Witam,
Także wątek przesunięty z innego tematu bo się bałagan zrobił z mojej winy.
Problem: przez złą implementacje nowej kolumn w tablicy gdzie są zapisywane dane historyczne dla kodów towarowych zostały wstawione zdublowane kody. Tj. wszystkie kolumny są takie same oprócz dat ValidFrom i ValidTo.
Chcę wyczyścić tą sytuację i znaleźć, oznaczyć grupy dubli - pobrać sobie odpowiednie daty startu i końca (min(ValidFrom) i max(ValidTo) dla danej grupy obok siebie. Później usunąć zdublowane kody zostawiając 1 - (np. pierwszy) i zaktualizować tylko kolumnę ValidTo.
Wczoraj wydawało się, że mi się udało na probie 6 różnych kodów ... dziś na kolejnej grupie wyszło, że się myliłem. Mam inne obejście tematu poprzez LEFT JOIN. Ale czuje że można to zrobicsprytniej przy użyciu ROW_NUMBER czy RANK (tak właśnie wczoraj robiłem) ale coś mi nie wychodzi to :|
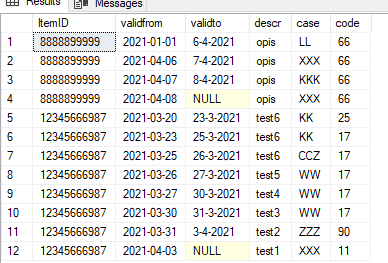
Meritum: Mamy kod ID i daty ValidFrom i ValidTo - i skończoną ilość dalszych kolumn oznaczających wartości w danym przedziale. Jak oflagować - np policzyć ilość występujących po sobie (w szeregu) takich samych rekordów (dubli) zakładając, że sortujemy Po ItemID i ValidFrom. (Dubel jest gdy wszystkie kolumny są takie same oprócz dat) .
Próbka danych (także w załączniku) :
12345666987 9-4-2021 NULL test1 XXX 11
12345666987 8-4-2021 9-4-2021 test1 XXX 11
12345666987 7-4-2021 8-4-2021 test1 XXX 11
12345666987 6-4-2021 7-4-2021 test1 XXX 11
12345666987 5-4-2021 6-4-2021 test1 XXX 11
12345666987 4-4-2021 5-4-2021 test1 XXX 11
12345666987 3-4-2021 4-4-2021 test1 XXX 11
12345666987 2-4-2021 3-4-2021 test2 ZZZ 90
12345666987 1-4-2021 2-4-2021 test2 ZZZ 90
12345666987 31-3-2021 1-4-2021 test2 ZZZ 90
12345666987 30-3-2021 31-3-2021 test3 WW 17
12345666987 27-3-2021 30-3-2021 test4 WW 17
12345666987 26-3-2021 27-3-2021 test5 WW 17
12345666987 25-3-2021 26-3-2021 test6 CCZ 17
12345666987 23-3-2021 25-3-2021 test6 KK 17
12345666987 20-3-2021 23-3-2021 test6 KK 25
8888899999 9-4-2021 NULL opis XXX 66
8888899999 8-4-2021 9-4-2021 opis XXX 66
8888899999 7-4-2021 8-4-2021 opis KKK 66
8888899999 6-4-2021 7-4-2021 opis XXX 66
8888899999 1-4-2021 6-4-2021 opis LL 66
8888899999 1-1-2021 1-4-2021 opis LL 66
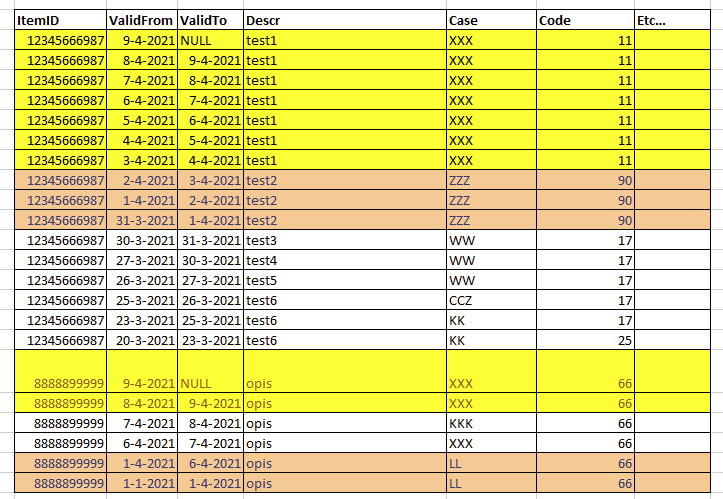
Wizualizacja przykładu:
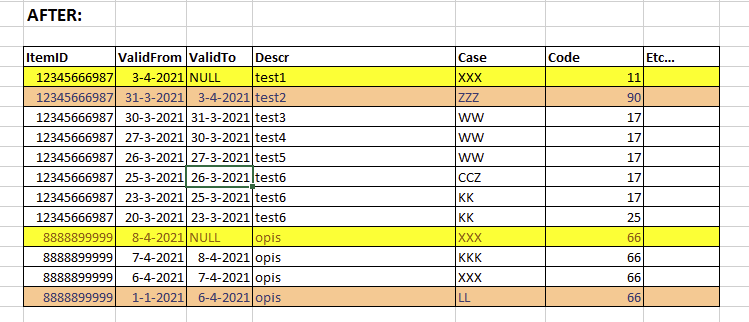
Edit: tak by to miało wyglądać po poprawie:
Example.txt