Jak byście zaimplementowali cykliczne odpytywanie zewnętrznego serwisu stosując clean architecture?
Przez clean architecture mam na myśli to:
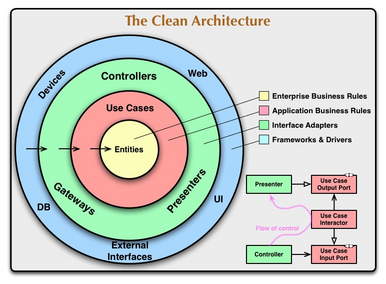
Przykładowy scenariusz:
- Użytkownik przesyła do mojej aplikacji dokument
- Zapisuję dokument u siebie, a następnie przesyłam go do zewnętrznego serwisu do dalszego procesowania (przetwarzanie asynchroniczne)
- Po przetworzeniu przez zewnętrzny serwis chcę pobrać z niego informację o wyniku przetwarzania - serwis nie udostępnia powiadomień/webhooków po swojej stronie, więc muszę zrobić polling. Po przetworzeniu przez zewnętrzny serwis chcę wykonać coś dodatkowego u siebie, poinformować użytkownika o zakończeniu procesowania itp.
To jakie dokumenty wysłałem do przetwarzania i nie dostałem jeszcze odpowiedzi mam zapisane w jakiejś bazie.
Zastanawiam się, w którym miejscu powinienem zrobić to odpytywanie.
Pierwsza myśl to w warstwie Application/Core (czyli UseCases na schemacie):
Zakładając że ta część nie ma zależności do frameworków to musiałbym zdefiniować sobie jakiś interfejs typu IBackgroundJob z polem określającym jak często taki Job ma się odpalać w tle i w warstwie infrastructure zaimplementować jakiegoś JobRunnera (czy to będzie pod spodem jakiś Hangfire, Quartz, czy zwykły BackgroundService z .NET Core to nie ma już znaczenia).
No i teraz w tej warstwie Core mogę sobie zaimplementować coś w stylu DocumentProcessingStatusChecker : IBackgroundJob który zgodnie z jakimś interwałem pobiera z bazy dokumenty dla których nie mam jeszcze wyników (i których nie odpytywałem o status w ostatnich x minutach) i odpytuje zewnętrzne api o status. Jak jest wynik to coś sobie aktualizuję na modelu i zapisuje do bazy.
Druga opcja to implementacja odpytywania bezpośrednio w warstwie Infrastructure:
Tutaj nie muszę się bawić w jakieś dodatkowe interfejsy tylko w najprostszym przypadku implementuję takiego joba bezpośrednio jako BackgroundService z .NET Core. W tej warstwie mam dostęp do DbContextu, czy tam implementacje innych repozytoriów jeśli mam jakiegoś NoSQLa więc też bezpośrednio czytam z bazy to co mi trzeba. Odpytałem zewnętrzny serwis i mam wynik procesowania. Teraz muszę to jakoś przekazać do warstwy Core, więc definiuję tam nowy UseCase na aktualizowanie statusu przetwarzania (albo CommandHandler jak używam mediatr) i go wywołuję z warstwy infrastructure.
W tym przypadku odpytywanie nie bardzo wiąże mi się z szeroko rozumianym Corem mojej aplikacji, bo to trochę taki szczegół implementacyjny - gdyby ich api obsługiwało powiadomienia to w Core miałbym tylko jakiś UseCase do aktualizacji statusu tak jak w scenariuszu 2 - więc może jednak druga opcja jest lepsza?
Z drugiej strony gdyby to był jakiś proces biznesowy, np. po otrzymaniu konkretnego statusu, użytkownik ma 7 dni na akceptację albo odrzucenie dokumentu i co jakiś czas chcę mu wysłać przypomnienie to wtedy chyba bym się skłaniał ku opcji 1, bo to jednak jest jakaś logika biznesowa.
A może jeszcze inaczej?