Cześć!
Wracam do pythona po długiej przerwie, mam problem z bardzo prostym taskiem, więc sorry za poziom.
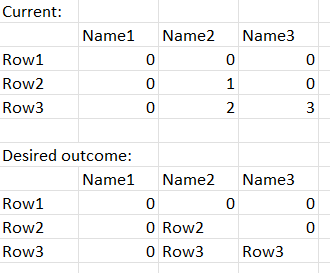
Mam matrycę, (115 rzędów i 531 kolumn). W rzędach mam wartości od 0 do 3ch.
Chciałbym zastąpić wszystkie wartości, które są wieksze od 0 nazwami rzędów (czyli z kolumny 0).
Rozbijam ten task na 3 czesci:
- Przeiteruj po zbiorze - for i in dataset:
- Znajdz wartosci wieksze niz 0 - if i>0
- przepisz nazwe rzedu - tu się potykam, będe wdzięczny za sugestie jak te nazwy rzedow zreplikowac. Próbowałem przypisać je do innej zmiennej i wkleić, ale wynik jest bez sensu
poczatek:
dataset=dataset[for i in dataset: if i>0, ]