Oh boy, oh boy, oh boy...
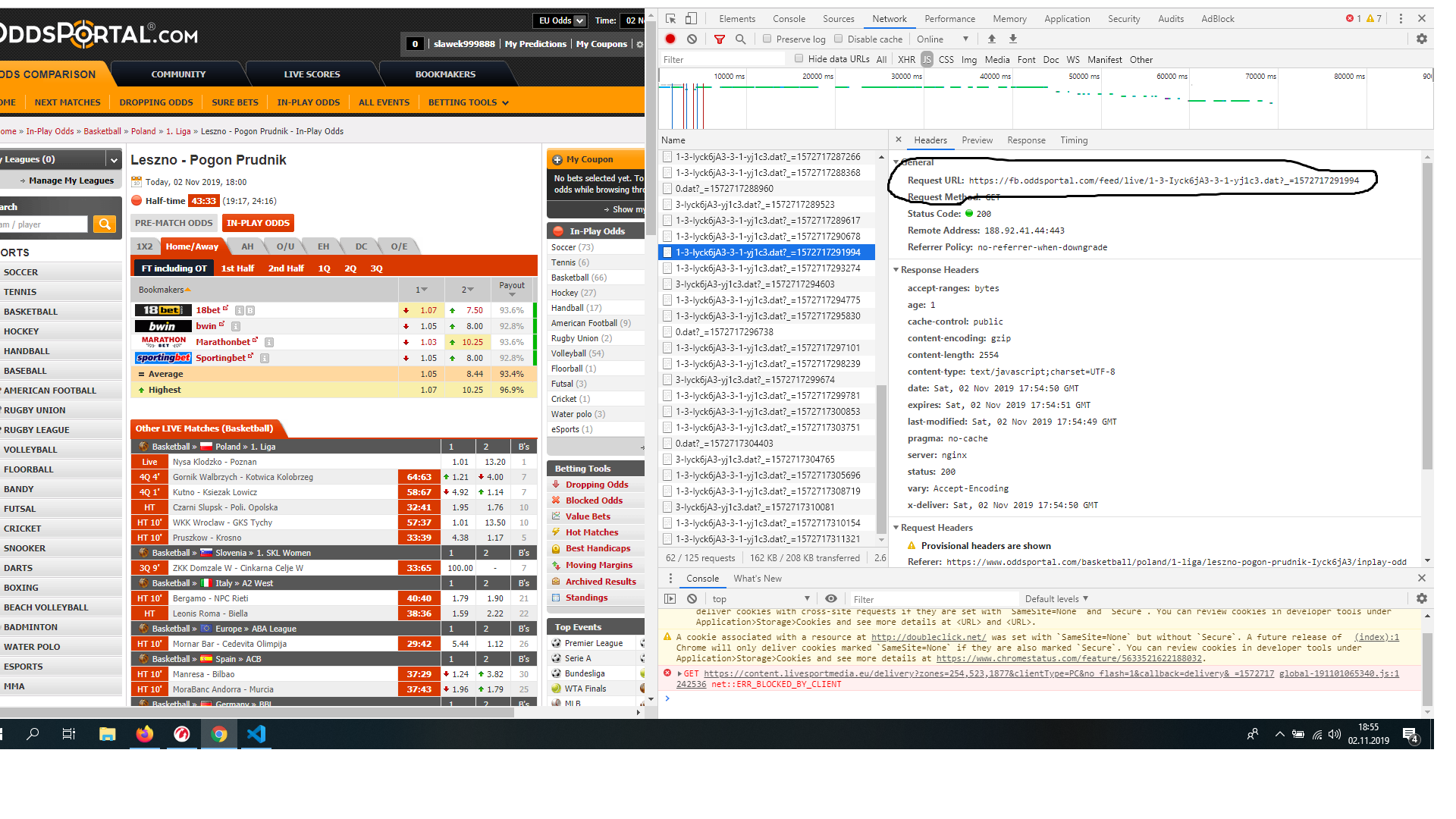
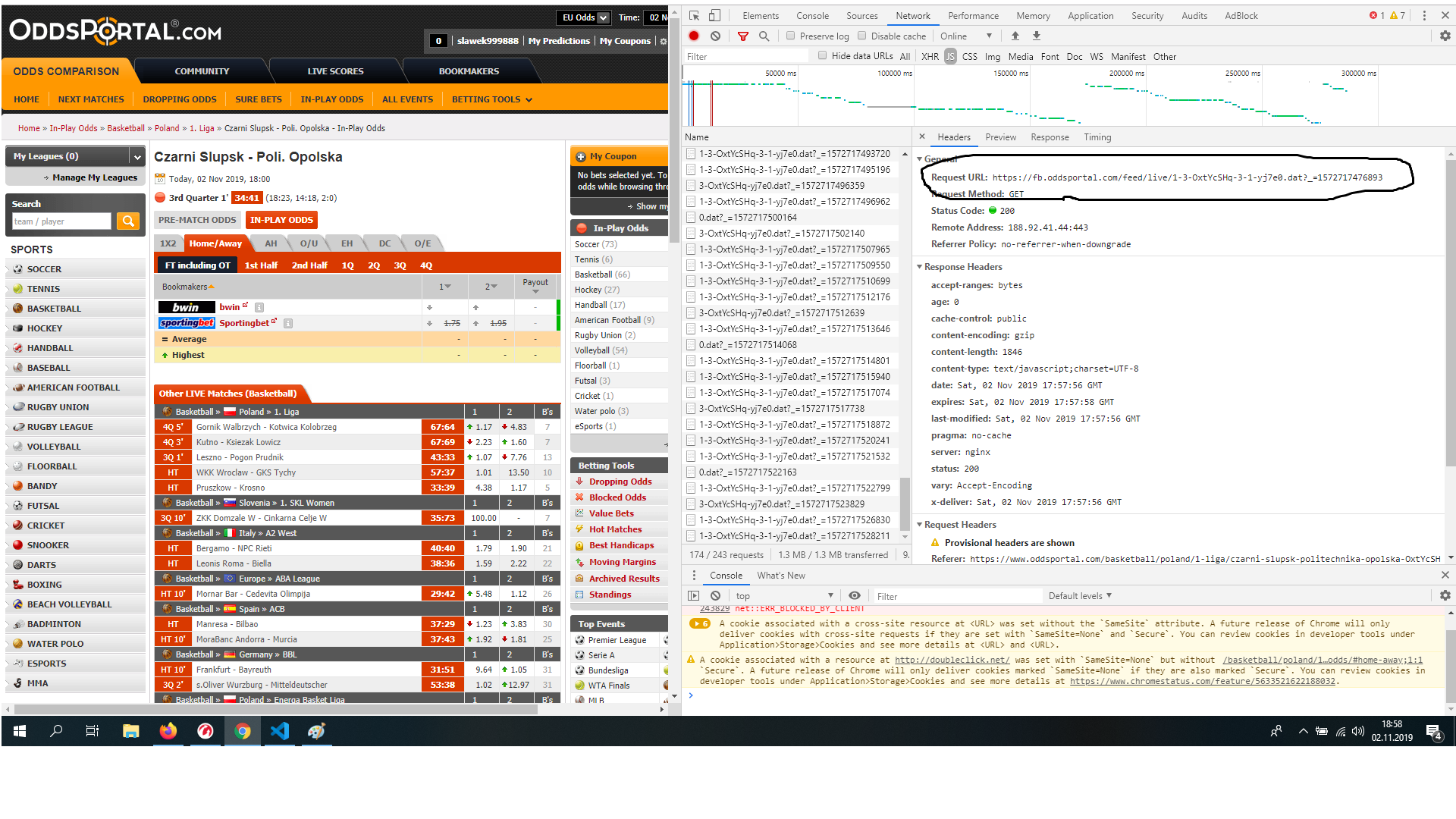
Wlazłem sobie na przykładowy url, https://www.oddsportal.com/basketball/greece/a1-women/panathinaikos-as-niki-lefkadas-dtXLVHkr/inplay-odds/, API pobiera mi się z requestów do https://fb.oddsportal.com/feed/live/1-3-dtXLVHkr-3-1-yj8b2.dat?_=1572790354807. Z tego co widzę, wszystkie takie requesty mają format
'https://fb.oddsportal.com/feed/live/1-3-ID1-3-1-ID2.dat
Więc trzeba znaleźć jakie jest ID1 oraz ID2. ID1 jest trywialne - możemy je pobrać z samego URL-a (dtXLVHk). Pytanie czym jest ID2. Szukam debuggerem - nie widzi nigdzie. Ściągam wszystkie requesty jako plik HAR (opcja w FF po wybraniu prawym klawiszem myszy) - też nigdzie nie ma. Trzeba zajrzeć do JavaScriptu Link można znaleźć w źrodle strony, idzie on tutaj - https://www.oddsportal.com/res/x/global-191101065340.js. Przepuszczamy to przez https://beautifier.io/ aby uzyskać sensowne formatowanie. Przeglądając JS w oczy wpada ten kawałek kodu
this.updateScore = function() {
if (page.updateScorePauseTime) {
return
}
var url = '/feed/postmatchscore/' + this.params.sportId + '-' + this.eventId + '-' + this.process(this.params.xhash) + '.dat';
var request = new Request(url);
var proxy = "2" * 1;
if (proxy) {
request.setProxyType(proxy)
}
request.setPriority(Request.PRIORITY_LOW);
request.setCallback(page.onUpdateScore);
request.get()
};
Zastnawia mnie ten parametr xhash, więc zaczynam go szukać. Szukając po tym identyfikatorze odkrywamy w źródłe strony taki kawałek
<script type="text/javascript">
//<![CDATA[
var op = new OpHandler();if(!page)var page = new PageEvent({"id":"29pLVtoG","xhash":"%79%6a%34%64%30","xhashf":"%79%6a%64%33%33","ukeyBase":"E-3849624","isLive":true,"isPostponed":false,"isStarted":true,"isFinished":false,"isFinishedGracePeriod":true,"sportId":3,"versionId":1,"home":"Hatay W","away":"Izmit Belediyespor W","tournamentId":43855,"eventBonus":[]});var menu_open = null;vJs();op.init();if(page && page.display)page.display(); var sigEndPage = true;
try
{
if (sigEndJs)
{
globals.onPageReady();
}
} catch (e)
{
}
//]]>
</script>
I tutaj leży nasz parametr xhash - %79%6a%34%64%30. Nie udało się znaleźć wcześniej bo jest encodowany. Można to zdekodować w Pythonie kodem urllib.unquote(url).decode('utf8') (uwaga, w Pythonie 3 funkcja jest inna). Dobra, mamy to (chyba). Jako bonus, widać, że w tym JSONie jest też nasz pierwszy identyfikator, więc nie trzeba go czytać z urla. Najpierw parsujemy naszą stronę do zupy:
url = 'https://www.oddsportal.com/basketball/turkey/kbsl-women/hatay-izmit-belediyespor-29pLVtoG/inplay-odds/'
headers = {
'User-Agent': 'curl/7.64.0',
'Referer': 'https://www.oddsportal.com/inplay-odds/live-now/basketball/',
}
page = requests.get(url, headers=headers)
soup = BeautifulSoup(page.text, 'html.parser')
Łapiemy skrypt
script = soup.select_one('script:contains("new OpHandler")').text
Wyciągamy regexem JSON i parsujemu
json_text = re.search('PageEvent\((.*?)\);', script)
if not json_text:
print('script not found')
sys.exit()
try:
json_data = json.loads(json_text.group(1))
except ValueError:
print('json not parsed')
sys.exit()
I teraz możemy odczytać oba identyfikatory
id1 = json_data.get('id')
id2 = urllib.unquote(json_data.get('xhash')).decode('utf8')
I skonstruować URL
output_url = 'https://fb.oddsportal.com/feed/live/1-3-{}-3-1-{}.dat?_={}'
print(output_url.format(id1, id2, int(time.time() * 1000)))
Całość
import json
import re
import sys
import time
import urllib
import requests
from bs4 import BeautifulSoup
url = 'https://www.oddsportal.com/basketball/turkey/kbsl-women/hatay-izmit-belediyespor-29pLVtoG/inplay-odds/'
headers = {
'User-Agent': 'curl/7.64.0',
'Referer': 'https://www.oddsportal.com/inplay-odds/live-now/basketball/',
}
page = requests.get(url, headers=headers)
soup = BeautifulSoup(page.text, 'html.parser')
script = soup.select_one('script:contains("new OpHandler")').text
json_text = re.search('PageEvent\((.*?)\);', script)
if not json_text:
print('script not found')
sys.exit()
try:
json_data = json.loads(json_text.group(1))
except ValueError:
print('json not parsed')
sys.exit()
id1 = json_data.get('id')
id2 = urllib.unquote(json_data.get('xhash')).decode('utf8')
output_url = 'https://fb.oddsportal.com/feed/live/1-3-{}-3-1-{}.dat?_={}'
print(output_url.format(id1, id2, int(time.time() * 1000))
Uf.
Z grubsza biorąc tak właśnie wygląda web scrapping - ładujemy się na stronę i pół biedy jak to prosty HTML, który można odczytać od razu. Trzeba często jednak bawić się w detektywa, czytać requesty, analizować skrypty, wygrzebywać z kodu kody sesji, identyfikatory, klucze, ustawiać ciastka, wysyłać zapytania do API i tym podobne. Wybrałeś sobie bardzo kiepską stronę na naukę web scrapingu, bo większość rzeczy jest tu pohowana w różnych śmiesznych miejscach i trzeba się było głęboko wgryźć w bebechy i fantazję devów, którzy to coś składali do kupy żeby odtworzyć wszystkie akcje i zapytania.
Z mojej strony pass, więcej już się tą stroną bawić nie będę, więc jak jeszcze będziesz miał jakieś problemy, to musisz je zbadać sam. Pokazałem ci z grubsza jak to się robi.