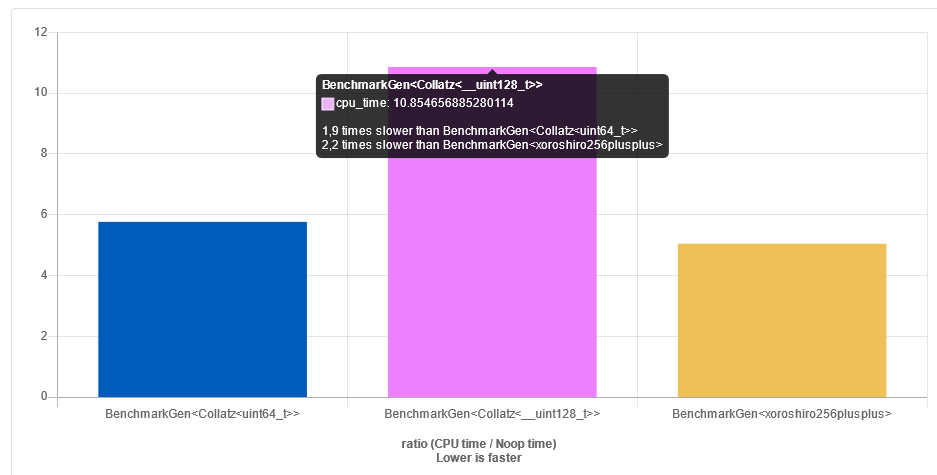
Na xeoniku (3 lub 4 gen) wychodzi identycznie.
Czy mógłbyś wrzucić kod assemblera dla obu programów, do porównania?
gdb -batch -ex 'file ./a.out' -ex 'set disassembly-flavor intel' -ex 'disassemble main' -ex 'disassemble next'
Nie jestem za dobry w czytaniu kodu assemblera, ale widzę tam SSE, chyba że xmm0 i xmm1 nie ma z tym nic wspólnego. Dla wersji 64-bitowej:
Dump of assembler code for function main:
0x00000000004013a0 <+0>: push rbp
0x00000000004013a1 <+1>: mov rbp,rsp
0x00000000004013a4 <+4>: sub rsp,0x90
0x00000000004013ab <+11>: mov DWORD PTR [rbp-0x4],0x0
0x00000000004013b2 <+18>: mov QWORD PTR [rbp-0x10],0x7b
0x00000000004013ba <+26>: mov rax,QWORD PTR [rbp-0x10]
0x00000000004013be <+30>: mov QWORD PTR [rbp-0x18],rax
0x00000000004013c2 <+34>: mov rax,QWORD PTR [rbp-0x10]
0x00000000004013c6 <+38>: mov QWORD PTR [rbp-0x20],rax
0x00000000004013ca <+42>: mov rax,QWORD PTR [rbp-0x10]
0x00000000004013ce <+46>: mov QWORD PTR [rbp-0x28],rax
0x00000000004013d2 <+50>: mov QWORD PTR [rbp-0x30],0x0
0x00000000004013da <+58>: mov rax,QWORD PTR [rbp-0x10]
0x00000000004013de <+62>: mov QWORD PTR [rbp-0x38],rax
0x00000000004013e2 <+66>: mov rax,QWORD PTR [rbp-0x10]
0x00000000004013e6 <+70>: mov QWORD PTR [rbp-0x40],rax
0x00000000004013ea <+74>: mov rax,QWORD PTR [rbp-0x10]
0x00000000004013ee <+78>: mov QWORD PTR [rbp-0x48],rax
0x00000000004013f2 <+82>: mov rax,QWORD PTR [rbp-0x10]
0x00000000004013f6 <+86>: mov QWORD PTR [rbp-0x50],rax
0x00000000004013fa <+90>: call 0x401040 <_ZNSt6chrono3_V212system_clock3nowEv@plt>
0x00000000004013ff <+95>: mov QWORD PTR [rbp-0x58],rax
0x0000000000401403 <+99>: mov QWORD PTR [rbp-0x60],0x0
0x000000000040140b <+107>: cmp QWORD PTR [rbp-0x60],0x3b9aca00
0x0000000000401413 <+115>: jae 0x401445 <main+165>
0x0000000000401419 <+121>: lea rdi,[rbp-0x38]
0x000000000040141d <+125>: lea rsi,[rbp-0x40]
0x0000000000401421 <+129>: lea rdx,[rbp-0x48]
0x0000000000401425 <+133>: lea rcx,[rbp-0x50]
0x0000000000401429 <+137>: call 0x401340 <_Z4nextRmS_S_S_>
0x000000000040142e <+142>: mov QWORD PTR [rbp-0x30],rax
0x0000000000401432 <+146>: mov rax,QWORD PTR [rbp-0x60]
0x0000000000401436 <+150>: add rax,0x1
0x000000000040143c <+156>: mov QWORD PTR [rbp-0x60],rax
0x0000000000401440 <+160>: jmp 0x40140b <main+107>
0x0000000000401445 <+165>: call 0x401040 <_ZNSt6chrono3_V212system_clock3nowEv@plt>
0x000000000040144a <+170>: mov QWORD PTR [rbp-0x68],rax
0x000000000040144e <+174>: lea rdi,[rbp-0x68]
0x0000000000401452 <+178>: lea rsi,[rbp-0x58]
0x0000000000401456 <+182>: call 0x401520 <_ZNSt6chronomiINS_3_V212system_clockENS_8durationIlSt5ratioILl1ELl1000000000EEEES6_EENSt11common_typeIJT0_T1_EE4typeERKNS_10time_pointIT_S8_EERKNSC_ISD_S9_EE>
0x000000000040145b <+187>: mov QWORD PTR [rbp-0x78],rax
0x000000000040145f <+191>: lea rdi,[rbp-0x78]
0x0000000000401463 <+195>: call 0x4014f0 <_ZNSt6chrono13duration_castINS_8durationIlSt5ratioILl1ELl1000000000EEEElS3_EENSt9enable_ifIXsr13__is_durationIT_EE5valueES6_E4typeERKNS1_IT0_T1_EE>
0x0000000000401468 <+200>: mov QWORD PTR [rbp-0x70],rax
0x000000000040146c <+204>: lea rdi,[rbp-0x70]
0x0000000000401470 <+208>: call 0x401570 <_ZNKSt6chrono8durationIlSt5ratioILl1ELl1000000000EEE5countEv>
0x0000000000401475 <+213>: movsd xmm0,QWORD PTR [rip+0xb8b] # 0x402008
0x000000000040147d <+221>: cqo
0x000000000040147f <+223>: mov ecx,0x2
0x0000000000401484 <+228>: idiv rcx
0x0000000000401487 <+231>: cvtsi2sd xmm1,rax
0x000000000040148c <+236>: mulsd xmm1,xmm0
0x0000000000401490 <+240>: movabs rdi,0x402010
0x000000000040149a <+250>: movaps xmm0,xmm1
0x000000000040149d <+253>: mov al,0x1
0x000000000040149f <+255>: call 0x401030 <printf@plt>
0x00000000004014a4 <+260>: mov rcx,QWORD PTR [rbp-0x30]
0x00000000004014a8 <+264>: mov QWORD PTR [rbp-0x30],rcx
0x00000000004014ac <+268>: mov rsi,QWORD PTR [rbp-0x30]
0x00000000004014b0 <+272>: movabs rdi,0x404080
0x00000000004014ba <+282>: mov DWORD PTR [rbp-0x7c],eax
0x00000000004014bd <+285>: call 0x401050 <_ZNSolsEm@plt>
0x00000000004014c2 <+290>: mov rdi,rax
0x00000000004014c5 <+293>: movabs rsi,0x40202c
0x00000000004014cf <+303>: call 0x401070 <_ZStlsISt11char_traitsIcEERSt13basic_ostreamIcT_ES5_PKc@plt>
0x00000000004014d4 <+308>: xor r8d,r8d
0x00000000004014d7 <+311>: mov QWORD PTR [rbp-0x88],rax
0x00000000004014de <+318>: mov eax,r8d
0x00000000004014e1 <+321>: add rsp,0x90
0x00000000004014e8 <+328>: pop rbp
0x00000000004014e9 <+329>: ret
End of assembler dump.
Dump of assembler code for function _Z4nextRmS_S_S_:
0x0000000000401340 <+0>: push rbp
0x0000000000401341 <+1>: mov rbp,rsp
0x0000000000401344 <+4>: mov QWORD PTR [rbp-0x8],rdi
0x0000000000401348 <+8>: mov QWORD PTR [rbp-0x10],rsi
0x000000000040134c <+12>: mov QWORD PTR [rbp-0x18],rdx
0x0000000000401350 <+16>: mov QWORD PTR [rbp-0x20],rcx
0x0000000000401354 <+20>: mov rax,QWORD PTR [rbp-0x10]
0x0000000000401358 <+24>: mov rax,QWORD PTR [rax]
0x000000000040135b <+27>: shl rax,0x1
0x000000000040135f <+31>: mov rcx,QWORD PTR [rbp-0x10]
0x0000000000401363 <+35>: mov rcx,QWORD PTR [rcx]
0x0000000000401366 <+38>: mov rdx,QWORD PTR [rbp-0x8]
0x000000000040136a <+42>: add rcx,QWORD PTR [rdx]
0x000000000040136d <+45>: mov QWORD PTR [rdx],rcx
0x0000000000401370 <+48>: imul rax,rcx
0x0000000000401374 <+52>: mov rcx,QWORD PTR [rbp-0x20]
0x0000000000401378 <+56>: mov rcx,QWORD PTR [rcx]
0x000000000040137b <+59>: mov rdx,QWORD PTR [rbp-0x18]
0x000000000040137f <+63>: add rcx,QWORD PTR [rdx]
0x0000000000401382 <+66>: mov QWORD PTR [rdx],rcx
0x0000000000401385 <+69>: xor rax,rcx
0x0000000000401388 <+72>: mov rcx,QWORD PTR [rbp-0x10]
0x000000000040138c <+76>: mov QWORD PTR [rcx],rax
0x000000000040138f <+79>: mov rax,QWORD PTR [rbp-0x10]
0x0000000000401393 <+83>: mov rax,QWORD PTR [rax]
0x0000000000401396 <+86>: pop rbp
0x0000000000401397 <+87>: ret
Dla wersji 128-bitowej:
Dump of assembler code for function main:
0x00000000004013f0 <+0>: push rbp
0x00000000004013f1 <+1>: mov rbp,rsp
0x00000000004013f4 <+4>: sub rsp,0xf0
0x00000000004013fb <+11>: mov DWORD PTR [rbp-0x4],0x0
0x0000000000401402 <+18>: mov QWORD PTR [rbp-0x18],0x0
0x000000000040140a <+26>: mov QWORD PTR [rbp-0x20],0x7b
0x0000000000401412 <+34>: mov rax,QWORD PTR [rbp-0x20]
0x0000000000401416 <+38>: mov rcx,QWORD PTR [rbp-0x18]
0x000000000040141a <+42>: mov QWORD PTR [rbp-0x28],rcx
0x000000000040141e <+46>: mov QWORD PTR [rbp-0x30],rax
0x0000000000401422 <+50>: mov rax,QWORD PTR [rbp-0x20]
0x0000000000401426 <+54>: mov rcx,QWORD PTR [rbp-0x18]
0x000000000040142a <+58>: mov QWORD PTR [rbp-0x38],rcx
0x000000000040142e <+62>: mov QWORD PTR [rbp-0x40],rax
0x0000000000401432 <+66>: mov rax,QWORD PTR [rbp-0x20]
0x0000000000401436 <+70>: mov rcx,QWORD PTR [rbp-0x18]
0x000000000040143a <+74>: mov QWORD PTR [rbp-0x48],rcx
0x000000000040143e <+78>: mov QWORD PTR [rbp-0x50],rax
0x0000000000401442 <+82>: mov QWORD PTR [rbp-0x58],0x0
0x000000000040144a <+90>: mov QWORD PTR [rbp-0x60],0x0
0x0000000000401452 <+98>: mov rax,QWORD PTR [rbp-0x20]
0x0000000000401456 <+102>: mov rcx,QWORD PTR [rbp-0x18]
0x000000000040145a <+106>: mov QWORD PTR [rbp-0x68],rcx
0x000000000040145e <+110>: mov QWORD PTR [rbp-0x70],rax
0x0000000000401462 <+114>: mov rax,QWORD PTR [rbp-0x20]
0x0000000000401466 <+118>: mov rcx,QWORD PTR [rbp-0x18]
0x000000000040146a <+122>: mov QWORD PTR [rbp-0x78],rcx
0x000000000040146e <+126>: mov QWORD PTR [rbp-0x80],rax
0x0000000000401472 <+130>: mov rax,QWORD PTR [rbp-0x20]
0x0000000000401476 <+134>: mov rcx,QWORD PTR [rbp-0x18]
0x000000000040147a <+138>: mov QWORD PTR [rbp-0x88],rcx
0x0000000000401481 <+145>: mov QWORD PTR [rbp-0x90],rax
0x0000000000401488 <+152>: mov rax,QWORD PTR [rbp-0x20]
0x000000000040148c <+156>: mov rcx,QWORD PTR [rbp-0x18]
0x0000000000401490 <+160>: mov QWORD PTR [rbp-0x98],rcx
0x0000000000401497 <+167>: mov QWORD PTR [rbp-0xa0],rax
0x000000000040149e <+174>: call 0x401040 <_ZNSt6chrono3_V212system_clock3nowEv@plt>
0x00000000004014a3 <+179>: mov QWORD PTR [rbp-0xa8],rax
0x00000000004014aa <+186>: mov QWORD PTR [rbp-0xb0],0x0
0x00000000004014b5 <+197>: cmp QWORD PTR [rbp-0xb0],0x5f5e100
0x00000000004014c0 <+208>: jae 0x40151e <main+302>
0x00000000004014c6 <+214>: lea rdi,[rbp-0x70]
0x00000000004014ca <+218>: lea rsi,[rbp-0x80]
0x00000000004014ce <+222>: lea rdx,[rbp-0x90]
0x00000000004014d5 <+229>: lea rcx,[rbp-0xa0]
0x00000000004014dc <+236>: call 0x401340 <_Z4nextRoS_S_S_>
0x00000000004014e1 <+241>: mov QWORD PTR [rbp-0xc0],rax
0x00000000004014e8 <+248>: mov QWORD PTR [rbp-0xb8],rdx
0x00000000004014ef <+255>: mov rax,QWORD PTR [rbp-0xc0]
0x00000000004014f6 <+262>: mov rcx,QWORD PTR [rbp-0xb8]
0x00000000004014fd <+269>: mov QWORD PTR [rbp-0x58],rcx
0x0000000000401501 <+273>: mov QWORD PTR [rbp-0x60],rax
0x0000000000401505 <+277>: mov rax,QWORD PTR [rbp-0xb0]
0x000000000040150c <+284>: add rax,0x1
0x0000000000401512 <+290>: mov QWORD PTR [rbp-0xb0],rax
0x0000000000401519 <+297>: jmp 0x4014b5 <main+197>
0x000000000040151e <+302>: call 0x401040 <_ZNSt6chrono3_V212system_clock3nowEv@plt>
0x0000000000401523 <+307>: mov QWORD PTR [rbp-0xc8],rax
0x000000000040152a <+314>: lea rdi,[rbp-0xc8]
0x0000000000401531 <+321>: lea rsi,[rbp-0xa8]
0x0000000000401538 <+328>: call 0x401610 <_ZNSt6chronomiINS_3_V212system_clockENS_8durationIlSt5ratioILl1ELl1000000000EEEES6_EENSt11common_typeIJT0_T1_EE4typeERKNS_10time_pointIT_S8_EERKNSC_ISD_S9_EE>
0x000000000040153d <+333>: mov QWORD PTR [rbp-0xd8],rax
0x0000000000401544 <+340>: lea rdi,[rbp-0xd8]
0x000000000040154b <+347>: call 0x4015e0 <_ZNSt6chrono13duration_castINS_8durationIlSt5ratioILl1ELl1000000000EEEElS3_EENSt9enable_ifIXsr13__is_durationIT_EE5valueES6_E4typeERKNS1_IT0_T1_EE>
0x0000000000401550 <+352>: mov QWORD PTR [rbp-0xd0],rax
0x0000000000401557 <+359>: lea rdi,[rbp-0xd0]
0x000000000040155e <+366>: call 0x401660 <_ZNKSt6chrono8durationIlSt5ratioILl1ELl1000000000EEE5countEv>
0x0000000000401563 <+371>: mov rcx,rax
0x0000000000401566 <+374>: shr rcx,0x3f
0x000000000040156a <+378>: add rax,rcx
0x000000000040156d <+381>: sar rax,1
0x0000000000401570 <+384>: cvtsi2sd xmm0,rax
0x0000000000401575 <+389>: movsd xmm1,QWORD PTR [rip+0xa8b] # 0x402008
0x000000000040157d <+397>: mulsd xmm0,xmm1
0x0000000000401581 <+401>: mov edi,0x402010
0x0000000000401586 <+406>: mov al,0x1
0x0000000000401588 <+408>: call 0x401030 <printf@plt>
0x000000000040158d <+413>: mov rcx,QWORD PTR [rbp-0x60]
0x0000000000401591 <+417>: mov rdx,QWORD PTR [rbp-0x58]
0x0000000000401595 <+421>: mov QWORD PTR [rbp-0x58],rdx
0x0000000000401599 <+425>: mov QWORD PTR [rbp-0x60],rcx
0x000000000040159d <+429>: mov rsi,QWORD PTR [rbp-0x60]
0x00000000004015a1 <+433>: movabs rdi,0x404080
0x00000000004015ab <+443>: mov DWORD PTR [rbp-0xdc],eax
0x00000000004015b1 <+449>: call 0x401050 <_ZNSolsEm@plt>
0x00000000004015b6 <+454>: mov rdi,rax
0x00000000004015b9 <+457>: movabs rsi,0x40202c
0x00000000004015c3 <+467>: call 0x401070 <_ZStlsISt11char_traitsIcEERSt13basic_ostreamIcT_ES5_PKc@plt>
0x00000000004015c8 <+472>: xor r8d,r8d
0x00000000004015cb <+475>: mov QWORD PTR [rbp-0xe8],rax
0x00000000004015d2 <+482>: mov eax,r8d
0x00000000004015d5 <+485>: add rsp,0xf0
0x00000000004015dc <+492>: pop rbp
0x00000000004015dd <+493>: ret
End of assembler dump.
Dump of assembler code for function _Z4nextRoS_S_S_:
0x0000000000401340 <+0>: push rbp
0x0000000000401341 <+1>: mov rbp,rsp
0x0000000000401344 <+4>: mov QWORD PTR [rbp-0x18],rdi
0x0000000000401348 <+8>: mov QWORD PTR [rbp-0x20],rsi
0x000000000040134c <+12>: mov QWORD PTR [rbp-0x28],rdx
0x0000000000401350 <+16>: mov QWORD PTR [rbp-0x30],rcx
0x0000000000401354 <+20>: mov rax,QWORD PTR [rbp-0x20]
0x0000000000401358 <+24>: mov rcx,QWORD PTR [rax]
0x000000000040135b <+27>: mov rax,QWORD PTR [rax+0x8]
0x000000000040135f <+31>: mov rdx,QWORD PTR [rbp-0x18]
0x0000000000401363 <+35>: mov rsi,QWORD PTR [rdx]
0x0000000000401366 <+38>: mov rdi,QWORD PTR [rdx+0x8]
0x000000000040136a <+42>: add rsi,rcx
0x000000000040136d <+45>: adc rdi,rax
0x0000000000401370 <+48>: mov QWORD PTR [rdx],rsi
0x0000000000401373 <+51>: mov QWORD PTR [rdx+0x8],rdi
0x0000000000401377 <+55>: mov QWORD PTR [rbp-0x38],rax
0x000000000040137b <+59>: mov rax,rcx
0x000000000040137e <+62>: mul rsi
0x0000000000401381 <+65>: imul rcx,rdi
0x0000000000401385 <+69>: add rdx,rcx
0x0000000000401388 <+72>: mov rcx,QWORD PTR [rbp-0x38]
0x000000000040138c <+76>: imul rcx,rsi
0x0000000000401390 <+80>: add rdx,rcx
0x0000000000401393 <+83>: shld rdx,rax,0x1
0x0000000000401398 <+88>: add rax,rax
0x000000000040139b <+91>: mov rcx,QWORD PTR [rbp-0x30]
0x000000000040139f <+95>: mov rsi,QWORD PTR [rcx]
0x00000000004013a2 <+98>: mov rcx,QWORD PTR [rcx+0x8]
0x00000000004013a6 <+102>: mov rdi,QWORD PTR [rbp-0x28]
0x00000000004013aa <+106>: mov r8,QWORD PTR [rdi]
0x00000000004013ad <+109>: mov r9,QWORD PTR [rdi+0x8]
0x00000000004013b1 <+113>: add r8,rsi
0x00000000004013b4 <+116>: adc r9,rcx
0x00000000004013b7 <+119>: mov QWORD PTR [rdi],r8
0x00000000004013ba <+122>: mov QWORD PTR [rdi+0x8],r9
0x00000000004013be <+126>: xor rax,r8
0x00000000004013c1 <+129>: xor rdx,r9
0x00000000004013c4 <+132>: mov rcx,QWORD PTR [rbp-0x20]
0x00000000004013c8 <+136>: mov QWORD PTR [rcx+0x8],rdx
0x00000000004013cc <+140>: mov QWORD PTR [rcx],rax
0x00000000004013cf <+143>: mov rax,QWORD PTR [rbp-0x20]
0x00000000004013d3 <+147>: mov rcx,QWORD PTR [rax]
0x00000000004013d6 <+150>: mov rax,QWORD PTR [rax+0x8]
0x00000000004013da <+154>: mov QWORD PTR [rbp-0x8],rax
0x00000000004013de <+158>: mov QWORD PTR [rbp-0x10],rcx
0x00000000004013e2 <+162>: mov rax,QWORD PTR [rbp-0x10]
0x00000000004013e6 <+166>: mov rdx,QWORD PTR [rbp-0x8]
0x00000000004013ea <+170>: pop rbp
0x00000000004013eb <+171>: ret