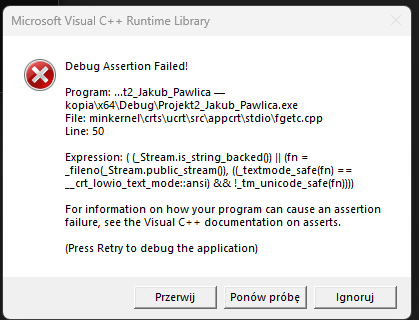
Witam wszystkich mam problem z wczytaniem polskich znaków z pliku tekstowego na ekran.
Program wygląda w ten sposób:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <locale.h>
#include <wchar.h>
#pragma warning(disable: 4996)
int main()
{
setlocale(LC_CTYPE, "Polish");
FILE* plik, * plik2;
char znak, szukany, szukany_napis[2];
int i = 0, i1, j = 0, enter = 0, enter1, raz = 0, x = 0, x1, Czy_Enter = 0, pomoc=0;
plik = fopen("tekst_2.txt", "r");
if (plik == NULL)
{
printf("Niestety nie udało się otworzyć tekstu 2.");
return 1;
}
printf("=============== Tekst 2 =================\n\n");
while ((znak = fgetc(plik)) != EOF)
{
printf("%c", znak);
}
printf("\n\n=========================================\n\n");
printf("Wybierz jeden z powyższych znaków Tekstu 2 aby znaleźć pierwsze jego wystąpienie w Tekście 1:\n");<span style="background-color:#ff0000">
</span>
do
{
if (raz > 0 && j==0)
{
for (int i = 0; i < pomoc; i++)
{
getchar();
}
}
char* wejscie = (char*)malloc(256 * sizeof(char)); //alokujemy tablice z pewną ilością znaków (+znak końca linii)
fgets(wejscie, 256, stdin);
int pomoc = strlen(wejscie)-1; //odjac 1 aby nie liczyc znaku konca linii
szukany = wejscie[0];
free(wejscie); //zwalniamy zaalokowaną pamięć
szukany_napis[0] = szukany;
rewind(plik);
while ((znak = fgetc(plik)) != EOF)
{
if ((strchr(szukany_napis, znak) != NULL) && j < 1 && pomoc==1)
{
j++;
}
}
if (j == 0)
{
printf("Niestety tego znaku nie ma w powyższym tekście lub podałeś ciąg znaków. Podaj pojedynczy znak ponownie:\n");
}
raz++;
} while (j == 0);
fclose(plik);
//=================================================================================================================================
j = 0;
plik2 = fopen("tekst_1.txt", "r");
if (plik2 == NULL)
{
printf("Niestety nie udało się otworzyć tekstu 1.");
return 1;
}
printf("\n\n============ Tekst 1 z zaznaczonym pierwszym wystąpieniem znaku \"%c\" ================\n\n", szukany);
szukany_napis[0] = szukany;
szukany_napis[1] = '\0';
printf(" %d ", enter);
//rewind(plik2);
while ((znak = fgetc(plik2)) != EOF)
{
if (Czy_Enter == 1)
{
printf("%3d ", enter);
Czy_Enter = 0;
}
x++;
if ((strchr(szukany_napis, znak) != NULL) && j < 1)
{
j++;
i1 = i;
enter1 = enter;
x1 = x;
printf("[ => %c <= ]", znak);
continue;
}
if (znak == '\n')
{
enter++;
Czy_Enter = 1;
x=0;
}
printf("%c", znak);
i++;
}
if (j != 1) printf("\n\nBRAK ZAZNACZENIA - BRAK ZNAKU!");
printf("\n\n================================== Informacje ===================================\n\n");
if (j == 1) printf("Znaleziono znak \"%c\" w tekście 1.\nWiersz: %d\nPozycja w wierszu: %d\nPozycja w całym tekście: %d\n\n", szukany, enter1, x1-1, i1 - enter1);
else printf("Niestety nie znaleziono znaku \"%c\" w tekście 1.\n\n", szukany);
fclose(plik2);
return 0;
}
Próbowałem już wielu rzeczy i nadal jest ten sam efekt, a mianowicie taki, że wyświetlanie polskich znaków poprzez np. "printf("Wybierz jeden z powyższych znaków Tekstu 2 aby znaleźć pierwsze jego wystąpienie w Tekście 1:\n");" działa bez zarzutów ale w momencie, w którym chcę wyświetlić zawartość notatnika, w którym występują polskie znaki to pojawią się krzaczki. Próbowałem również zapisywać treść notatnika z kodowaniem UTF-8, niestety nadal bez rezultatów.
Poniżej zawartości plików tekst_2.txt oraz tekst_1.txt
(tekst_2.txt)
abcde 4356
fg h123
ijQ OPVB
k? !$
x %^ mp
ółżń
(tekst_1.txt)
Na pokładzie samolotu Greene zawiera umowę z CIA, w ramach której w zamian za dostęp do ropy Stany Zjednoczone nie sprzeciwią się przewrotowi w Boliwii. W Austrii Greene uczestniczy w przedstawieniu Toski Pucciniego w operze w Bregencji. Bond podąża jego tropem, w operze zabija członka organizacji i kradnie mu nadajnik do porozumiewania się z terrorystami. W rzeczywistości przedstawienie Toski jest przykrywką dla spotkania członków organizacji o nazwie Quantum. Terroryści omawiają najważniejsze sprawy dotyczące ich globalnych operacji. Bond przerywa spotkanie i robi zdjęcie uciekającym członkom Quantum, które wysyła do M. Wśród spiskowców jest Guy Haines – zaufany doradca premiera Wielkiej Brytanii. W trakcie ucieczki z opery Bond rzekomo zabija agenta służb specjalnych, ochraniającego Hainesa. Z tego powodu M nakazuje sprowadzić agenta 007 z powrotem do siedziby MI6[1][4].