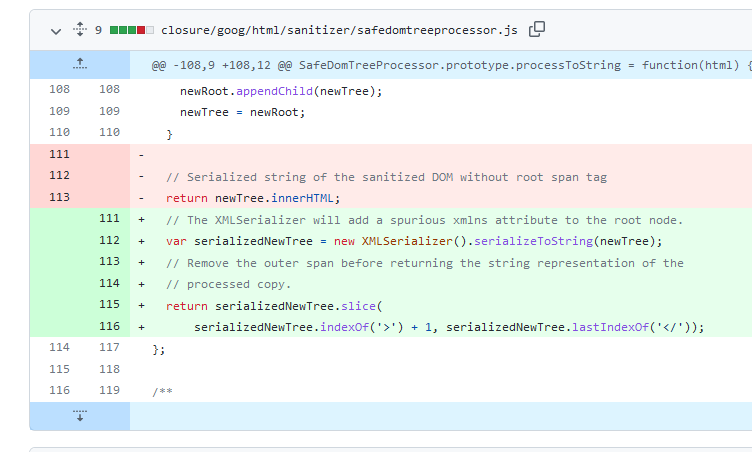
W każdym z podanych przez Ciebie przykładów injectionów frameworki (templatowe) zajmują się ogarnianiem eskejpowania.
W przypadku HTML jest to szczególnie istotne, bo mamy przynajmniej 5 różnych typów eskejpowania jakie należy stosować, w zależności od kontekstu - naprawdę łatwo się pomylić.
To prawda; jeśli masz do dyspozycji bibliotekę do UI, która to zrobi za Ciebie, to możesz jej użyć.
Ale:
- Po pierwsze, nie wszystkie biblioteki są dobre, i nie escape'ują wszystkie w 100% przykadków. Jeśli nie masz tej "saperskiej wiedzy", to możesz wpaść w pułapke libki. Taki React jest bardzo bezpieczny pod tym względem, ale nie wszystkie takie są.
- Po drguie, nie zawsze masz możliwość pracy z taką libkę. Możesz trafić na zadanie w legacy projekcie; i jedyne co Cię wtedy może uratować to ta saperska wiedza
- Po trzecie, raz nabyta wiedza saperska (jak to nazwałeś) jest tranzytywna do każdej innej technologii na świecie, nie ważne czy to DOM, JSP, balde, twig, czy jakiekolwiek inne rozwiązanie do tego typu rzeczy. Polegając na bibliotece, ograniczasz się tylko do niej.
Dlatego uważam, że regularne korzystanie z gołego DOM w większym projekcie to sabotaż. Podobnie jak sklejanie SQLi.
Jeśli mówiąc "sabotaż" masz na myśli podatność na XSS, to podtrzymuje zdanie - Tylko wtedy jeśli nie wiesz co robisz.
Jeśli móiąc "sabotaż" masz na myśli kod niskiej jakości, to zgadzam się. Ale nie dlatego że jesteś podatny na XSS przez to; tylko dlatego że zbyt związałeś swoją plikacje ze szczegułem implementacyjnym. Jeśli staje się to powtarzalne i uciążliwe, to należy to albo wydzielić, albo napisać swoje rozwiązanie, albo skorzystać z istniejącego; wtedy kiedy będzie ku temu faktyczny powód.
Mam wrażenie że pomyliłeś podatność na błędy w bezpieczeństwie z utrzymywalnością aplikacji.