Cześć,
Jeśli mamy relacje między dwiema tabelami i chcemy wydobyć z nich dane to robimy JOIN-a.
Zastanawiam się jednak czy są sytuacje, kiedy lepszym rozwiązaniem jest zrobienie dwóch niezależnych selektów? Tj. najpierw wydobyć dane z pierwszej tabeli a następnie drugim SELECT-em wydobyć dane z drugiej tabeli?
Czy w praktyce są sytuacje, gdy to ma sens, a jeśli tak to od czego jest to uzależnione?
0
3
To nie ma sensu jeśli potrzebujesz danych z obydwu tabel.
1
Kofcio napisał(a):
Cześć,
Jeśli mamy relacje między dwiema tabelami i chcemy wydobyć z nich dane to robimy JOIN-a.
Zastanawiam się jednak czy są sytuacje, kiedy lepszym rozwiązaniem jest zrobienie dwóch niezależnych selektów? Tj. najpierw wydobyć dane z pierwszej tabeli a następnie drugim SELECT-em wydobyć dane z drugiej tabeli?
Czy w praktyce są sytuacje, gdy to ma sens, a jeśli tak to od czego jest to uzależnione?
Tylko jeśli chciałbyś joinować po czymś, czego nie można wyrazić w SQL'u (np po mapie której nie ma w bazie)
2
Jeśli nie potrzebowałbyś wszystkich danych dla wszystkich wierszy to może czasem miało by to sens. Ale nie ma sensu kombinować jeśli zwykły JOIN daje radę i jest wydajny. Jeśli nie będzie wydajny to wtedy można się martwić (jak potwierdzimy, że to konkretne zapytanie jest problematyczne)
Jedyny przykład jaki mi przychodzi do głowy do sytuacja gdy chcesz pobrać ostatni wiersz (sortując wszystko). Jeśli zrobisz to na joinie na dwóch dużych tabelach (miliony rekordów) to dostaniesz timeout. W takim w wypadku robisz zapytanie o ostatni wiersz w pierwszej tabeli i dostajesz konkretny wiersz i możesz zapytać o niego w drugim zapytaniu
1
Kofcio napisał(a):
Cześć,
Jeśli mamy relacje między dwiema tabelami i chcemy wydobyć z nich dane to robimy JOIN-a.
Zastanawiam się jednak czy są sytuacje, kiedy lepszym rozwiązaniem jest zrobienie dwóch niezależnych selektów? Tj. najpierw wydobyć dane z pierwszej tabeli a następnie drugim SELECT-em wydobyć dane z drugiej tabeli?
Czy w praktyce są sytuacje, gdy to ma sens, a jeśli tak to od czego jest to uzależnione?
Jeśli warunki biznesowe są dziwne, to wyobrażam sobie, że dla łatwości utrzymania zapytań (choć gorzej ze względów wydajnościowych), może tak faktycznie być.
Np. w jednej tabeli mamy np. (id_elementu, id_grupy), w drugiej (id_elementu, badana_wartość) i chcemy dla grupy o konkretnym id zwracać:
- max(badana_wartosc), jeśli liczebność grupy jest <=3
- medianę(badana_wartosc) gdy liczebność grupy jest (3, 50]
- średnią arytmetyczną(badana_wartosc) dla innych przypadków.
0
anonimowy napisał(a):
Jeśli nie potrzebowałbyś wszystkich danych dla wszystkich wierszy to może czasem miało by to sens.
Mozesz rozwinąć?
0
Ok, dziękuję za wasze odpowiedzi.
Ogólnie to również tak mi się wydawało, ale wolałem to jeszcze potwierdzić.
Moje wątpliwości wynikały z faktu, że jak mamy JOIN to wiele danych może się powtarzać (Na każdą pozycję z drugiej tabeli mam powtórzone dane z pierwszej) przykładowo, jak np. w pierwszej tabeli mam jakieś dane nagłówkowe dokumentu (np. faktury tj. numer, data, podsumowanie etc.) a w drugiej tabeli mam listę pozycji na tej fakturze (towar, ilość, cena itd.) to jak chcę pobrać cały dokument i robię JOIN obu tabel to dla każdej pozycji faktury mam również dane nagłówkowe. Więc jak mam bardzo dużo pozycji na fakturze to mam również bardzo wiele powtórzonych danych nagłówkowych.
Z drugiej strony zakładam, że to i tak są tylko referencje do jednego obiektu więc koszt takich zdublowanych pozycji raczej nie jest duży...
2
Kofcio napisał(a):
Ok, dziękuję za wasze odpowiedzi.
Ogólnie to również tak mi się wydawało, ale wolałem to jeszcze potwierdzić.
Moje wątpliwości wynikały z faktu, że jak mamy JOIN to wiele danych może się powtarzać (Na każdą pozycję z drugiej tabeli mam powtórzone dane z pierwszej) przykładowo, jak np. w pierwszej tabeli mam jakieś dane nagłówkowe dokumentu (np. faktury tj. numer, data, podsumowanie etc.) a w drugiej tabeli mam listę pozycji na tej fakturze (towar, ilość, cena itd.) to jak chcę pobrać cały dokument i robię JOIN obu tabel to dla każdej pozycji faktury mam również dane nagłówkowe. Więc jak mam bardzo dużo pozycji na fakturze to mam również bardzo wiele powtórzonych danych nagłówkowych.
Z drugiej strony zakładam, że to i tak są tylko referencje do jednego obiektu więc koszt takich zdublowanych pozycji raczej nie jest duży...
No to jeśli się martwisz spadkiem wydajności z uwagi na to że wczytujesz zduplikowane dane, to na pewno rozwiązaniem na to nie są dwa selecty. Algorytmy używane w bazie danych do połączenia dwóch tabel, zwłaszcza jeśli te tabele mają indexy na klucze główne, są dużo bardziej wydajne niż jakikolwiek algorytm który Ty byś napisał do połączenia tych dwóch selectów w swoim języku programowania.
Innymi słowy - zrób to normalnie, nie cuduj.
Jesli są już problemy z wydajnością zapytań, to raczej właśnie to że leci dużo query zamiast jednego.
3
Robiąc oddzielnie dwa zapytania i łącząc ich wyniki skutecznie ucinasz silnikowi bazodanowemu możliwość ich optymalizacji. Optymalizatory zapytań przeważanie dobrze działają.
Dodatkowo, ucinasz adminowi bazy możliwość poprawienia planu zapytania, w przypadkach gdy optymalizator nie podołał wyzwaniu.
Scenariusze, gdzie dwa zapytania mogą (ale nie muszą) być lepszym wyborem, to złożone konfiguracje z rozproszonymi bazami danych, np. aplikacja po podłączeniu do bazy "widzi tabele", ale są one umieszczone na różnych serwerach w różnych technologiach (= serwer, do którego się łączysz robi za bramkę do innych baz), czy złożone modele (np. w tabeli masz trzymasz obiekty typu XMLe, JSONy) i chcesz robić złączenia po elementatch wyciągnietych z takiego JSON/XMLa (tu nie zawsze planista sobie dobrze radzi).
4
Jeżeli pojedyncze zapytanie może rozwiązać problem, to należy go użyć bo:
- baza danych znacznie wydajniej wykona to złączenie. Robiąc na piechotę uniemożliwiasz pracę optymalizatorowi.
- pobierzesz tylko dane, które chcesz pobrać, a I/O to wąskie gardło baz danych
2
Chodzmi mi o taki przykład:
https://www.db-fiddle.com/f/5D9M8TkSBcY6Tcm7VGSfcn/0
Gdzie chcesz zdobyć ostatnią osobę po sortowaniu po danej kolumnie (w tym przypadku ID) i jednocześnie pobrać jej miasto. Można od razu pobrać miasto za pomocą joina w takim w wypadku join jest wykonywany na dwóch całych tabelach. Jeśli są duże to dostaniemy timeout. Można w takim wypadku zrobić dwa oddzielne query, które zadziałają błyskawicznie.
W podanym przykładzie po explain analyze już widać różnicę, oczywiście czasy przy tylu danych są niewielkie to w czasach jej nie widać, ale jak zrobimy sobie miliony wierszy to będzie to jasne.
6
Łopanie. Ale zjebany przykład. Po pierwsze primo - brak indeksów. Faktycznie możesz się nie doczekać wyników. Z indeksami śmiga jescze lepiej, choć dla małych tabel nie powinien ich brac, bo się zwyczajnie w świecie nie opłaca.
Po drugie, ja bym to zrobił troszkę inaczej...
https://www.db-fiddle.com/f/fuyZx7KW63QR51VMTNBsN2/1
EDIT: zmiana linka
2
Sortowanie, żeby pobrać pierwszy, czy tam ostatni rekord jest bez sensu...
Robienie bazy bez indeksów i marudzenie, ze plan zapytania nie taki też jest bez sensu..
Puszczanie planu zapytania na bazie bez danych również jest bez sensu.
Jeżeli przy prawidłowo założonych indeksach optymalizator sobie nie poradzi, nadal te 2 zapytania można efektywnie złożyć w jedną komendę. Tak dla przykładu:
#VS
explain analyze
select
person.last_name, profile.city
from person left join profile on person.id = profile.person_id
where person.id = (select max(id) from person);
0
Od kiedy to ktos pisze takie SQL ręcznie? Głównie używa się ORM, który w większości przypadków zrobi to w ten sposób, który ja pokazałem. Indeksy to podstawa więc to pomijam bo to inny temat.
Skupiłeś się na sortowaniu po ID gdzie to sortowanie może być po dowolnej kolumnie. Przecież to oczywiste, że można to napisać w inny sposób. Chciałem po prostu pokazać klasyczną pułapkę jaką tworzą ORMy i najprostsze w takich przypadkach jest rozbicie tego na dwa zapytania zamiast schodzić do poziomu SQLa
3
anonimowy napisał(a):
Od kiedy to ktos pisze takie SQL ręcznie?
Ostanie 18 lat prawie nic innego nie robię.
0
@anonimowy: Dzięki za przykład, ale tak jak pisał @Marcin.Miga model jest zrypany.
Po dodaniu PK, FK i indeksu ostatnie zapytanie działa ok.
https://www.db-fiddle.com/f/5D9M8TkSBcY6Tcm7VGSfcn/1
alter table person add primary key (id);
alter table profile add primary key (id);
alter table profile add foreign key (person_id) references person(id);
create index profile_person_id on profile(person_id);
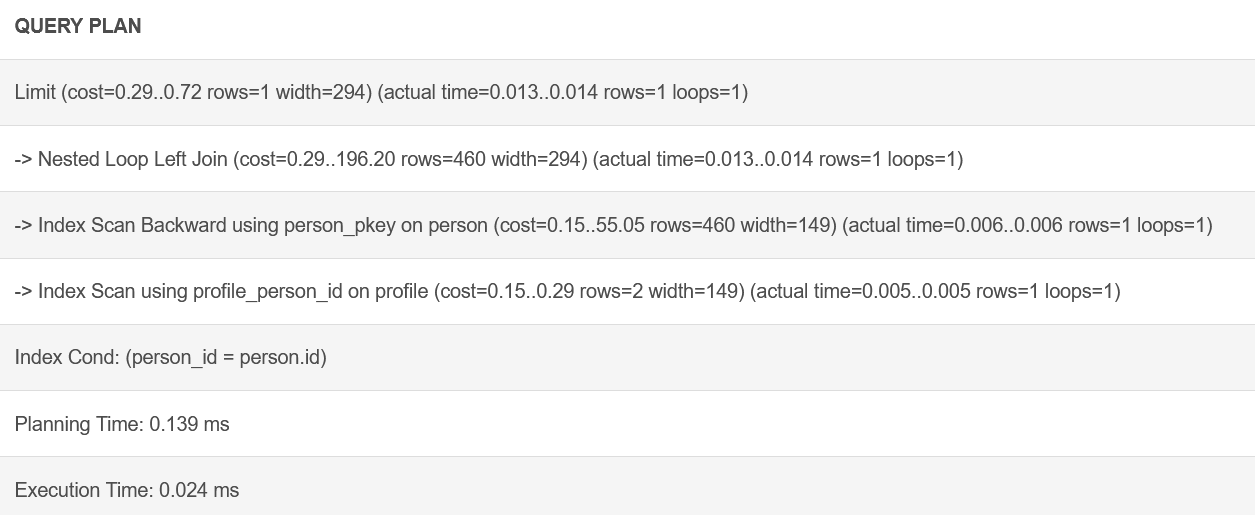
- Robi nested loopa (1 przebieg dla rekordu z max. PERSON_ID)
- Skanuje primary key od końca (masz wówczas max PERSON_ID praktycznie w jednym odczycie bloku)
- Do złączenia używa indeksu na PROFILE.
Samo zapytanie wygenerowane przez ORMa (tak rozumiem tłumaczenia w poprzednich postach i komentarzach) nie jest złe. Słaby jest model danych, a tu raczej trzeba winę zwalić na developerów, a nie ORMa.
3
@anonimowy: Zdecyduj się, podałeś przykład w którym model jest zrypany i to nie ma znaczenia, bo ORM by tam "sam" dodał potrzebne indeksy, ale już faktu, że na tych dodanych indeksach zapytania działałyby inaczej nie dostrzegasz. Pomijając już dość absurdalny przykład, w którym 2 osobne zapytania działają szybciej (a to i tak nadużycie, bo te wartości podawane są "netto"), niż jedno źle napisane zapytanie, pomijasz też fakt, że plan wykonania zapytania zmienia się wraz z ilością danych w tabelach i to co zmierzysz dla złączenia 2 tabel po 5 rekordów nie ma nic wspólnego ze złączeniem tabel po kilka milionów rekordów. Wbudowany w silnik optymalizator się dostosuje, zapisana na twardo w kodzie logika dotarcia do danych nie dostosuje się do tych zmian.
0
@piotrpo No to sobie sprawdź na realnych danych. Ja podałem realny przykład z normalnym modelem danych. To, że pominąłem indexy nie ma znaczenia bo nadal dostajesz timeout na tym query
1
@anonimowy: Ale o czym to niby świadczy poza "zapytanie jest do d**y"?
0
To, że to realny przykład z realnego projektu, z którego być może korzystasz na co dzień. Co teraz próbujesz udowodnić bo nie bardzo rozumiem? Podałem przykład, gdzie JOIN może nie być optymalny a Ty piszesz, że nie jest optymalny? No dlatego go podałem
0
anonimowy napisał(a):
Podałem przykład, gdzie JOIN może nie być optymalny a Ty piszesz, że nie jest optymalny? No dlatego go podałem
A możesz podać plan zapytania z produkcji dla takiego zapytania z JOINem? To, że leci timeout nie musi przecież wynikać z JOINa, a konfiguracji bazy czy specyfiki workloadu.
Intuicyjnie rzecz biorąc , przy milionach rekordów powinien zrobić reverse index scan na PK pierwszej tabeli, a później po indeksie znaleźć pasujące rekordy z profile. Jeśli jest inny plan zapytania, to coś może być nie tak z optymalizatorem (bug, brak statystyk,...) albo przykładem (produkcyjnie ten join wygląda zupełnie inaczej).
3
Dobra, stworzyłem 1m rekordów na DB fiddle:
Z indeksami: https://www.db-fiddle.com/f/5D9M8TkSBcY6Tcm7VGSfcn/2
Bez indeksów: https://www.db-fiddle.com/f/5D9M8TkSBcY6Tcm7VGSfcn/3
Wariant z indeksami - query 1ms
Wariant bez indeksów - query - 1001ms
Czyli x1000 wolniej. Jak dorzucisz te 100 razy więcej rekordów to będzie 100MLN rekordów.
Z indeksami -> 100ms, bez indeksów -> 1001*100 ~ 100 sekund -> timeout (przy założeniu, że domyślny timeout został ustawiony na mniej niż 100 sek). W wolnej chwili odpalę postgresa w dockerze na VM i dorzucę fizycznie te rekordy dla podanych wariantów.
Podejrzewam, że będzie podobne róznica między wariantem z indeksami i bez indeksów.
Powyższe pokazuje tylko tyle, że timeouty możecie mieć, bo macie zrypany model bazodanowy. Dlatego pytałem jak u Was wygląda plan zapytania dla tego joina.
0
@yarel:
Dzięki za przykład. A co w takim przypadku?
https://www.db-fiddle.com/f/trMUsve8sMegkcTsEuUg9k/0
Chcę ostatnią osobę, która nie ma wypełnionego profilu (profil nie istnieje, is null)
0
anonimowy napisał(a):
@yarel:
Dzięki za przykład. A co w takim przypadku?
https://www.db-fiddle.com/f/trMUsve8sMegkcTsEuUg9k/0Chcę ostatnią osobę, która nie ma wypełnionego profilu (profil nie istnieje, is null)
Podany przypadek wydaje mi się mało realistyczny, ale być może to kwestia mojego braku wiedzy o dziedzinie problemu. Dany model fizyczny nie wspiera wydajnego odpytywania o "ostatnią osobę, która nie ma wypełnionego profilu". Najprościej byłoby trzymać tę informację na poziomie "person", np. atrybut "profile_created", który byłby aktualizowany przy tworzeniu profilu. Do tego indeks częściowy (partial index) dla wierszy z profile_created is null.
Od strony modelu danych można partycjonować zakresami PERSON po ID, a PROFILE po PERSON_ID + skonfigurować postgresa, by używał puli X workerów, tak by takie joiny leciały w parallelu. Może zadziała może nie :-)
Jakie masz alternatywy dla powyższego przypadku?
1
Przy relacji 1..1 najprościej jest trzymać dane w jednej tabeli. Jeżeli konieczne jest sprawdzanie kto jest ostatnim użytkonikiem bez profilu, prawdopodobnie efektywnie dla odczytu będzie dodać indeks złożóny na pola user_id, some_profile_field i odpytywać select max(user_id) from users where some_profile_field is null.
Natomiast przy modelu jak w przykładzie i dużej liczbie rekordów w tabeli profile 2 zapytania będą skrajnie nieefektywne, bo właściwie co? Pobrać prawie milion profili, pobrać milion person, co już będzie trwało wieki i lokalnie szukać różnicy zbiorów?
0
No zgadzam się z wami, że zapytanie jest nieefektywne. Nie zgadzam się natomiast z tym, że pierwsza tabela powinna zawierać informacje o drugiej. Jest wiele powodów dla, których można użyć relacji jeden do jednego i tutaj taki powód był.
To zapytanie da się ogarnąć na kilka sposobów natomiast ja chciałem pokazać, że czasem taki join może zaboleć jeśli nie przewidzimy pewnych kwestii