Cześć,
mam problem ze zmianą formatu wczytanych danych. Po wczytaniu tabela z danymi wygląda następująco:
dane = pd.read_excel('2018_PM25_24g.xlsx', skiprows = 5)
dane.head()
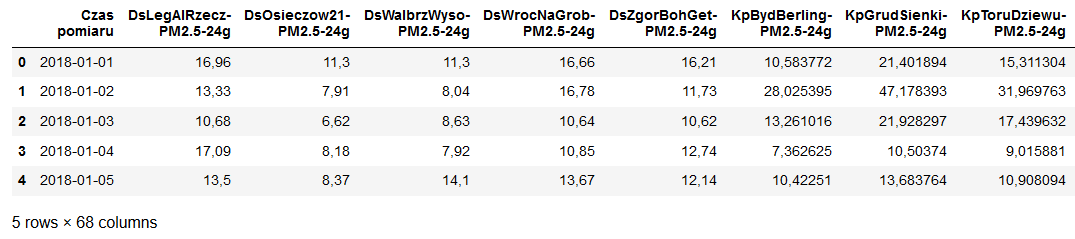
Widoczne wartości traktowane są jako object, jednak przy próbie analizy podstawowych statystyk widać, że poza zmienną zawierającą daty pozostałe są widoczne jako NAN
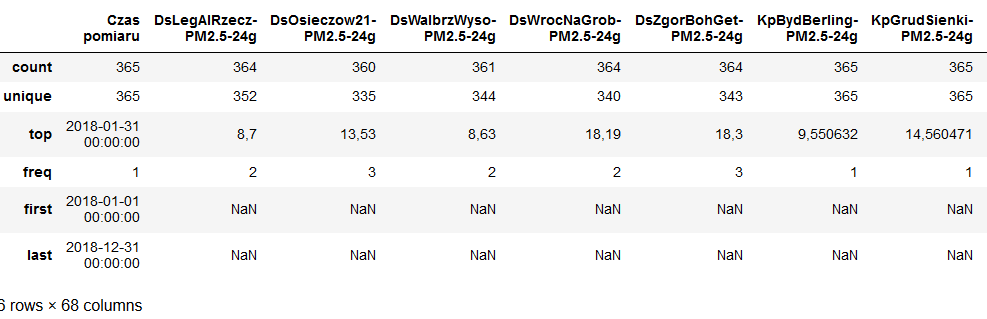
Wyodrębniłem dane dotyczące odczytów z dwóch stacji pomiarowych i spróbowałem je przekonwertować do typu zmiennoprzecinkowego
waw = dane[['Czas pomiaru', 'MzWarKondrat-PM2.5-24g', 'MzWarWokalna-PM2.5-24g']]
waw['MzWarKondrat-PM2.5-24g'].astype(float)
ale w rezultacie otrzymuję błąd:
ValueError: could not convert string to float: '28,13'
W pliku źródłowych z którego są importowane dane widać, że Excel także nie czyta danych jako wartości liczbowe. Czy możliwe jest, że w komórkach są jakieś niewidoczne znaki, które powodują problemy z prawidłowych odczytem?
Załączam plik źródłowy.