Chciałbym dostosować do swoich potrzeb lub stworzyć edytor znaczników formatu tekstu tak jak jest to możliwe dla komponentu FormatedLabel od DevExpress:
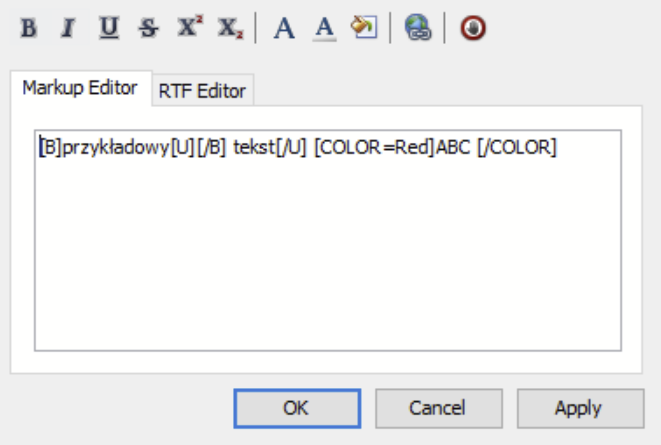
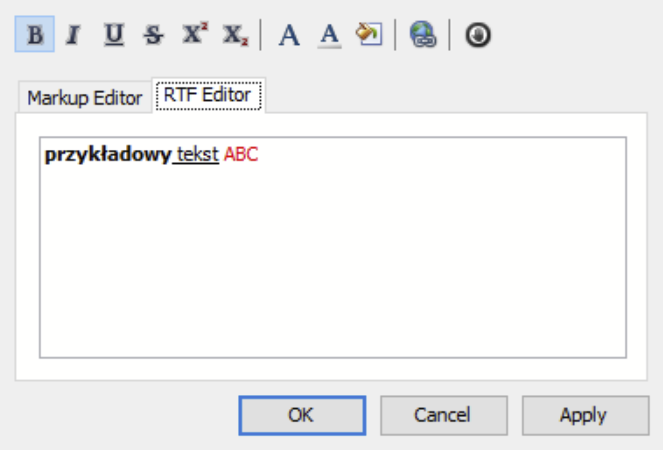
Problem polega na tym, że moje znaczniki nie są BBCode tylko używają nawiasów ostrych < > zamiast kwadratowych jak w przykładzie i trochę inaczej zapisują kolor czcionki.
Swoich znaczników nie zmienię, ponieważ pochodzą z gotowego rozwiązania.
Na początku zacząłem przerabiać edytor od DevExpress i było całkiem nieźle do momentu konwertowania pomiędzy widokami. Ingerowanie w ich kod głębiej nie ma sensu bo to multum roboty ale w ostateczności może jeszcze raz do tego usiądę.
Potrzebne mi są jedynie 4 znaczniki: pogrubienie, kursywa, podkreślenie i kolor czcionki. Chciałem stworzyć swój edytor na wzór tego powyższego ale mam problem ze znalezieniem fragmentów tekstu ze znacznikami, który mam formatować. Chciałem ugryźć to regexami ale nie pracuje z nimi na co dzień więc mam problem.
Załóżmy, że mam taki tekst ze znacznikami:
początek <b> pogrubienie1 </b> = <b> pobrubienie2 </b> coś na końcu
Potrzebuję wyciągnąć teraz z tego pary znaczników
<b> </b>
żeby odpowiednio pogrubić widok w RTF.
Napisałem takie wyrażenie:
([^<>]*)(<b>)([^<>]*)(</b>)([^<>]*)
które teoretycznie dla danego przykładu działa ok ale przy zagnieżdżonych innych znacznikach będzie problem. Mam 2 dopasowania i mogę wyciągnąć wszystko i zmienić to co mi jest potrzebne.
Problem w tym, że przy błędach w tekście wyrażenie pomija część tekstu, czyli przy konwertowaniu ucięło by mi informacje. Przykład błędnego tekstu, który nie zostanie prawidłowo rozpoznany przez moje wyrażenie:
początek nie jest łapany <b> pierwszy znacznik bez domknięcia <b> pogrubienie1 </b> = <b> pobrubienie2 </b> coś na końcu
Przy dodatkowych znacznikach jest podobnie:
<b> <i>pogrubienie i kursywa nie łapane</i> </b> = <b> pobrubienie2 </b> coś na końcu
Zmodyfikowałem wyrażenie na takie:
([^<>]*)(<b>|<i>)([^<>]*)(</b>|</i>)([^<>]*)
ale dalej w pierwszej części nie łapie mi pogrubienia, tylko kursywę.
Z tym też jest problem na początku:
<b> prawa < lewa </b> = <b> pobrubienie2 </b> coś na końcu
Wyrażenia testuję na https://regex101.com/
Czy ktoś byłby w stanie mi pomóc z tymi regexami?
Alternatywnie może można to zrobić inaczej?