Cześć.
Tworzę moduł zadań i jestem na etapie projektowania tabel:
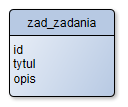
Chcę, aby użytkownik mógł powiązać z każdym zadaniem kilku klientów. Stworzyłem więc drugą tabelę:

... i teraz pytanie - czy ta druga tabela powinna zawierać swoje własne id? W końcu nie ma ona żadnych pól, które trzeba edytować. Jeśli użytkownik zmieni listę klientów, to będę mógł po prostu usunąć wszystkie powiązania dla danego zadania:
DELETE FROM zad_zadaniaKlienci WHERE idZadanie = @idZadanie;
i później dodać wszystkie elementy jeszcze raz.
Boje się, że przez dużą ilość zadań i klientów, nastąpi overflow ID (... proszę o wyrozumiałość, to moja pierwsza większa aplikacja : )
Z góry dzięki
