Cześć, moim zadaniem jest napisanie wyrażenia regularnego:
"identyfikator czyli ciąg liter i cyfr zaczynający się od litery, kończący się znakiem nie
będącym ani literą ani cyfrą (ten znak kończący nie należy już do identyfikatora)"
Chciałbym rozbudować zadanie o obsługę cyrylicy, i pomimo usilnych starań, mój wzór nie rozpoznaje rosyjskich liter. Czy jest ktoś w stanie powiedzieć mi w jaki sposób to zrobić, żeby działało poprawnie?
Mój wyjściowy wzór wygląda następująco: (obsługa TYLKO łacińskiego alfabetu)
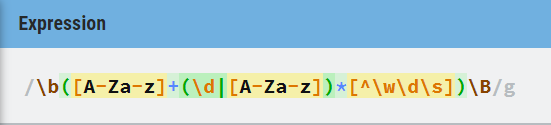
Wzór "rozbudowany": (niedziałający)

Zadanie jest wykonywane na stronie: https://regexr.com/
PS. jeśli nieprawidłowy dział, proszę o przeniesienie. To mój pierwszy post ;)