Obliczanie sum kontrolnych SHA-1
mnbvcX
SHA-1 jest algorytmem stworzonym w 1995 roku ze względu na wykryte luki swojego poprzednika, SHA-0.
1. Algorytm
1.1. Używane funkcje
Algorytm SHA-1 używa jedynie: * dodawanie, * iloczyn bitowy (and, &) * sumę bitową (or, |) * działanie xor (^) * rotację bitową. Pierwsze cztery działania można zostawić bez komentarza. Warto jednak omówić rotację bitową. * W rotacji bitowej w prawo (w Assemblerze instrukcja ROR) ostatni bit po prawej przechodzi na lewą stronę, a wszystkie pozostałe bity przesuwają się o pozycję w prawo. * W rotacji bitowej w lewo (ROL) jest na odwrót: ostatni bit po lewej przechodzi na prawą stronę, a wszystkie pozostałe bity przesuwają się o pozycję w lewo. Czynność tę należy wykonać odpowiednią ilość razy.Rotację w prawo przedstawia rysunek:
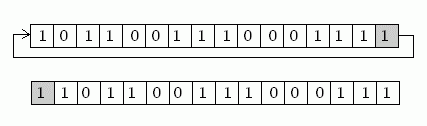
Nasza definicja rotacji w lewo przedstawia się następująco:
#define rol(x,n) ((x << n) | (x >> (32-n)))
1.2. Podział na bloki
Pierwszym etapem hashowania jest podział na bloki. Aby go wykonać, powinniśmy: 1. Zamienić wiadomość na postać binarną. 2. Na końcu wiadomości dodać bit o wartości 1. 3. Dopisać na końcu tyle zer, aby długość wiadomości modulo 512 wynosił 448. Przykładowo, jeżeli wiadomość (z bitem 1) ma długość 5001 bitów (wraz z bitem o wartości 1), powinniśmy wydłużyć ją do długości 5056 bitów (bo 5056 % 512 = 448). 4. Dopisać na końcu wiadomości 64-bitową liczbę oznaczającą długość pierwotnej wiadomości. 5. Podzielić ciąg na 512-bitowe bloki.Przykład działania:
1010100000000001101111111111110101001010100101010100101001010101111111101010101
0011111111010100101001010100010101010101001010101111101001101010101110101001100
1010101000000000001111111111101010100101001010100000010000000001111101010101111
1111111111111111010010101001010100111010010101010111110101011001000100000000000
0000000000000000000000000000000000000000000000000000000000000000000000000000000
0000000000000000000000000000000000000000000000000000000000000000000000000000000
00000000000000000000000000000100110000
Gdzie kolory to:
- Pierwotny ciąg
- Bit o wartości 1
- Wypełniacz
- Długość wiadomości
1.3. Główne działania
Potrzebne będą liczby 32-bitowe bez znaku: h0, h1, h2, h3, h4, a, b, c, d, e, tmp, f, k oraz tablica 80-elementowa w.Na początku inicjujemy 5 zmiennych - każda to część wyjścia. Inicjujemy je łączną wartością 0x0123456789ABCDEFFEDCBA9876543210F0E1D2C3:
h0 = 0x67452310;
h1 = 0xEFCDAB89;
h2 = 0x98BADCFE;
h3 = 0x10325476;
h4 = 0xC3D2E1F0;
Teraz wykonujemy działania dla każdego 512-bitowego bloku.
- Dzielimy blok na szesnaście 32-bitowych słów i zapisujemy je do w[0], w[1], ..., w[15].
- Rozszerzamy ilość słów z 16 do 80, wykonując działanie dla każdego 15 < i < 80:
w[i] = rol((w[i-3] ^ w[i-8] ^ w[i-14] ^ w[i-16]), 1);
- Tworzymy zmienne a, b, c, d, e o wartościach h0, h1, h2, h3, h4.
- Główna pętla (dla każdego 0 ≤ i ≤ 79):
- Jeżeli 0 ≤ i ≤ 19:
f = (b & c) | ((~b) & d);
k = 0x5A827999;
- Jeżeli 20 ≤ i ≤ 39:
f = b ^ c ^ d;
k = 0x6ED9EBA1;
- Jeżeli 40 ≤ i ≤ 59:
f = (b & c) | (b & d) | (c & d);
k = 0x8F1BBCDC;
- Jeżeli 60 ≤ i ≤ 79:
f = b ^ c ^ d;
k = 0xCA62C1D6;
- Następnie:
tmp = rol(a, 5) + e + f + k + w[i];
e = d;
d = c;
c = rol(b, 30);
b = a;
a = tmp;
- Zwiększamy wartość zmiennych h0..h4:
h0 += a;
h1 += b;
h2 += c;
h3 += d;
h4 += e;
Wynik to połączone ze sobą szesnastkowe przedstawienia zmiennych h0..h4.
Wartości 5A827999, 6ED9EBA1, 8F1BBCDC, CA62C1D6 to części całkowite z dla x = {2, 3, 5, 10}.
2. Implementacja w C/C++
Poniższa implementacja oblicza sumę kontrolną SHA-1 pliku. W pewnym stopniu oparty jest na stronie: http://www.hoozi.com/Articles/SHA1_Source.htm ./* natchnione stroną:
www.hoozi.com/Articles/SHA1_Source.htm */
#include <iostream>
#define rol(x,n) ((x << n) | (x >> (32-n)))
char SHA1_result[50];
void block(unsigned char* str, unsigned long &h0, unsigned long &h1, //obliczenia na każdym bloku
unsigned long &h2, unsigned long &h3, unsigned long &h4){
unsigned long w[80], a, b, c, d, e, k, f, tmp; //zmienne
for(int j = 0; j < 16; j++){
w[j] = str[j*4 + 0] * 0x1000000 //ustawianie szesnastu 32-bitowych słów
+ str[j*4 + 1] * 0x10000
+ str[j*4 + 2] * 0x100
+ str[j*4 + 3];
}
for(int j = 16; j < 80; j++){ //rozszerzanie szesnastu słów do osiemdziesięciu
w[j] = rol((w[j-3] ^ w[j-8] ^ w[j-14] ^ w[j-16]),1);
}
a = h0; //inicjalizacja a,b,c,d,e
b = h1;
c = h2;
d = h3;
e = h4;
for(int m=0;m<80;m++){ //działania...
if(m <= 19){
f = (b & c) | ((~b) & d);
k = 0x5A827999;
} else if(m <= 39){
f = b ^ c ^ d;
k = 0x6ED9EBA1;
} else if(m <= 59){
f = (b & c) | (b & d) | (c & d);
k = 0x8F1BBCDC;
} else {
f = b ^ c ^ d;
k = 0xCA62C1D6;
}
tmp = (rol(a,5) + f + e + k + w[m]) & 0xFFFFFFFF;
e = d;
d = c;
c = rol(b,30);
b = a;
a = tmp;
}
h0 = h0 + a; //przypis wartości h0..h4
h1 = h1 + b;
h2 = h2 + c;
h3 = h3 + d;
h4 = h4 + e;
}
void sha1file(char* filename){
//otwieramy plik
FILE *f;
f = fopen(filename, "rb");
if(f != NULL){
//tworzymy zmienne
char buffer[65];
unsigned long h0, h1, h2, h3, h4;
h0 = 0x67452301;
h1 = 0xEFCDAB89;
h2 = 0x98BADCFE;
h3 = 0x10325476;
h4 = 0xC3D2E1F0;
//uzyskujemy rozmiar pliku
fseek(f, 0, SEEK_END);
unsigned long filesize = ftell(f);
//wracamy na początek pliku
rewind(f);
//uzyskujemy liczbę 64-bajtowych (512-bitowych) bloków
long blocks = filesize / 64;
//uzyskujemy rozmiar ostatniego bloku
long lastblock = filesize % 64;
if(lastblock == 0){blocks--; lastblock = 64;}
//przetwarzamy wszystkie bloki oprócz ostatniego
for(int i = 0; i < blocks; i++){
fread(buffer, 1, 64, f); //czytamy 64 bajty
buffer[64] = '\0'; //dodajemy ostatni
block((unsigned char*)buffer, h0, h1, h2, h3, h4); //uaktualniamy zmienne
}
/* Teraz musimy dodać do ostatniego bufora bit o wartości 1, wypełniacz i
rozmiar badanego pliku.
Jeżeli ów bufor ma mniej niż 56 znaków, możemy spokojnie do niego dodać
bit o wartości 1, który z 7 bitami wypełniacza stworzy bajt o wartości 0x80.
Niestety, jeżeli bufor ma więcej lub równo 56 bajtów (ale mniej niż 64), bit "1"
zmieści się do bloku, ale długość pliku - już nie - będzie w kolejnym bloku.
Przy 64 bajtach nawet ów bit się nie zmieści i musimy go przenieść
do następnego bloku.*/
if(lastblock < 56){ //jeżeli ostatni blok ma mniej niż 64 elementy
for(int i = 0; i < 64; i++) buffer[i] = 0;
fread(buffer, 1, lastblock, f); //to go czytamy do końca
buffer[lastblock] = 0x80; //dodajemy bit o wartości 1 i siedem zer
} else { //inaczej
for(int i = 0; i < 64; i++) buffer[i] = 0;
fread(buffer, 1, lastblock, f); //czytamy go do końca
if(lastblock < 64) buffer[lastblock] = 0x80;
buffer[64] = '\0';
block((unsigned char*)buffer, h0, h1, h2, h3, h4); //uaktualniamy hx
for(int i = 0; i < 64; i++) buffer[i] = 0; //zerujemy blok
}
//dodajemy długość
if(lastblock == 64) buffer[0] = 0x80; //jeżeli ostatni blok był pełny, musimy bajt 1 zapisać do następnego
filesize *= 8; //potrzebna nam długość pliku w bitach, nie bajtach
/* Zapisujemy tylko 4 ostatnie znaki określające rozmiar; zakładamy, że
plik nie ma więcej niż 2^32-1 bitów (ok. 0,5GB). Jeśli mamy zamiar sprawdzić
większy plik (co jednak może trwać wieki :D), zmieniamy rozmiar zmiennej
filesize na unsigned long long i zmieniamy odpowiednio wiersze. */
buffer[60] = filesize / 0x1000000;
buffer[61] = filesize % 0x1000000 / 0x10000;
buffer[62] = filesize % 0x10000 / 0x100;
buffer[63] = filesize % 0x100;
buffer[64] = '\0';
block((unsigned char*)buffer, h0, h1, h2, h3, h4); //uaktualniamy hx
sprintf(SHA1_result, "%08x%08x%08x%08x%08x", h0, h1, h2, h3, h4); //tworzymy wynik
//zamykamy zmienne
fclose(f);
} else {
SHA1_result[0] = '-'; //jeśli wystąpił błąd, pierwszy znakiem jest kreska
}
//wynik jest w zmiennej globalnej SHA1_result
}
int main(){
char filename[256];
printf("Podaj nazwe pliku: ");
scanf("%s", filename); //wczytujemy nazwę pliku
printf("\n\nsha1(%s) = ", filename);
sha1file((char*)filename); //obliczamy sumę kontrolną SHA-1
if(SHA1_result[0] != '-'){ //jeżeli funkcja została ukończona poprawnie
printf("%s\n\n", SHA1_result); //wypisz wynik
} else {
printf("{Error: %s}\n\n", strerror(errno)); //inaczej wypisz błąd
}
return 0;
}
Ładny artykuł :)
Mógłbyś wytłumaczyć ten fragment?? Linie 88-99. :)
I dlaczego długość pliku zapisujesz na 4 bajtach(buffer[60..63]) zamiast na 8 bajtach jak w opisie słownym algorytmu??
Wynik na Wyjściu jest dobry, ale nie czaje tych momentów. ;)