Witam szanowną społeczność,
Dziś próbowałem rozwiązać kilka zadań z programowania. Niestety wyniki nie pokrywają się z 'poprawnymi' odpowiedziami. Poprawnymi dałem w apostrofy, ponieważ nie do końca zgadzam się z werdyktem sędziego.
Byłbym wdzięczny za zerknięcie w kod, gdyż problem jest trywialny dla osób, które obcują już trochę z algorytmiką. Dodałem także komentarze, aby kod był przejrzysty dla czytelników zewnętrznych, czyli dla Was. Zapraszam do zapoznania się z treścią a następnie z kodem. Dziękuję z góry za komentarze, odpowiedzi i rady.
Zadanie: link
Mój kod:
#include <bits/stdc++.h>
using namespace std;
char arr[5][5];
int row[200]; //tablica przechowująca rząd litery, np. wartość row['A'], czyli row[65] będzie równa wierszowi w tablicy dwuwymiarowej arr
int col[200]; //analogicznie tylko dla komulmn
bool let(char c) {
return (c >= 'A' and c <= 'Z'); //zwraca true, gdy znak jest dużą literą
}
int main() {
string alp; cin >> alp; //wczytanie alfabetu
int k = 0; //zmienna pomocnicza
for (int i = 0; i < 5; i ++) {
for (int j = 0; j < 5; j ++) {
//wczytywanie kolejnych liter apl[k] do tablicy arr[i][j] oraz zapisanie numerów wiersza i kolumny
arr[i][j] = alp[k ++];
col[arr[i][j]] = j;
row[arr[i][j]] = i;
}
}
string str;
getline(cin, str); //pozbycie sie bufora '\n' z cin'a
getline(cin, str); //wczytanie zaszyfrowanej wiadomości
char x, y; // zmienne pomocnicze (str[i] zajmuje wiecej miejsca niz x albo y jesli chodzi o zapis i kod jest czytelniejszy)
for (int i = 0; i < str.size() - 1;) {
x = str[i]; y = str[i + 1];
//kolejne warunki (tutaj nie ma co wyjasniac, wystarczy przeczytac tresc zadania :D)
if (let(x) and let(y)) {
if (row[x] == row[y]) {
str[i] = arr[row[x]][(col[x] + 4) % 5];
str[i + 1] = arr[row[y]][(col[y] + 4) % 5];
}
else if (col[x] == col[y]) {
str[i] = arr[(row[x] + 4) % 5][col[x]];
str[i + 1] = arr[(row[y] + 4) % 5][col[y]];
}
else {
str[i] = arr[row[x]][col[y]];
str[i + 1] = arr[row[y]][col[x]];
}
//nie zwiekszam i za kazdym razem, wiec musze przesunac o 2 za kazdym razem, gdy odszyfruje jakies 2 litery
i += 2;
}
//jezeli napotkam na spacje, inkrementuje i
else i ++;
}
cout << str;
}
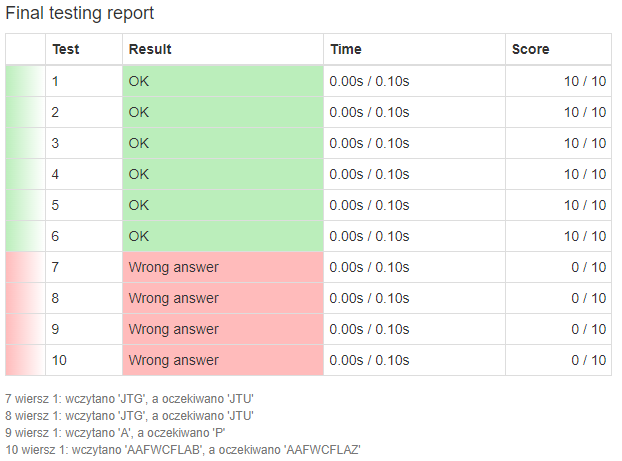
Testy, które nie przeszły:
7 wiersz 1: wczytano 'JTG', a oczekiwano 'JTU'
8 wiersz 1: wczytano 'JTG', a oczekiwano 'JTU'
9 wiersz 1: wczytano 'A', a oczekiwano 'P'
10 wiersz 1: wczytano 'AAFWCFLAB', a oczekiwano 'AAFWCFLAZ'
Opcjonalnie w postaci wizualnej: