Witam, walczę z zapytaniem w bazie danych i niestety muszę prosić o pomoc.
Generalnie jest to zapytanie, które wstawia odpowiednie ilości punktów do bazy danych na podstawie danych z innej tabeli. Poniżej wstawiam fragment odpowiedzialny za wyciągnięcie wartości.
SELECT
wp.user_id,
UNIX_TIMESTAMP(s.payment_date) as time,
(SUM(s.net_value) DIV 100) * (p.points_per_chunk - main_p.points_per_chunk) as creds,
IF(s.status = 1,
CONCAT("Punkty ", s.manufacturer, ": ", s.invoice_id),
CONCAT("Punkty 2 ", s.manufacturer, ": ", s.invoice_id)
) as entry,
IF(s.status = 1, "reward", "future_reward") as ref,
s.invoice_id as ref_id
FROM
pop_sales s
LEFT JOIN wp_usermeta wp ON wp.meta_key = "nip" AND wp.meta_value = s.nip
RIGHT JOIN pop__promotions p ON p.manufacturer LIKE CONCAT("%", s.manufacturer, "%")
LEFT JOIN pop_promotions main_p ON s.payment_date BETWEEN main_p.start_date
AND IF(main_p.end_date IS NULL, NOW(), main_p.end_date)
LEFT JOIN wp_users wpu ON wp.user_id = wpu.ID
WHERE wp.user_id IS NOT NULL
AND s.payment_date BETWEEN p.start_date AND p.end_date
AND wpu.user_registered < s.payment_date
AND main_p.manufacturer IS NULL
GROUP BY s.manufacturer
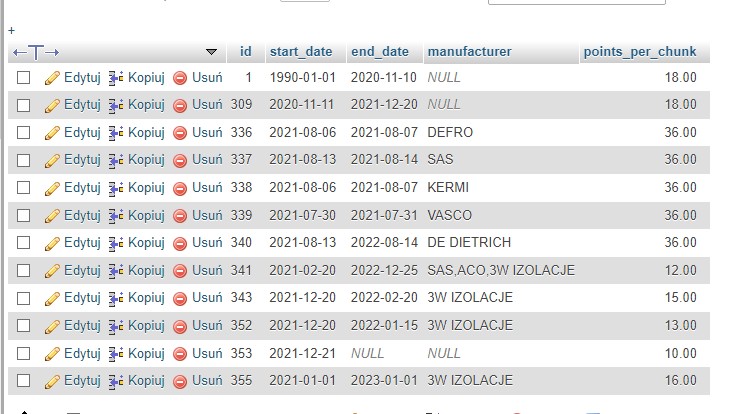
Samo w sobie zapytanie działa, ale pojawia się jeden problem, który sprowadza się do tego fragmentu:
RIGHT JOIN pop_promotions p ON p.manufacturer LIKE CONCAT("%", s.manufacturer, "%")
Otóż wyciąga ono z tabeli wiersze, które zawierają daną nazwę firmy i odpowiadającą im ilość punktów. Problem w tym, że wierszy z daną firmą może być kilka. Co więcej, jeden wiersz może zawierać listę składającą się z kilku firm. Chciałbym jednak wyciągnąć ten wiersz, który ma największą ilość punktów. Niestety ani przez SELECT MAX(), ani przez sortowanie i wyciąganie jednej wartości lub grupowanie nie byłem w stanie tego zrobić. Grupowanie chyba nie zda tu egzaminu, bo nawet jak jedna firma występuje kilka razy, to może ona być w wierszy z innymi firmami. Poniżej jeszcze zrzut wyglądu tej tabeli: