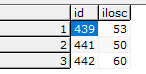
 - to są pobrania dla magazynu gdzie nasze id jest unikalne (439, 441, 442)
- to są pobrania dla magazynu gdzie nasze id jest unikalne (439, 441, 442)
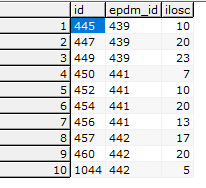 - to są z kolei wydania, epdm_id odpowiadają id z pobrań
- to są z kolei wydania, epdm_id odpowiadają id z pobrań
Muszę sprawdzić czy rozliczenia są prawidłowe tj. Pobrania(439 - 53 szt) = wydania(445,447 i 449 - 53szt) jeżeli nie to muszę zaznaczyć że dla tego ID.pobrania = 239 coś jest nie tak.
Męczyłem się z tym dzisiaj cały dzień tworząc pętle podwójne, tabele indeksowaną... ale zawszę mi coś się nie zgadzało
-Te dane są pobierane z tej samej tabeli
- Grupowanie po ID i wykoanie różnicy pomiędzy pobrania.Id i wydania.epdm_id nie daje zamierzonego efektu. Chcę przyrównać do pobrania.ID każdy rekord z wydania.epdm_id
Proszę o jakieś sugestie.
Pozdrawiam.