Rozdział 13. Obsługa formatu XML.
Adam Boduch
XML jest stosunkowo nową technologią zaproponowaną przez największe firmy informatyczne (Microsoft i Borland) jako nowy standard przechowywania i wymiany informacji.
XML jest skrótem od słów eXtensible Markup Language, co oznacza rozszerzalny język znaczników. Został opracowany przez W3C (ang. World Wide Web Consorcium).
HTML (ang. HyperText Markup Language) jest językiem znaczników opisującym strukturę dokumentu WWW. Projektant, aby utworzyć stronę WWW, musi zapisać pewne z góry określone polecenia, tak aby były rozpoznawane przez przeglądarkę oraz odpowiednio interpretowane. Dzięki temu, korzystając z przeglądarek, możemy obserwować dokumenty pełne odnośników, obrazków oraz animacji.
XML jest nieco inny — tutaj to programista ustala nazwy znaczników oraz całą strukturę dokumentów. Dzięki temu tworzy unikalny format dokumentów, który może być odczytywany za pomocą dowolnego edytora tekstu.
XML jest często mylony z bazą danych. Należy jednak podkreślić, że XML — chociaż działa podobnie — nie jest bazą danych. W przypadku baz danych każda platforma (MySQL, PostgreSQL, Oracle) posiada własną strukturę danych i własne formaty plików, w których są gromadzone informacje. Co prawda uniwersalny jest tutaj język zapytań — SQL, za pomocą którego komunikujemy się z bazą danych, ale sam zapis i odczyt informacji z plików zapewnia aplikacja — np. MySQL. Plik XML jest natomiast zwykłym plikiem tekstowym, dzięki czemu każdy może modyfikować jego zawartość.
Obecnie istnieje wiele tzw. parserów, które pozwalają na prostą modyfikację plików XML. Służą one do odczytywania struktury takiego pliku, dzięki czemu odciążają programistę od mozolnego procesu edycji kodu XML.
XML nie został stworzony przez żadną firmę, lecz przez niezależne konsorcjum (W3C również utworzyło standard HTML), co gwarantuje mu niezależność oraz brak praw patentowych. Popularność XML ciągle rośnie, a dowodem tego są nowe standardy, które go wykorzystują (np. SOAP).
Niezależność XML
XML jest niezależny od platformy, języka programowania i sprzętu (PC, Palmtop), jest więc doskonałym i łatwym formatem do przechowywania danych. Weźmy jako przykład notowania spółek giełdowych przedstawiane na różnych portalach. Notowania te są zapisane na stronie w formie tabel HTML, tak więc jedynym problemem w tym momencie jest odpowiednia edycja kodu HTML, tak aby pozyskać z niego potrzebne dane. Wystarczy jednak mała zmiana w tym kodzie, aby wykorzystane narzędzie przestało poprawnie funkcjonować. Jeżeli takie dane byłyby przedstawiane jedynie w formie XML, znika problem niekompatybilności. Wynika to z tego, że XML prezentuje jedynie treść, a nie formę — jak ma to miejsce w HTML.
XHTML
XHTML jest nowym standardem, opracowanym także przez W3C, który w zamierzeniach ma zastąpić HTML i stanowić pewien pośrednik pomiędzy językiem HTML a XML. Rozwój HTML został wstrzymany i teraz do projektowania stron WWW zaleca się używanie XHTML.
XHTML jest bardziej uporządkowany niż HTML. Usunięto stąd wiele znaczników HTML, stawiając na rozwój arkuszy stylów CSS. Innymi słowy, projektant powinien zrezygnować z wielu znaczników HTML na rzecz CSS.
Budowa dokumentu
W tym podrozdziale mam zamiar opisać, jak wygląda budowa plików XML i jakie są ich wymagane elementy. Jako edytora można tutaj użyć dowolnego programu pozwalającego na zapisywanie tekstu, ja będę korzystał z edytora Visual C# Express Edition.
Jeżeli masz otwarty nowy projekt, z menu Project wybierz Add New Item. W oknie wybierz pozycję XML File i naciśnij Add. Do projektu dodany zostanie nowy plik, którego zawartość wygląda tak:
<?xml version="1.0" encoding="UTF-8" ?>
Taki dokument można zapisać pod dowolną nazwą z rozszerzeniem *.xml. Pliki XML otwiera się w przeglądarce — np. Internet Explorer — aby sprawdzić poprawność dokumentu.
Jeśli dokument jest poprawny, Internet Explorer powinien wyświetlić jego treść, w przeciwnym razie wskaże błąd w dokumencie.
Należy w tym momencie zaznaczyć, że XML nie jest tak elastyczny jak HTML. Przeglądarki obecnie są w stanie zaakceptować nieprawidłowy zapis kodu HTML i mimo błędu poprawnie zinterpretować dany znacznik. Najmniejszy błąd w XML spowoduje, że przeglądarka wyświetli błędy w dokumencie.
Prolog
Specyficzna instrukcja dodana automatycznie przez środowisko Visual C# Express Edition do dokumentu to tzw. prolog. Jest to opcjonalna informacja dla parsera, informująca o typie dokumentu oraz kodowaniu. Powinno się przykładać dużą wagę do owego nagłówka i zawsze stosować go w swoich dokumentach.
Standardowa budowa prologu jest następująca:
<?xml version="1.0" encoding="UTF-8" ?>
Podstawowym warunkiem jest umieszczenie go między znacznikami <?xml oraz ?>. Opis poszczególnych parametrów prologu znajduje się w tabeli 13.1.
Tabela 13.1. Elementy składowe prologu
`<?xml ?>` | Podstawowe instrukcje używane przy deklaracji nagłówka XML. |
| `version="1.0"` | Wersja specyfikacji XML. Obecnie jedyną wersją owej specyfikacji jest 1.0. |
| `encoding="UTF-8"` | Ważny nagłówek, mówiący o kodowaniu dokumentu. Zalecam używanie kodowania Unicode (UTF-8), gdyż zapewnia on poprawne wyświetlanie większości znaków. Godnym polecenia jest również standard ISO-8859-2. |
| `standalone="yes"` | Dodatkowa wartość określająca, czy dokument zawiera jakieś odwołania do innych plików (yes). |
Znaczniki
Budowa dokumentów HTML, XHTML oraz XML opiera się na znacznikach, zwanych także tagami. W przypadku HTML oraz XHTML znaczniki muszą mieć z góry określoną nazwę. W przypadku XML nie ma takich restrykcji, tak więc nazwa danego znacznika zależy już od programisty. Listing 13.1 przedstawia przykładową zawartość pliku XML.
Listing 13.1. Przykładowa zawartość pliku XML
<?xml version="1.0" encoding="ISO-8859-2" standalone="no" ?>
<jedzenie>
<pizza>
<nazwa>Hawajska</nazwa>
<cena>14,50</cena>
</pizza>
<pizza>
<nazwa>Peperoni</nazwa>
<cena>15,50</cena>
</pizza>
</jedzenie>
Taką zawartość możesz wkleić do swojego edytora i zapisać. Po otwarciu takiego pliku w przeglądarce Internet Explorer powinien zostać wyświetlony obraz taki jak na rysunku 13.1.

Rysunek 13.1. Zawartość dokumentu XML wyświetlona przez Internet Explorer
Jeśli wpisany kod będzie niepoprawny, Internet Explorer wyświetli informację o tym, w której linii wystąpił błąd.
Budowa znacznikowa
Znaczniki są elementami o określonej nazwie, umieszczonymi pomiędzy nawiasami (< oraz >). Wyróżniamy dwa rodzaje znaczników — otwierający oraz zamykający. W takim przypadku w znaczniku zamykającym musi się znaleźć znak /:
<nazwa_znacznika> </nazwa_znacznika>
Pomiędzy znacznikami można umieścić określoną wartość, pewne dane.
Istnieje kilka ważnych reguł, jak np. nazewnictwo. Nazwy znacznika otwierającego oraz zamykającego muszą być identyczne. Rozróżniana jest także wielkość znaków. Tak więc poniższy zapis spowoduje zgłoszenie błędu:
<nazwa_znacznika> dane </Nazwa_Znacznika>
Podczas edycji znaczników XML należy także zwrócić uwagę na ich nazwy — nie mogą się zaczynać od cyfr oraz nie mogą zawierać znaków $#%&*(/. Przykładowo, poniższa nazwa znacznika nie jest poprawna:
<code><a12$%3> dane </a12$%3></code>
Znacznik otwierający i zamykający oraz informacja umieszczona między nimi to węzeł.
Elementy HTML
Format XML jest stworzony jedynie do przechowywania informacji, tak więc upiększające tekst znaczniki HTML nie mają dla XML znaczenia. Przykładowo, znacznik <b> służył w HTML do pogrubiania tekstu. W XML taki znacznik będzie zwykłym tagiem, niewpływającym na sposób wyświetlania tekstu:
<nazwa>Pizza <b>Peperoni</b> jest dobra</nazwa>
Znaczniki zagnieżdżone
W związku z powyższym przykładem chciałbym wspomnieć o znacznikach zagnieżdżonych. Element <code><nazwa></code> będzie głównym znacznikiem zawierającym tekst Pizza jest dobra.
Natomiast w powyższym przypadku znacznikiem zagnieżdżonym będzie <code><b></code>, zawierający tekst Peperoni.
Znaczniki zagnieżdżone są podstawowym element projektowania dokumentów XML — ten mechanizm wykorzystałem również na listingu 13.1. W tamtym przypadku głównym znacznikiem jest <jedzenie>. Znacznik ten zawiera z kolei dwa elementy <code><pizza></code>. W elementach <code><pizza></code> znalazły się znaczniki określające nazwę pizzy oraz cenę.
Znaki specjalne
Podczas wpisywania informacji pomiędzy znacznikami nie można używać znaków < oraz >. Aby umieścić te znaki pomiędzy tagami, należy zastosować pewien trik, polegający na zastąpieniu ich innymi wartościami (tabela 13.2).
Tabela 13.2. Znaki specjalne XML
| Znak specjalny | Należy zastąpić |
|---|---|
| `<` | `<` |
| `>` | `>` |
| `&` | `&` |
| `“` | `"` |
| `’` | `'` |
Po małych zabiegach taki kod XML będzie prawidłowy:
<nazwa>Pizza <Peperoni> jest dobra</nazwa>
I co najważniejsze — znaki < oraz > zostaną poprawnie wyświetlone.
Atrybuty
Każdy element może dodatkowo wykorzystywać atrybuty przybierające określone wartości:
<nazwa id="101">Peperoni</nazwa>
W tym przykładzie pizza Peperoni posiada atrybut id o wartości 101. Atrybuty należy wpisywać między apostrofami lub w cudzysłowie. W danym elemencie można umieścić dowolną liczbę parametrów.
Tak samo jak w przypadku nazw elementów, nazwy atrybutów nie mogą zawierać niedozwolonych znaków (!@#^&*), nawiasów itp.
Znaczniki puste
Istnieje możliwość deklarowania elementów w sposób specyficzny — uwzględniając jedynie atrybuty, bez zamykania danego znacznika. W takim przypadku na końcu nazwy elementu musi znaleźć się znak /.
<nazwa id="101" nazwa_pizzy="Peperoni" />
Powyższy element posiada atrybuty id oraz nazwa_pizzy i jest znacznikiem pustym.
Podstawowa terminologia
Czasami wyrazy tag, znacznik, element czy węzeł są używane zamiennie, gdyż człowiek jest w stanie domyślić się ich znaczenia. Pragnę jednak sprecyzować pewne pojęcia.
Znacznik inaczej możemy nazywać tagiem — jest to specjalnie sformatowany ciąg znaków, np.:
</p>
```
Elementy składają się z otwartych oraz zamkniętych znaczników:
</p>
</table>
```
Elementy mogą być także puste — taką możliwość przewiduje specyfikacja XML lub XHTML:
Elementy mogą z kolei mieć atrybuty, które mogą przybierać wartości:
```xml
<element atrybut="wartość">
Węzłem nazywamy element, który posiada wartość:
<element>wartość</element>
Węzły z kolei mogą posiadać zagnieżdżone elementy. Mam nadzieję, że ta podstawowa terminologia pozwoli Ci zrozumieć treść niniejszego rozdziału.
Węzeł główny
Węzeł główny
Analizując listing 13.1, można zauważyć, że cały pozostały kod XML znalazł się w węźle głównym — <jedzenie>. Jest to podstawowa zasada: wszystkie pozostałe węzły muszą zostać umieszczony w jednym głównym korzeniu (ang. root). Trzeba o tym pamiętać podczas tworzenia własnych dokumentów XML.
Komentarze
Komentarze
Jak w każdym języku takim jak HTML czy XHTML, także i w XML istnieją komentarze. Komentarze nie są uwzględniane przez parser i muszą być zawarte pomiędzy znakami <!-- oraz -->, tak samo jak to ma miejsce w dokumentach HTML:
<!--komentarz-->
Oczywiście taki komentarz nie musi ograniczać się tylko do jednej linii:
<!--
Lista TODO:
1) Benek: wyrównaj elementy.
2) Kaziu: a gdzie reszta?
-->
Przestrzenie nazw
Przestrzenie nazw
Konstrukcja przestrzeni nazw (ang. namespace) pozwala na deklarację więcej niż jednego zbioru znaczników.
Najlepiej przedstawić to na przykładzie. W pewnym projekcie istnieje dokument XML, do którego dostęp ma kilku projektantów. Dokument jest dość rozbudowany i wciąż powiększany. Jeden z programistów zadeklarował w dokumencie tag <Author>, oznaczający autora książki. Drugi z programistów, nie wiedząc o tym, również zadeklarował tag <Author>, tyle że według niego miał on określać autora w sensie wykonawcy — np. albumu muzycznego. Dochodzi w tym momencie do konfliktu.
Dokumenty XSD korzystają z przestrzeni nazw (o tym w dalszej części rozdziału), więc konieczne staje się wprowadzenie Cię w tę tematykę. Poniżej prezentuję przykład utworzenia znaczników wraz z przestrzeniami nazw:
<ns1:pizza xmlns:ns1="http://4programmers.net">
<nazwa>Hawajska</nazwa>
<cena>14,50</cena>
</ns1:pizza>
<ns2:pizza xmlns:ns2="http://programowanie.org">
<nazwa>Peperoni</nazwa>
<cena>15,50</cena>
</ns2:pizza>
W tym przykładzie oba znaczniki <pizza> różnią się od siebie identyfikatorem przestrzeni nazw — w pierwszym przypadku jest to http://4programmers.net, a w drugim http://programowanie.org.
Składnia przestrzeni nazw
Składnia przestrzeni nazw
Należy rozróżniać pewne pojęcia, takie jak identyfikator przestrzeni nazw oraz alias przestrzeni. Spójrzmy na poniższą linię:
<ns2:pizza xmlns:ns2="http://programowanie.org">
W tym przykładzie identyfikatorem jest fraza http://programowanie.org, a aliasem skrótowym — ns2. Identyfikator musi być adresem URL, niekoniecznie związanym z dokumentem XML — nie musi nawet istnieć. Może to być fikcyjny adres w sieci. Często w tym miejscu jest umieszczany odnośnik do schematu zawierającego definicję dokumentu XML (tym na razie nie należy się przejmować — opiszę to w dalszej części rozdziału).
Konstrukcja przestrzeni nazw jest prosta, deklaruje się ją za pomocą frazy xmlns:ns2, gdzie ns2 to alias przestrzeni nazw. Owego aliasu używamy podczas deklarowania znaczników w poniższy sposób:
<alias:nazwa_znacznika>
Przestrzenie nazw i atrybuty
Przestrzenie nazw i atrybuty
Możliwe jest także przydzielenie danej przestrzeni nazw do atrybutów:
<ns2:pizza xmlns:ns2="http://4programmers.net" ns2:lang="PL">
Co prawda nie jest to często używana konstrukcja, ale warto o niej wiedzieć. Wspominam o tym, ponieważ chciałbym w tym momencie zwrócić uwagę na możliwość deklarowania przestrzeni nazw http://www.w3.org/XML/1998/namespace o aliasie xml. Przestrzeń ta zawiera atrybut lang, który może być stosowany dla każdego elementu dokumentu bez konieczności jawnego określania przestrzeni xml. Dzięki temu można np. w dokumencie XML stosować węzły wielojęzyczne, co ułatwia proces tworzenia wielojęzycznego dokumentu:
<ns2:pizza xmlns:ns2="http://4programmers.net">
<ns2:nazwa>Peperoni</ns2:nazwa>
<ns2:cena xml:lang="PL">15,50</ns2:cena>
<ns2:cena xml:lang="EU">4</ns2:cena>
</ns2:pizza>
W powyższym przykładzie jeden element <ns2:cena> ma atrybut xml:lang o wartości PL, a drugi — EU. Dzięki temu możemy np. ustalić cenę pizzy w złotówkach oraz w euro.
DTD
DTD
Można mówić o dwóch rodzajach dokumentu — poprawnie sformatowanym oraz poprawnym. Dokument poprawnie sformatowany to taki, w którym wszystkie znaczniki są zamknięte, a elementy prawidłowo zagnieżdżone.
Dokument poprawny musi z kolei zawierać dodatkowo deklarację DTD, czyli Document Type Declaration. Polecenia DTD mogą się znaleźć bezpośrednio w dokumencie XML lub w osobnym pliku. Instrukcje DTD, najprościej mówiąc, służą do opisu tego, z czego składa się dokument XML. Instrukcje DTD są unikalne i proste — listing 13.2 przedstawia dokument XML wraz z opisem struktury.
Listing 13.2. Dokument XML wraz z deklaracją DTD
<?xml version="1.0" encoding="ISO-8859-2" standalone="no" ?>
<!DOCTYPE jedzenie [
<!ELEMENT nazwa (#PCDATA)>
<!ELEMENT pizza (nazwa)>
]>
<jedzenie>
<pizza>
<nazwa>Hawajska</nazwa>
<cena>14,50</cena>
</pizza>
<pizza>
<nazwa>Peperoni</nazwa>
<cena>15,50</cena>
</pizza>
</jedzenie>
Początek instrukcji DTD musi rozpoczynać się frazą <!DOCTYPE, a kończyć ]>. Pomiędzy tymi instrukcjami znajdują się opisy elementów i — ogólnie — struktury pliku XML.
Deklaracja elementu
Deklaracja elementu
Kluczową częścią DTD jest deklaracja typu elementu znajdującego się w kodzie XML. Owa deklaracja jest wykonywana przy użyciu jednej linii, która rozpoczyna się frazą <!ELEMENT:
<!ELEMENT nazwa (#PCDATA)>
Następnie należy podać nazwę elementu oraz zawartość — w tym przypadku #PCDATA. Tabela 13.3 przedstawia frazy, które mogą posłużyć w opisie DTD do określania danego elementu.
Tabela 13.3. Frazy DTD opisujące zawartość elementu
Fraza</th>Opis</th>Przykład</th></tr>
EMPTY</td>Pusty element</td>DTD:
`<!ELEMENT nazwa EMPTY>
XML:
<nazwa />
```
`
</td></tr>
(#PCDATA)</td>Pomiędzy znacznikami znajduje się zwartość (zwykły tekst)</td>DTD:
`<!ELEMENT nazwa (#PCDATA)>`
XML:
`<nazwa>zawartość</nazwa>`</kbd></td></tr>
(child)</td>Dany element posiada inny zagnieżdżony element o nazwie child</td>DTD:
`<!ELEMENT parent (child)>
<!ELEMENT child (#PCDATA)>
```
`
XML:
`<parent>
<child>zawartość</child>
</parent>
```
`</td></tr>
(Seq1,Seq2)</td>Dany element posiada zagnieżdżone elementy Seq1 oraz Seq2</td>DTD:
`<!ELEMENT SEQ (N1, N2)>
<!ELEMENT N1 (#PCDATA)>
<!ELEMENT N2 (#PCDATA)>
```
`
XML:
`<seq>
<n1>zawartość</n2>
<n2>zawartość</n2>
</seq>
```
`</td></tr>
(child*)
(child+)
(child?)</td> Znaki *, ? oraz + określają, ile razy element child może wystąpić:
* — zero lub więcej razy,
+ — jeden raz lub więcej,
? — zero lub jeden raz</td> DTD:
`<!ELEMENT parent (child*)>
<!ELEMENT child (#PCDATA)>
```
`
XML:
`<parent>
<child>zawartość</child>
<child>zawartość</child>
</parent>
```
`</td></tr>
(child1 |
child2)</td> Znak | (pipe) oznacza możliwość wyboru. Użyty może zostać element child1 lub child2</td> DTD:
`<!ELEMENT parent (child1 | child2)>
<!ELEMENT child1 (#PCDATA)>
<!ELEMENT child2 (EMPTY)>
```
`
XML:
`<parent>
<child1>zawartość</child1>
</parent>
<parent>
<child2 />
</parent>
```
`
</td></tr>
</table>
Deklaracja atrybutu
Deklaracja atrybutu
DTD jest również używane do deklarowania atrybutów, jakie są wykorzystywane przy elementach. Ich budowa jest następująca:
<!ATTLIST Element Atrybut Typ Domyślna_wartość>
W przypadku gdy atrybutów jest wiele, można określić ich domyślne wartości w następujący sposób:
<!ATTLIST Element Atrybut Typ Domyślna_wartość>
Typ Domyślna_wartość>
Gdzie:
*Element — nazwa elementu (znacznika),
*Atrybut — nazwa atrybutu w znaczniku,
*Typ — typ atrybutu: tekstowy, znakowy, wyliczeniowy.
Typ tekstowy
Typ tekstowy
Typ tekstowy jest deklarowany z użyciem słowa kluczowego CDATA:
<!ATTLIST nazwa id CDATA 'łańcuch'>
W takim przypadku wiadomo, że atrybut id znajduje się w elemencie nazwa i jest typu tekstowego. Domyślną wartością atrybutu (jeżeli nie został zadeklarowany w kodzie XML) będzie ciąg znakowy.
Jeżeli atrybut ma zawierać liczby, można określić typ DTD także jako CDATA i po prostu otoczyć liczbę znakami apostrofu.
Typ wyliczeniowy
Typ wyliczeniowy
Opisanie atrybutu DTD w sposób wyliczeniowy daje wybór, pewien zakres wartości, jakie może on przyjmować. Przyjrzyjmy się poniższemu fragmentowi kodu:
<?xml version="1.0" encoding="ISO-8859-2" standalone="no" ?>
<!DOCTYPE jedzenie [
<!ELEMENT nazwa (#PCDATA)>
<!ELEMENT pizza (nazwa)>
<!ATTLIST nazwa id (101|102|103) '103'>
]>
<jedzenie>
<pizza>
<nazwa>Hawajska</nazwa>
<cena>14,50</cena>
</pizza>
<pizza>
<nazwa id="101">Peperoni</nazwa>
<cena>15,50</cena>
</pizza>
</jedzenie>
Właściwości atrybutu id w elemencie nazwa określa poniższa linia:
<!ATTLIST nazwa id (101|102|103) '103'>
W takim przypadku atrybut id będzie mógł przyjmować wartość 101, 102 lub 103, lecz wartością domyślną będzie 103. Należy także zwrócić uwagę, że pierwszy element <code><nazwa></code> nie ma zadeklarowanego atrybutu id. W związku z tym, gdy wyświetlimy kod pliku XML w przeglądarce Internet Explorer, nada ona automatycznie atrybut id brakującym elementom.
DTD w osobnym pliku
DTD w osobnym pliku
Często stosowaną techniką jest wyodrębnianie części DTD z kodu XML i zapisywanie jej w osobnym pliku. Ułatwia to późniejszą modyfikację kodu oraz daje możliwość włączenia deklaracji DTD w kilku plikach.
Plik z deklaracją DTD powinien mieć rozszerzenie .dtd. Teraz można więc skopiować tekst znajdujący się pomiędzy <code><!DOCTYPE</code> a <code>]></code> do osobnego pliku — u mnie wygląda on tak:
<!ELEMENT nazwa (#PCDATA)>
<!ELEMENT pizza (nazwa)>
<!ATTLIST nazwa id (101|102|103) '103'>
<!ENTITY Special "Hawajska">
<!ENTITY Price "14,50">
Teraz w głównym pliku XML należy włączyć deklarację DTD w następujący sposób:
<!DOCTYPE jedzenie SYSTEM "jedzenie.dtd">
Encje tekstowe
Encje tekstowe
Encje tekstowe muszą zostać zadeklarowane w sekcji DTD. Pełnią one w dokumencie XML funkcję szablonu. Dzięki encjom programista unika ciągłego wpisywania tej samej frazy w tych samych miejscach kodu XML. Działanie encji można porównać do stałych — jedna stała może być później użyta w dalszej części programu, tak więc ułatwia to ewentualną zmianę danych — wystarczy wówczas tylko zmiana jednej stałej. Listing 13.3 prezentuje sposób wykorzystania encji tekstowych.
Listing 13.3. Prezentacja wykorzystania encji tekstowych
<?xml version="1.0" encoding="ISO-8859-2" standalone="no" ?>
<!DOCTYPE jedzenie [
<!ELEMENT nazwa (#PCDATA)>
<!ELEMENT pizza (nazwa)>
<!ATTLIST nazwa id (101|102|103) '103'>
<!ENTITY Special "Hawajska">
<!ENTITY Price "14,50">
]>
<jedzenie>
<pizza>
<nazwa>&Special;</nazwa>
<cena>&Price;</cena>
</pizza>
<pizza>
<nazwa id="101">Peperoni</nazwa>
<cena>15,50</cena>
</pizza>
</jedzenie>
Dzięki encjom zostały utworzone nowe znaczniki — &Special; oraz &Price;. Encję deklaruje się w następujący sposób:
<!ENTITY Special "Hawajska">
Budowa tego elementu jest prosta: encję rozpoczyna fraza <!ENTITY, po której występuje nazwa oraz wartość między znakami apostrofów. W tym momencie wstawienie znacznika &Special; w kodzie XML spowoduje zamienienie go na wartość owej encji.
Należy zwrócić uwagę na znak średnika na końcu (&Special;). Jak już wspominałem, w XML liczy się precyzja i takich szczegółów nie można pominąć.
W kodzie XML można używać zarówno cudzysłowu ("), jak i apostrofów (').
XSD
XSD
Do weryfikacji poprawności dokumentu XML stosowane jest DTD lub XSD (ang. XML Schema Definition) — standard opisu dokumentu zalecany przez W3C. Konsorcjum W3C preferuje wykorzystanie XSD zamiast DTD, ponieważ schemat ten korzysta z języka XML.
XSD definiuje elementy, atrybuty oraz typy danych zawartych w dokumencie XML. XSD jest bardziej użyteczny oraz rozbudowany niż DTD, a przede wszystkim opracowany i zalecany przez W3C.
Idea utworzenia XSD została zapoczątkowana przez firmę Microsoft, ale w końcu w roku 2001 patronat nad powstaniem i utworzeniem standardu objęła organizacja W3C. Przypominam, że XML opracowano w roku 1998.
Utwórzmy nowy plik tekstowy i nazwijmy go jedzenie.xsd. Ten plik tekstowy należy umieścić w tym samym katalogu co przykładowy dokument XML. Będzie on zawierał instrukcje XSD. Przyjmujemy więc, że deklaracje XSD zostaną umieszczone w osobnym pliku. Na listingu 13.4 znajduje się przykładowy kod z instrukcjami XSD. Przypominam, że deklaracje (instrukcje) XSD są napisane w języku XML i to jest podstawowa różnica pomiędzy nim a DTD.
Listing 13.4. Przykładowe instrukcje XSD
<?xml version="1.0"?>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.programowanie.org"
elementFormDefault="qualified">
<xs:element name="jedzenie">
<xs:element name="pizza">
<xs:element name="nazwa" type="xs:string" />
<xs:element name="cena" type="xs:string" />
</xs:element>
</xs:element>
</xs:schema>
Nagłówek XSD
Nagłówek XSD
Na samym początku należy zaznaczyć, że XSD korzysta z przestrzeni nazw XML, którą trzeba określić na samym początku. Wszystkie schematy XSD muszą mieć główny węzeł <code><schema></code>, taki jak ten poniżej:
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.programowanie.org"
elementFormDefault="qualified">
Może nie być zupełnie identyczny, ale ważny jest tutaj element o nazwie <code><schema></code>, który jest obowiązkowy w dokumencie XSD. Jak widać, używamy tutaj przestrzeni nazw, deklarując http://www.w3.org/2001/XMLSchema o aliasie xs.
Elementy XSD
Elementy XSD
XSD w rzeczywistości jest charakterystycznym kodem XML, np.:
<xs:element name="nazwa" type="xs:string" />
Taka konstrukcja służy do opisania następującego kodu XML:
<nazwa>Peperoni</nazwa>
Budowa XSD jest dość prosta, charakteryzuje się użyciem słowa kluczowego element:
<xs:element name="nazwa_elementu" type="xs:typ_elementu" />
Wartością atrybutu name musi być nazwa elementu w kodzie XML, a atrybut type określa rodzaj (typ) danych umieszczonych pomiędzy tagami. Opisany element należy do elementów prostych, czyli takich, które zwierają jakieś dane (tekst, liczby, wartości typu boolean), nie mogą jednak zawierać innych znaczników oraz atrybutów.
Oto przykład schematu XSD opisującego kod XML, który zawiera zagnieżdżone znaczniki:
<xs:element name="pizza">
<xs:element name="nazwa" type="xs:string" />
<xs:element name="cena" type="xs:float" />
</xs:element>
Powyższy przykład opisuje następujący kod XML:
<pizza>
<nazwa>Hawajska</nazwa>
<cena>14,50</cena>
</pizza>
<pizza>
<nazwa>Peperoni</nazwa>
<cena>15,50</cena>
</pizza>
Typy danych
Typy danych
Już się dowiedziałeś, że schematy XSD wymagają podania typu danych elementów XML, które opisują. W poprzednich przykładach użyłem typu string oraz float. Tabela 13.4 prezentuje kompletną listę typów danych.
Tabela 13.4. Typy danych
Typ</th>Opis</th></tr>
`string`</td>Ciąg tekstowy, czyli ciąg znaków</td></tr>
`float`</td>32-bitowe liczby rzeczywiste</td></tr>
`double`</td>64-bitowe liczby rzeczywiste (większa precyzja)</td></tr>
`datime`</td>Data i czas w formacie YYYY-MM-DD hh:mm:ss</td></tr>
`integer`</td>Liczby rzeczywiste</td></tr>
`boolean`</td>Wartości true lub false</td></tr>
</table>
Typy proste
Typy proste
Czym jest typ prosty? Jest to element, który zawiera jedynie tekst — dane proste. Może nie jest to do końca poprawne sformułowanie, bo element prosty może także zawierać wartości numeryczne typu boolean itp.
Deklarowaliśmy już schematy opisujące proste elementy XML:
<xs:element name="nazwa" type="xs:string" />
Schemat dokumentu XML może uwzględniać pewne restrykcje dotyczące danych mieszczących się w konkretnym elemencie XML. Nim jednak wspomnę o ograniczeniach, zaprezentuję nadawanie wartości domyślnych dla elementów.
Oto przykład:
<xs:element name="nazwa" type="xs:string" default="Hawajska" />
Taki fragment schematu opisuje następujące dane XML:
*Opisuje element XML o nazwie nazwa.
*Określa, że typem elementu nazwa jest ciąg znaków (string).
*Deklaruje, że domyślna wartość elementu nazwa to Hawajska.
W miejsce atrybutu default można użyć fixed. Podana w tym atrybucie wartość nie będzie jedynie domyślna — nie będzie jej można później zmienić!
Atrybuty
Atrybuty
Na początku możesz być nieco sceptyczny, bowiem atrybuty elementu XML w schemacie XSD są opisywane jako element. Ważne jest zrozumienie tego zdania. Przypuśćmy, że mamy fragment kodu XML o takiej postaci:
<pizza name="Hawajska" />
Jest to prosty, zwykły znacznik zawierający atrybut name. Teraz schemat opisujący zarówno ten element, jak i atrybut wygląda następująco:
<xs:element="pizza" type="xs:string" />
<xs:attribute="name" type="xs:string" />
</xs:element>
Schematy opisujące atrybuty, tak samo jak te opisujące elementy, mogą zawierać wartości domyślne (czyli parametry default oraz fixed).
Wszystkie atrybuty elementu XML domyślnie są opcjonalne. Nie jest konieczne ich deklarowanie w trakcie tworzenia dokumentu XML. Można to zmienić, deklarując schemat opisujący element:
<xs:element="pizza" type="xs:string" />
<xs:attribute="name" type="xs:string" use="optional" />
</xs:element>
Powyższa deklaracja określa, iż atrybut name elementu pizza będzie opcjonalny — tak samo jak w poprzednim przykładzie. Taki zapis nie jest konieczny, gdyż — jak już powiedziałem — atrybuty XML domyślnie są opcjonalne.
Można natomiast określić, iż dany atrybut ma być wymagany! W miejsce słowa optional należy wpisać required:
<xs:element="pizza" type="xs:string" />
<xs:attribute="name" type="xs:string" use="required" />
</xs:element>
Restrykcje
Restrykcje
Restrykcje są elementem XSD, który pozwala na przypisanie szczegółowych informacji odnośnie danego elementu XML — np. maksymalnej wartości, jaka może być zawarta w danym elemencie. Oto przykład nadania restrykcji dla elementu XML — price:
<xs:element="price">
<xs:simpleType>
<xs:restriction base="xs:integer">
<xs:minInclusive value="10" />
<xs:maxInclusive value="50" />
<xs:restriction>
</xs:simpleType>
</xs:element>
Restrykcje tego typu prostego mówią, iż wartość elementu price musi być większa od 10, ale jednocześnie mniejsza od 50. Opis pozostałych restrykcji znajduje się w tabeli 13.5.
Tabela 13.5. Restrykcje możliwe do użycia w schematach XSD
Restrykcja</th>Opis</th></tr>
`length`</td>Opisuje długość danego elementu.</td></tr>
`minLength`</td>Minimalna długość, jaką może przybrać dany element.</td></tr>
`maxLength`</td>Maksymalna długość, jaką może przybrać dany element.</td></tr>
`pattern`</td>Maska, zaawansowane opcje związane z wyrażeniami regularnymi.</td></tr>
`enumeration`</td>Wartość musi być jedną z podanych.</td></tr>
`minInclusive`</td>Wartość elementu musi być większa lub równa liczbie podanej w schemacie.</td></tr>
`minExclusive`</td>Wartość elementu musi być większa od liczby podanej w schemacie.</td></tr>
`maxInclusive`</td>Wartość elementu musi być mniejsza lub równa liczbie podanej w schemacie.</td></tr>
`maxExclusive`</td>Wartość elementu musi być mniejsza od liczby podanej w schemacie.</td></tr>
</table>
Restrykcje typu Enumeration
Restrykcje typu Enumeration
Elementy XML mogą mieć wartość jedną spośród wcześniej określonych. W takim przypadku w elemencie XSD restriction należy zagnieździć kolejny element — enumeration:
<xs:element="pizza">
<xs:simpleType>
<xs:restriction base="xs:string">
<xs:enumeration value="Peperoni" />
<xs:enumeration value="Hawajska" />
<xs:restriction>
</xs:simpleType>
</xs:element>
Powyższy schemat mówi, iż wartością elementu pizza może być albo Peperoni, albo Hawajska.
Typy złożone
Typy złożone
Typy złożone mają inne zagnieżdżone znaczniki. Być może już domyślasz się, jak wygląda schemat typów złożonych. Oto przykładowy znacznik XML:
<pizza>
<nazwa>Hawajska</nazwa>
<cena>14,50</cena>
</pizza>
Schemat XSD opisujący takie znaczniki wygląda następująco:
<xs:element name="pizza">
<xs:complexType>
<xs:element name="nazwa" type="xs:string" />
<xs:element name="cena" type="xs:float" />
</xs:complexType>
</xs:element>
XML a bazy danych
XML a bazy danych
Częstym nieporozumieniem dotyczącym XML jest stwierdzenie, jakoby miał on zastępować bazy danych. Dane przechowywane w XML są zasadniczo inne niż w bazach danych. Przede wszystkim XML jest zwykłym plikiem tekstowym, łatwym do odczytania dla ludzi oraz przez maszyny. Bazy danych gromadzą informacje w plikach binarnych, co uniemożliwia ich odczytanie bez znajomości budowy takiego pliku.
Dane w bazach danych są dodatkowo przechowywane w tabelach, co zwiększa zdolność do prezentowania wielu dynamicznych perspektyw tych samych zbiorów.
Podsumujmy więc różnice pomiędzy XML a bazami danych:
*XML dobrze spisuje się przy prezentowaniu zarówno prostych, jak i złożonych struktur danych. Bazy danych służą do przechowywania „liniowych” struktur danych, które są reprezentowane w formie tabeli.
*Dokumenty XML można bardzo łatwo przenosić do innych systemów i na inne platformy — jest to bardzo elastyczny i uniwersalny język. Bazy danych natomiast trudno przenieść do innych systemów.
*Format XML bardzo łatwo można poddawać edycji za pomocą prostego edytora tekstów lub korzystając ze specjalnych programów. W przypadku baz danych edycja jest możliwa tylko za pomocą specjalnego programu.
*Systemy baz danych są bardziej efektywne i skomplikowane. Korzystając z języka SQL, można osiągnąć lepsze efekty, natomiast działanie parserów XML jest bardziej czasochłonne i bardziej obciąża zasoby systemowe.
Oczywiście nic nie stoi na przeszkodzie, aby połączyć zalety baz danych oraz XML, przechowując kod XML w bazie danych w polu typu BLOB lub TEXT.
XSL
XSL
Kolejnym terminem, o którym warto wspomnieć, jest XSL (ang. eXtensible Stylesheet Language). Jest to język, który opisuje przekształcenia dokumentów XSL. Jest to właściwie rodzina języków, bo składają się na nią:
*XSLT — XSL Transformation, czyli język dla przekształceń dokumentów XML,
*XPath — XML Path Language, czyli język opisujący dostęp lub odwołanie do fragmentów XML,
*XSL-FO — słownik opisujący formatowanie.
Jak widać, rodzina technologii XML jest bardzo duża, a jej całkowite opanowanie nie jest takie proste. XSLT służy do przekształcania dokumentu XML na dokument wizualny, który może zostać wydrukowany. W XSLT można stosować HTML i CSS, a następnie dynamicznie tworzyć stronę WWW, która będzie pobierać informacje z pliku XML. Takie informacje będą np. formowane w postaci tabeli HTML.
DOM
DOM
DOM, czyli Document Object Model, jest standardem opracowanym przez W3C, definiującym dostęp do dokumentów XML oraz HTML. Ów standard został przeniesiony na rzeczywisty zbiór interfejsów (API) i funkcji w wielu parserach czy np. przeglądarkach internetowych. DOM definiuje strukturę dokumentu oraz sposób manipulowania nim. Od czasu opublikowania specyfikacji DOM powstało wiele jej implementacji. W środowisku Win32 mogliśmy korzystać z kontrolki COM, udostępniającej interfejsy obsługujące XML.
W .NET będziemy korzystali z przestrzeni nazw System.XML i znajdujących się w niej klas.
W DOM dokumenty posiadają logiczną strukturę podobną do drzewa, które zawiera węzły. Np. poniższy fragment kodu XML w DOM będzie miał strukturę podobną do tej z rysunku 13.2:
<jedzenie>
<pizza>
<nazwa>Hawajska</nazwa>
<cena>14,50</cena>
</pizza>
<pizza>
<nazwa>Peperoni</nazwa>
<cena>15,50</cena>
</pizza>
</jedzenie>
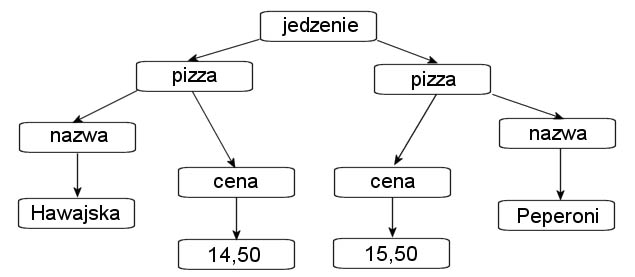
Rysunek 13.2. Struktura dokumentu XML
Podsumowując: interfejs API o nazwie DOM wczytuje do pamięci zawartość pliku XML w postaci drzewa, a następnie umożliwia przemieszczanie się po kolejnych węzłach oraz modyfikację drzewa.
SAX
SAX
SAX (ang. Simple API for XML) jest — podobnie jak DOM — interfejsem programistycznym definiującym dostęp do plików XML. O interfejsie SAX mówi się, że jest sterowany zdarzeniami. Oznacza to, że SAX parsując zawartość dokumentu, napotyka na znaczniki i inicjalizuje rozmaite czynności, których implementacja należy do programisty. Programista musi więc zainicjalizować procedury obsługi (ang. handlers) konkretnych znaczników.
Podstawową różnicą pomiędzy DOM a SAX jest sposób odczytywania dokumentów. SAX czyta dokumenty stosunkowo małymi porcjami, parsuje je i — w razie konieczności — wywołuje procedury obsługi. SAX nadaje się więc do analizy bardzo dużych dokumentów XML.
DOM jednorazowo wczytuje cały dokument do pamięci, w której tworzy drzewo gałęzi. Oznacza to duże obciążenie dla pamięci w przypadku większych dokumentów. DOM nadaje się więc do obsługi małych oraz średnich plików, a SAX jest wręcz stworzony do odczytu dużych dokumentów. SAX ma jednak dużą wadę — nie umożliwia zapisywania dokumentów XML, lecz służy jedynie do ich odczytu.
Korzystanie z System.XML
Korzystanie z System.XML
W prezentowanych tutaj przykładach będę posługiwał się podzespołem System.XML.dll, w którym znajduje się przestrzeń nazw System.XML — dodajmy ją więc do naszego programu.
Główną klasą, którą będziemy stosować do ładowania i zapisywania dokumentu, jest System.XML.XMLDocument, jednak przestrzeń System.XML definiuje o wiele więcej klas określających np. węzeł (ang. node) XML.
Ładowanie pliku XML
Ładowanie pliku XML
Aby załadować do pamięci plik XML, należy najpierw utworzyć nowy obiekt klasy System.XML.XmlDocument, a później skorzystać z metody Load, podając nazwę oraz ścieżkę do pliku XML:
using System;
using System.Xml;
namespace XmlApp
{
class Program
{
static void Main(string[] args)
{
XmlDocument XmlDoc = new XmlDocument();
try
{
XmlDoc.Load("C:\\demo.xml");
Console.WriteLine("Dokument załadowany!");
}
catch (XmlException e)
{
Console.WriteLine(e.Message);
}
Console.Read();
}
}
}
Jak widać, konstrukcja jest prosta. Metoda Load() ładuje plik XML do pamięci. Warto także wiedzieć o metodzie Save(), która zapisuje do podanego pliku zawartość edytowanego dokumentu XML.
Warto też zwrócić uwagę na obsługę wyjątku XMLException. Klasa XMLDocument ma wbudowany mechanizm walidacji, który sprawdza poprawność dokumentu XML. Dzięki temu w razie jakichś nieprawidłowości w kodzie XML zostanie wyświetlony komunikat błędu.
Do odczytania zawartości pliku XML można także użyć metody LoadXML.
Odczyt dowolnego elementu
Odczyt dowolnego elementu
Odczytanie wartości danego elementu jest związane z wywołaniem metody GetElementsByTagName(). To w niej podajemy nazwę znacznika, którego wartość zostanie odczytana. Na listingu 13.5 znajduje się fragment kodu odpowiadającego za załadowanie pliku XML do komponentu TreeView.
Listing 13.5. Metoda odczytująca zawartość pliku XML
private void btnLoad_Click(object sender, EventArgs e)
{
TreeNode NewXmlNode;
XmlDocument XmlDoc = new XmlDocument();
tvXML.Nodes.Clear();
try
{
XmlDoc.Load("C:\\demo.xml");
int Count = XmlDoc.GetElementsByTagName("pizza").Count;
for (int i = 0; i < Count; i++)
{
NewXmlNode = tvXML.Nodes.Add(XmlDoc.GetElementsByTagName("nazwa").Item(i).InnerText);
NewXmlNode.Nodes.Add("Składniki: " +
XmlDoc.GetElementsByTagName("skladnik").Item(i).InnerText);
NewXmlNode.Nodes.Add("Cena: " +
XmlDoc.GetElementsByTagName("cena").Item(i).InnerText);
}
}
catch (XmlException ex)
{
MessageBox.Show(ex.Message);
}
}
Na samym początku działania programu należało określić, ile elementów pizza zawiera nasz plik XML. Skorzystałem przy tym z właściwości Count klasy XMLNodeList:
XmlDoc.GetElementsByTagName("pizza").Count
Metoda GetElementsByTagName() zwraca dane właśnie w postaci klasy XMLNodeList.
Po określeniu liczby wystąpień elementu pizza możemy zaprogramować pętlę, która odczyta po kolei interesujące nas dane. Pobranie konkretnej wartości danego elementu wygląda następująco:
XmlDoc.GetElementsByTagName("skladnik").Item(i).InnerText
Wywołując metodę GetElementsByTagName(), podajemy nazwę znacznika, którego wartość zostanie odczytana. Jak wiadomo, w pojedynczym pliku XML może istnieć wiele znaczników o tej samej nazwie, należy więc określić jego numer (właściwość Item). Później pozostaje już tylko odczytanie wartości (InnerText). Rezultat działania programu został przedstawiony na rysunku 13.3, a sam kod XML prezentuje się następująco:
<?xml version="1.0" encoding="ISO-8859-2" standalone="no"?>
<jedzenie xmlns="http://www.programowanie.org"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.programowanie.org jedzenie.xsd">
<pizza>
<nazwa>Hawajska</nazwa>
<cena>14,50</cena>
<skladnik>ser, szynka, ananasy</skladnik>
</pizza>
<pizza>
<nazwa>Peperoni</nazwa>
<cena>20,00</cena>
<skladnik>peperoni, cebula</skladnik>
</pizza>
</jedzenie>
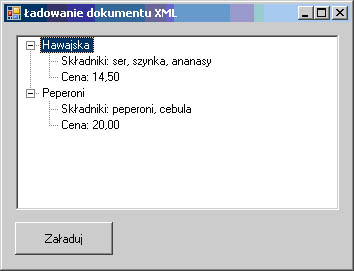
Rysunek 13.3. Rezultat działania programu
Odczyt wartości atrybutów
Odczyt wartości atrybutów
W poprzednim przykładzie przedstawiłem sposób odczytania wartości danego elementu (węzła). Nie należy zapominać o atrybutach danego węzła, które także odgrywają znaczącą rolę podczas tworzenia plików XML. Na przykład w ostatnio prezentowanym pliku XML każdej pizzy przypisano cenę, mieszczącą się w znaczniku <code><cena></code>. Nie należy zapominać, że w większości pizzerii ceny pizz zależą od ich wielkości. W takich sytuacjach idealne wydaje się zastosowanie atrybutów:
<?xml version="1.0" encoding="ISO-8859-2" standalone="no"?>
<jedzenie xmlns="http://www.programowanie.org"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.programowanie.org jedzenie.xsd">
<pizza>
<nazwa>Hawajska</nazwa>
<cena rozmiar="mała">14,50</cena>
<cena rozmiar="średnia">20,00</cena>
<cena rozmiar="duża">27,00</cena>
<skladnik>ser, szynka, ananasy</skladnik>
</pizza>
<pizza>
<nazwa>Peperoni</nazwa>
<cena rozmiar="mała">15,50</cena>
<cena rozmiar="średnia">19,50</cena>
<cena rozmiar="duża">26,50</cena>
<skladnik>peperoni, cebula</skladnik>
</pizza>
<pizza>
<nazwa>Barbacue</nazwa>
<cena rozmiar="mała">19,10</cena>
<cena rozmiar="średnia">26,00</cena>
<cena rozmiar="duża">31,50</cena>
<skladnik>bekon, kawałki kurczaka, cebula, czerwona papryka, ser</skladnik>
</pizza>
</jedzenie>
W powyższym dokumencie XML zadeklarowałem kilka znaczników <code><cena></code>, z których każdy ma inny atrybut rozmiar (mała, średnia, duża) i — w zależności od niego — cena pizzy jest różna. Listing 13.6 przedstawia fragment kodu aplikacji przystosowanej do wyświetlania informacji o trzech rodzajach pizz.
Listing 13.6. Odczyt atrybutów węzłów
private void btnLoad_Click(object sender, EventArgs e)
{
TreeNode NewXmlNode, PriceNode;
XmlNode Node;
XmlDocument XmlDoc = new XmlDocument();
tvXML.Nodes.Clear();
try
{
XmlDoc.Load("C:\\demo.xml");
int Count = XmlDoc.GetElementsByTagName("pizza").Count;
for (int i = 0; i < Count; i++)
{
NewXmlNode = tvXML.Nodes.Add(XmlDoc.GetElementsByTagName("nazwa").Item(i).InnerText);
NewXmlNode.Nodes.Add("Składniki: " +
XmlDoc.GetElementsByTagName("skladnik").Item(i).InnerText);
PriceNode = NewXmlNode.Nodes.Add("Ceny");
for (int j = i * 3; j <= (i * 3) + 2; j++)
{
Node = XmlDoc.GetElementsByTagName("cena").Item(j);
PriceNode.Nodes.Add(
Node.Attributes.GetNamedItem("rozmiar").InnerText + ": " + Node.InnerText
);
}
}
}
catch (XmlException ex)
{
MessageBox.Show(ex.Message);
}
}
Początek tej metody jest identyczny jak tej z listingu 13.5. Problemy zaczynają się później. Zdefiniowano 3 różne ceny dla każdej pizzy, kolejna pętla for musi przetworzyć trzy kolejne węzły, odczytując ich atrybuty. Skoro liczba węzłów <code><cena></code> w węźle <code><pizza></code> jest znana, wyliczenie liczby iteracji opiera się na rachunku matematycznym:
for (int j = i * 3; j <= (i * 3) + 2; j++)
W celu skrócenia zapisu do zmiennej Node jest przypisywany rezultat działania funkcji GetElementsByTagName("cena").Item(j). Następnie w celu pobrania wartości atrybutu należy skorzystać z metody GetNamedItem():
PriceNode.Nodes.Add(Node.Attributes.GetNamedItem("rozmiar").InnerText + ": " + Node.InnerText);
Prosty odczyt pliku XML
Prosty odczyt pliku XML
Nim zajmiemy się zapisywaniem dokumentów XML, przyjrzyjmy się klasie XmlTextReader, która zapewnia szybki i prosty mechanizm dostępu do dokumentów XML. Podczas tworzenia klasy należy podać w konstruktorze ścieżkę do dokumentu XML:
XmlTextReader Reader = new XmlTextReader("C:\\demo.xml");
Klasa Reader posiada metodę Read() (która zwraca wartość typu Boolean), dzięki której pętla może po kolei odczytać wszystkie elementy:
using System;
using System.Xml;
namespace XmlApp
{
class Program
{
static void Main(string[] args)
{
XmlTextReader Reader = new XmlTextReader("C:\\demo.xml");
while (Reader.Read())
{
Console.WriteLine(Reader.Name + ' ' + Reader.Value);
}
Reader.Close();
Console.Read();
}
}
}
Właściwość Name zwraca nazwę elementu, a Value — jego wartość. Takie rozwiązanie ma pewne wady, ponieważ klasa XmlTextReader nie rozpoznaje typów znaczników, czego rezultatem może być odczytanie przez nią wszystkich znaczników — również tych zamykających. Aby temu zapobiec, omawiana klasa wykorzystuje właściwość NodeType, dzięki której można odczytać jedynie interesujące nas elementy. Właściwość NodeType może przybrać następujące wartości:
*All — wszystkie węzły,
*Attribute — atrybut,
*Comment — komentarz XML,
*Document — element główny drzewa danych XML,
*Element — poszczególny element XML,
*EndTag — znacznik zamykający elementu,
*None — żaden węzeł nie jest analizowany,
*XMLDeclaration — węzeł zawierający deklarację XML.
Tworzenie pliku
Tworzenie pliku
Do tej pory zajmowaliśmy się jedynie odczytem węzłów i atrybutów. Nie wspomniałem w ogóle o tworzeniu plików XML, a taka możliwość w modelu DOM istnieje. Do tworzenia plików XML, w tym węzłów oraz atrybutów, służy klasa XMLTextWriter.
Podczas tworzenia klasy XMLTextWriter w parametrze konstruktora należy podać ścieżkę do pliku, który ma być utworzony w wyniku działania programu. Utworzenie i zwolnienie klasy w najprostszym przypadku wygląda następująco:
XmlTextWriter Writer = new XmlTextWriter("C:\\output.xml", null);
Drugi parametr konstruktora określa kodowanie pliku — zalecam pozostawienie w tym miejscu wartości pustej (null), co oznacza kodowanie domyślne, czyli Unicode (UTF-8). Jednak sam konstruktor nie wystarczy do stworzenia przykładowego, prostego dokumentu. Będziemy musieli dodatkowo użyć prostych metod WriteStartDocument(), WriteEndDocument():
using System;
using System.Xml;
namespace XmlApp
{
class Program
{
static void Main(string[] args)
{
XmlTextWriter Writer = new XmlTextWriter("C:\\output.xml", null);
Writer.WriteStartDocument();
Writer.WriteStartElement("root");
Writer.WriteEndElement();
Writer.WriteEndDocument();
Writer.Close();
}
}
}
Powyższy program utworzy prosty dokument XML, mający jeden węzeł główny — root:
<?xml version="1.0"?><root />
Przy tworzeniu dokumentów XML należy przestrzegać pewnych zasad:
#Tworzenie dokumentu rozpoczynamy od metody WriteStartDocument().
#Dokument kończymy wywołaniem metody WriteEndDocument().
#Zamknięcie dokumentu następuje w momencie wywołania metody Close().
#Dokument musi mieć przynajmniej jeden główny węzeł — tworzymy go metodą WriteStartElement(), podając w nawiasie jego nazwę.
#Węzeł zamykamy metodą WriteEndElement().
#Każdy węzeł utworzony metodą WriteStartElement() musi zostać zakończony metodą WriteEndElement().
Właściwości klasy XMLTextWriter
Właściwości klasy XMLTextWriter
Klasa XMLTextWriter ma parę ciekawych właściwości mających wpływ na wygląd dokumentu. Najważniejsze z nich zgromadziłem w tabeli 13.6.
Tabela 13.6. Najważniejsze właściwości klasy XMLTextWriter
Właściwość</th>Opis</th></tr>
`Formatting`</td>Formatowanie kodu (Formatting.Indented — ze wcięciami — lub Formatting.None — bez wcięć).</td></tr>
`Indentation`</td>Liczba znaków, które będą stanowiły wcięcia.</td></tr>
`IdentChar`</td>Znak, który będzie stanowił wcięcie.</td></tr>
`Namespaces`</td>Wartość True spowoduje obsługę przestrzeni nazw.</td></tr>
`QuoteChar`</td>Znak cytowania (apostrof lub cudzysłów).</td></tr>
`WriteState`</td>Określa, jakie dane będą wpisywane (apostrof, element).</td></tr>
`XmlLang`</td>Określa atrybut xml:lang.</td></tr>
</table>
Łatwo zauważyć, że większość z tych właściwości jest związana z formatowaniem kodu przez klasę XMLTextWriter. Można więc określić wartości, które pozwolą na tworzenie czytelniejszego kodu:
Writer.Formatting = Formatting.Indented;
Writer.Indentation = 4;
Metody klasy XMLTextWriter
Metody klasy XMLTextWriter
Metody klasy XMLTextWriter są związane z dodawaniem różnych informacji do pliku XML — np. encji, atrybutów oraz elementów. Najpierw spójrzmy na tabelę 13.7, prezentującą najważniejsze z metod, a później bliżej omówię kilka z nich.
Tabela 13.7. Najważniejsze metody klasy XMLTextWriter
Metoda</th>Opis</th></tr>
`LookupPrefix()`</td>Zwraca prefiks najbliższej przestrzeni nazw.</td></tr>
`WriteAttributes()`</td>Dodaje atrybut do otwartego węzła.</td></tr>
`WriteBase64()`</td>Dodaje tekst zakodowany algorytmem base64.</td></tr>
`WriteBinHex()`</td>Zapisuje dane w postaci heksadecymalnej.</td></tr>
`WriteCData()`</td>Zapisuje blok tekstu w postaci `...`.</td></tr>
`WriteChars()`</td>Zapisuje dane w formacie tekstowym.</td></tr>
`WriteComment()`</td>Dodaje komentarz w aktualnej pozycji.</td></tr>
`WriteDocType()`</td>Dodaje informacje DOCTYPE.</td></tr>
`WriteEndAttribute()`</td>Kończy wpisywanie atrybutu.</td></tr>
`WriteEndDocument()`</td>Zamyka otwarty dokument.</td></tr>
`WriteEndElement()`</td>Zamyka otwarty element.</td></tr>
`WriteStartAttribute()`</td>Otwiera nowy atrybut.</td></tr>
`WriteStartDocument()`</td>Dodaje deklarację dokumentu `<?xml ?>`.</td></tr>
`WriteStartElement()`</td>Tworzy nowy element.</td></tr>
`WriteWhitespace()`</td>Dodaje pustą przestrzeń.</td></tr>
</table>
Dodawanie prostych węzłów
Dodawanie prostych węzłów
Klasy XML są tak skonstruowane, że dodawanie prostych i krótkich węzłów i tak może zająć trochę czasu — ze względu na dużą liczbę wymaganych instrukcji. Inna sprawa, że samo wpisywanie nazw metody może trochę potrwać.
Spójrz na poniższy fragment prostego kodu XML:
<?xml version="1.0"?>
<pizze>
<pizza>Hawajska</pizza>
</pizze>
Sprawa jest prosta: węzeł główny pizze zawiera jeden element pizza. Do wygenerowania takiego tekstu jest wymagany następujący fragment kodu C#:
using System;
using System.Xml;
namespace XmlApp
{
class Program
{
static void Main(string[] args)
{
XmlTextWriter Writer = new XmlTextWriter("C:\\output.xml", null);
Writer.Formatting = Formatting.Indented;
Writer.Indentation = 4;
Writer.WriteStartDocument();
Writer.WriteStartElement("pizze");
Writer.WriteStartElement("pizza");
Writer.WriteString("Hawajska");
Writer.WriteEndElement();
Writer.WriteEndElement();
Writer.WriteEndDocument();
Writer.Close();
}
}
}
Jak widać, rezultat działania takiego kodu zgadza się z tym, co zostało wygenerowane: wcięcia w kodzie mają wielkość czterech spacji, a węzeł główny nosi nazwę pizze — zgodnie z tym, co zaprogramowaliśmy.
Dane, które mają znaleźć się w znaczniku pizza, są określone jako parametr metody WriteString().
Dynamiczne generowanie węzłów
Dynamiczne generowanie węzłów
Najczęściej stosowanym modelem jest dodawanie kolejnych węzłów, które wczytuje program — np. z bazy danych lub z tablicy. Tworzenie takich dynamicznych węzłów polega na połączeniu pętli z odpowiednimi instrukcjami XML. Spójrzmy na listing 13.7. W programie jest zadeklarowana dwuwymiarowa tablica PizzaArray, która zawiera informacje o nazwie pizzy oraz jej cenie. Program odczytuje liczbę elementów tablicy i na tej podstawie dodaje informacje do pliku.
Listing 13.7. Dynamiczne tworzenie węzłów
using System;
using System.Xml;
namespace XmlApp
{
class Program
{
static void Main(string[] args)
{
String[,] PizzaArray =
{
{ "Peperoni", "14,50" },
{ "Hawajska", "15,00" }
};
XmlTextWriter Writer = new XmlTextWriter("C:\\output.xml", null);
Writer.Formatting = Formatting.Indented;
Writer.Indentation = 4;
Writer.WriteStartDocument();
Writer.WriteStartElement("pizze");
for (int i = 0; i < PizzaArray.GetLength(1); i++)
{
Writer.WriteStartElement("pizza");
Writer.WriteStartElement("nazwa");
Writer.WriteString(PizzaArray[i, 0]);
Writer.WriteEndElement();
Writer.WriteStartElement("cena");
Writer.WriteString(PizzaArray[i, 1]);
Writer.WriteEndElement();
Writer.WriteEndElement();
}
Writer.WriteEndElement();
Writer.WriteEndDocument();
Writer.Close();
}
}
}
Efektem działania takiego kodu będzie utworzenie pliku o następującej budowie:
<?xml version="1.0"?>
<pizze>
<pizza>
<nazwa>Peperoni</nazwa>
<cena>14</cena>
</pizza>
<pizza>
<nazwa>Hawajska</nazwa>
<cena>15,50</cena>
</pizza>
</pizze>
Czyli wszystko zadziałało zgodnie z naszymi oczekiwaniami.
Dodawanie atrybutów
Dodawanie atrybutów
Zmodyfikujmy aplikację, tak aby wraz z elementem cena był dodawany atrybut o nazwie rozmiar. Oto zmodyfikowany fragment poprzedniego programu:
Writer.WriteStartElement("cena");
Writer.WriteAttributeString("rozmiar", "mała");
Writer.WriteString(PizzaArray[i, 1]);
Writer.WriteEndElement();
Writer.WriteEndElement();
Dzięki takiemu zabiegowi do węzła cena zostanie doklejony atrybut rozmiar o wartości mała:
<cena rozmiar="mała">15,50</cena>
Zarówno klasa XmlTextWriter, jak i XmlTextReader nie korzystają z modelu DOM. Zostały one zaprojektowane w taki sposób, aby dostarczać mechanizmy odczytu oraz zapisu przy jak najmniejszym nakładzie zasobów.
Dokumentacja XML
Dokumentacja XML
XML jest bardzo uniwersalnym formatem. Środowisko Visual C# Express Edition i język C# umożliwiają tworzenie komentarzy XML. Służą one do opisywania kodu, klas, metod, pól czy właściwości. Na podstawie takich komentarzy kompilator C# umożliwia wygenerowanie dokumentacji w formacie XML. Oto przykład użycia komentarzy XML:
/// <summary>
/// Klasa MyFoo (przykład)
/// </summary>
class MyFoo
{
/// <summary>
/// Pomocnicze pole
/// </summary>
static string MyBar;
/// <summary>
/// Przykładowa metoda Foo
/// </summary>
/// <param name="Bar">Ważny parametr</param>
static void Foo(string Bar)
{
}
/// <summary>
/// Właściwość Bar
/// </summary>
static string Bar
{
get
{
return MyBar;
}
}
}
Jak widzisz, element <code><summary></code> określa opis danego elementu, aczkolwiek możliwe jest również opisywanie parametrów metod (element <code><param></code>).
Tworzenie komentarzy XML w środowisku Visual C# Express Edition jest bardzo proste i przyjemne. Wystarczy nad danym elementem trzykrotnie wcisnąć przycisk /, aby środowisko wygenerowało całą „otoczkę” dla komentarza (czyli znaczniki XML).
Z menu Project wybierz pozycję Properties. Wybierz zakładkę Build i zaznacz pozycję XML documentation file. W polu tekstowym możesz określić ścieżkę, pod którą kompilator będzie zapisywał dokumentację XML. Kompilując w ten sposób projekt, spowodujemy utworzenie dokumentacji kodu, np.:
<?xml version="1.0"?>
<doc>
<assembly>
<name>FooApp</name>
</assembly>
<members>
<member name="T:FooApp.MyFoo">
<summary>
Klasa MyFoo (przykład)
</summary>
</member>
<member name="F:FooApp.MyFoo.MyBar">
<summary>
Pomocnicze pole
</summary>
</member>
<member name="M:FooApp.MyFoo.Foo(System.String)">
<summary>
Przykładowa metoda Foo
</summary>
<param name="Bar">Ważny parametr</param>
</member>
<member name="P:FooApp.MyFoo.Bar">
<summary>
Właściwość Bar
</summary>
</member>
</members>
</doc>
Pokazałem użycie zaledwie dwóch znaczników XML — <code><summary></code> oraz <code><param></code>. W rzeczywistości kompilator C# podczas tworzenia dokumentacji XML rozpoznaje o wiele więcej znaczników. Po więcej informacji na ten temat odsyłam do dokumentacji środowiska .NET Framework.
Podsumowanie
Podsumowanie
XML jest bez wątpienia technologią rewolucyjną. Jej dużą zaletą jest niezależność i możliwość łatwego przekształcenia dokumentów do innego formatu danych. Dzięki licznym parserom w dość prosty sposób można odczytać zawartość dokumentu XML, a nawet go zmodyfikować. Zresztą modyfikowanie pliku XML jest możliwe nawet za pomocą zwykłego edytora tekstu.
Rozdział ten stanowi jedynie wprowadzenie do technologii XML, jest to bowiem bardzo obszerny temat. Platforma .NET udostępnia ponadto wiele klas, o których tu nie wspominałem, a które także pomagają w tworzeniu i obróbce dokumentów XML. Jeżeli jesteś zainteresowany transformacją dokumentów XML do formatu HTML, powinieneś się zainteresować specyfikacją XSL.
[[C_Sharp/Wprowadzenie/Prawa autorskie|©]] Helion 2006. Autor: Adam Boduch. Zabrania się rozpowszechniania tego tekstu bez zgody autora.