Hej, dopiero zaczynam swoją przygodę z PostgreSQL i mam mały zadaniowy problem.
Jest taka sytuacja, że muszę obliczyć łączoną sumę czasów (elementów) oddzielnie dla każdej z grup gdzie każda składa się ze swoich elementów.
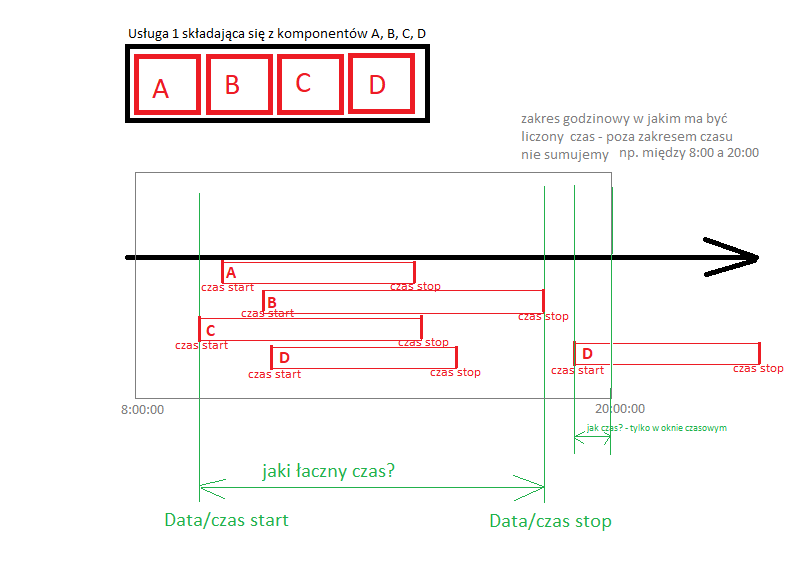
Czyli mamy element z pewnym czasem trwania obliczonym na podstawie czasu start i stop (czas trwania = czas stop - czas start). Teraz muszę posumować odpowiednie elementy (w zależności od tego jaką grupę biorę pod uwagę) ale tak, żeby czasy występowania się nie duplikowały i dodatkowo znajdowały się w przedziale czasowym jaka każda z grup ma nałożoną z góry (tylko w tym oknie czasowym elementy powinny sie sumować). Tak myślę, że muszę te elementy nałożyć na swego rodzaju oś czasu i obliczyć różnice między czasem start a czasem stop krańcowych elementów ale nie mam pojęcia jak to zapisać w PostgreSQL (dodam może prowizoryczny rysunek o co mi chodzi).
Problem polega na tym, że każda dana (okna czasowe grup, jakie elementy składają się na grupę, czasy strat/stop każdego elementu) znajduję się w innej tabel w bazie powiązanej odpowiednimi relacjami.
Na ten moment udało mi się jakoś wyciągnąć do oddzielnej tabeli daną grupę z jej elementami, czasem trwania niedostępności danego elementu i oknem czasowym grupy ale nie mam pojęcia jak obliczyć sumę tych elementów dla całej grupy tak aby uwzględnić te moje parametry o oknie czasowym i o nie duplikowaniu się czasu.
Mam nadzieję, że dobrze to opisałam.
Może mogłabym Was prosić o pomoc, wskazówki jak podejść do tego rozwiązania i to obliczyć (łączny czas zaznaczony na zielono na rysunku)?