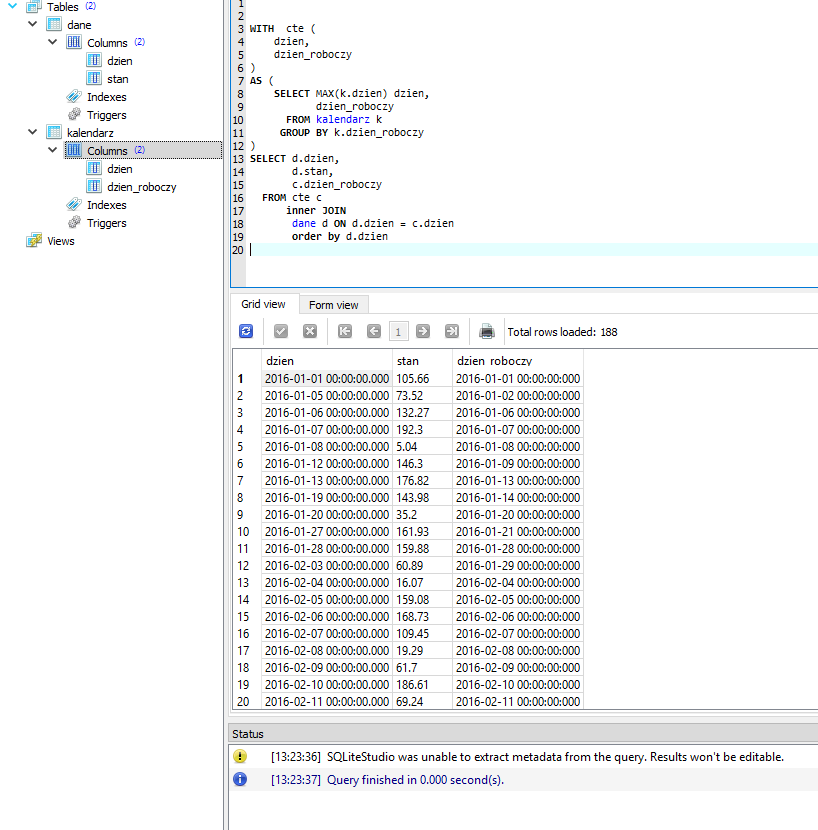
RANK() w sqllite powinien dzialac bez problemu ;)
update -> https://sqliteonline.com/#fiddle-5d0a41fd98b71mzxjx3bbf2y
SET DATEFORMAT DMY;
DECLARE @dane TABLE
(
dzien DATETIME ,
stan MONEY
);
DECLARE @kalendarz TABLE
(
dzien DATETIME ,
dzien_roboczy DATETIME
);
INSERT INTO @kalendarz
VALUES ( '29/04/2019', '29/04/2019' ) ,
( '30/04/2019', '30/04/2019' ) ,
( '01/05/2019', '02/05/2019' ) ,
( '02/05/2019', '02/05/2019' ) ,
( '03/05/2019', '02/05/2019' ) ,
( '04/05/2019', '02/05/2019' ) ,
( '05/05/2019', '02/05/2019' ) ,
( '06/05/2019', '06/05/2019' ) ,
( '07/05/2019', '07/05/2019' );
INSERT INTO @dane
VALUES ( '29/04/2019', 795.29 ) ,
( '30/04/2019', 117.44 ) ,
( '01/05/2019', 400.45 ) ,
( '02/05/2019', 391.09 ) ,
( '03/05/2019', 197.55 ) ,
( '04/05/2019', 357.61 ) ,
( '05/05/2019', 168.88 ) ,
( '06/05/2019', 930.18 ) ,
( '07/05/2019', 826.36 );
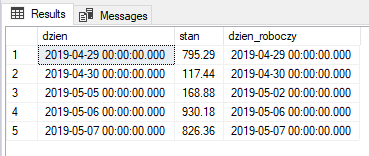
SELECT t.dzien ,
t.stan ,
t.dzien_roboczy
FROM ( SELECT d.dzien ,
d.stan ,
k.dzien_roboczy ,
RANK() OVER ( PARTITION BY k.dzien_roboczy
ORDER BY d.dzien DESC ) score
FROM @dane d
LEFT JOIN @kalendarz k ON k.dzien = d.dzien ) AS t
WHERE t.score = 1;