Cześć,
Z tego co kojarzę dostęp do dysków HDD jest jednowątkowy(?) tj. nie możemy odczytać danych w tym samym czasie przez dwa wątki/procesy. Najpierw muszą być zapisane/odczytane dane jednego wątku a następnie drugiego.
Zastanawiam się czy analogicznie jest z obecnymi dyskami SSD (NVMe) - czy jeśli mam procesor, który ma np. 16 rdzeni i każdy rdzeń chce odczytać dane z dysku to czy zrobi mi się kolejka czy może obecnie dyski potrafią współpracować z wieloma zadaniami i udostępniać dane do wielu wątków jednocześnie?
0
1
Ciekawe, z dysków nie czyta się po 1 bajcie czy 40 bajtach, tylko cały blok się wczytuje.
Najlepiej zrobić benchmark bo tak to nie jest to oczywiste.
Są narzędzia takie jak DMA, które pozwalają dyskowi mapować pamięć w ramie i odwrotnie z ramu na dysk bez udziału CPU dzięki temu się nie obciąża procesora.
Im bardziej granularne operacje czyli im więcej procesów w różnych losowych miejscach modyfikuje małe pliki tym gorszy performance, przy transferowaniu dużych plików osiągniesz prędkość taką jaką deklaruje producent.
PCI jest dosyć wolne, ale szerokie.
Procesy mogą zapisać dane do zapisania i zakończyć pracę, ale te dane mogą się po czasie dopiero zapisać, kiedy DMA je obsłuży.
Na pewno są jakieś sposoby, że spowolnić pracę dysków, ale nie interesowałem się tym nigdy.
Najlepiej zrób benchmark bo tak kto wie to są spekulacje bez rzeczywistych danych i lepiej NVMe, a jak nie to SSD, HDD to naprawdę wolne dyski są.
Świat nie jest taki oczywisty najlepiej zrobić benchmark, metryki, testy, zawsze może się okazać, że było się w błędzie, ludzie nie są nieomylni, a technologia się zmienia.
4
Szeroki temat :)
W dużym skrócie, tak, da radę obsłużyć wiele zadań równoległych.
- dla NVMe masz pary kolejek <Submission,CompletionQueue>
- zgodnie ze specyfikacją NVMe https://nvmexpress.org/wp-content/uploads/NVM-Express-1_4c-2021.06.28-Ratified.pdf możesz mieć do 65 535 takich par (chodzi o ilość określoną przez protokół)
- OS przeważnie tworzy taką parę per core
- konkretny dysk/kontroller NVMe implementujący NVMe może ograniczać ilość takich par (więc tu trzeba by wczytać się w specyfikację konkretnego dysku/kontrolera)
- każda kolejka może mieć określoną głębokość (to też zależy od dysku)
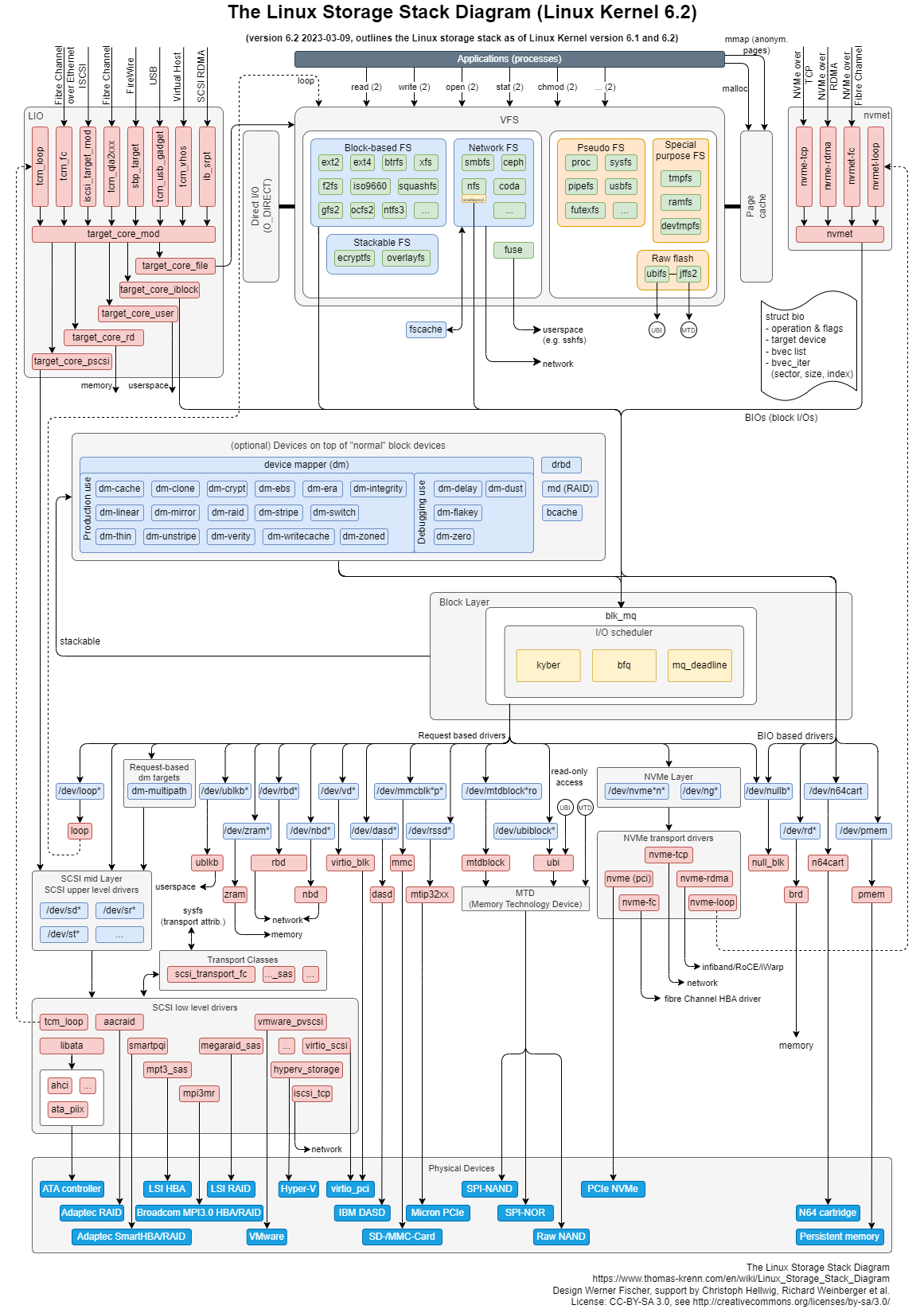
Requesty I/O od aplikacji do dysku przechodzą przez wiele warstw (programowych i sprzętowych), np. dla Linuxa może być taka ścieżka:
Aplikacja -> Wątek -> Request I/O -> wywołanie systemowe (read() ) -> Virtual File System -> I/O scheduler -> NVMe Layer -> NVMe Transport drivers -> PCIe NVMe
Fizycznie, dysk NVMe będzie wetknięty w jakiś slot PCIe i będzie jakiś CPU/kontroler. Wszystkie te konkretne komponenty dogadają się co do tego ile ścieżek PCIe będzie wykorzystywanych do transferu danych (#PCI lanes).
Na tych warstwach może zachodzić kolejkowanie/cachowanie. Do kolejek mogą trafiać requesty z różnych wątków. Zamiast fizycznego I/O możesz mieć obsługę z "Page Cachea" (RAMu).