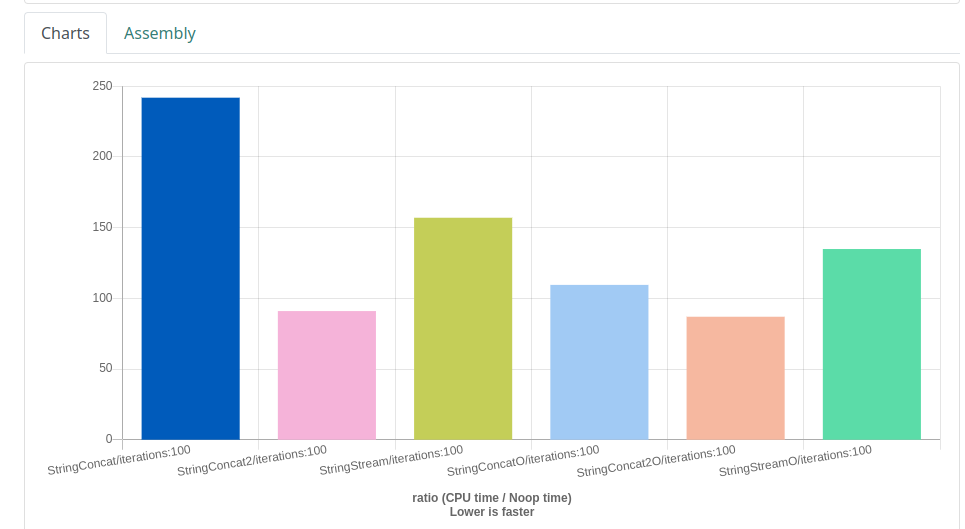
Czy jest jakiś sposób, by kompilator zamieniał
std::cout << "test" << " " << "2" << "\n";
na
std::cout << "test 2\n";
czy też
std::string s_1 = "a";
s_1 += "b";
std::string s_2 = "z";
s_1 += "cdefghijklmnopqrstuvwxy";
s_1 += "bcdefghijklmnopqrstuvwxy";
s_1 += "abcdefghijklmnopqrstuvwxy";
s_1 += "cdefghijklmnopqrstuvw";
s_1 += "cdefghijklmnopqrstuvwxy";
s_1 += "cdefghijklmnopqrstuvwxyz";
na
std::string s_1 = "abcdefghijklmnopqrstuvwxybcdefghijklmnopqrstuvwxyabcdefghijklmnopqrstuvwxycdefghijklmnopqrstuvwcdefghijklmnopqrstuvwxycdefghijklmnopqrstuvwxyz";
std::string s_2 = "z";
?
I która opcja szczegółowa odpowiada za optymalizację tego drugiego w -O3 do postaci kopiowania pamięci?
A może w C++ dane i tak byłyby wrzucane na stos?
To jest przykład większego problemu polegającego na wcześniejszym przydzieleniu pamięci na dane i późniejszym składowaniu tych danych, a zapisie wszystkiego przy pomocy różnych operatorów.
W C można by zapisać tak, przedzielając dowolnymi instrukcjami.
char *s = ( char * )malloc( 10 + 1 );
strcpy( s, "abc" );
strcpy( s + 3, "def" );
strcpy( s + 3 + 3, "ghij" );
Ale to powyższe nie jest bezpieczne, ze względu na użycie liczb zależnych od tekstów. Dlatego pytam o operatory.