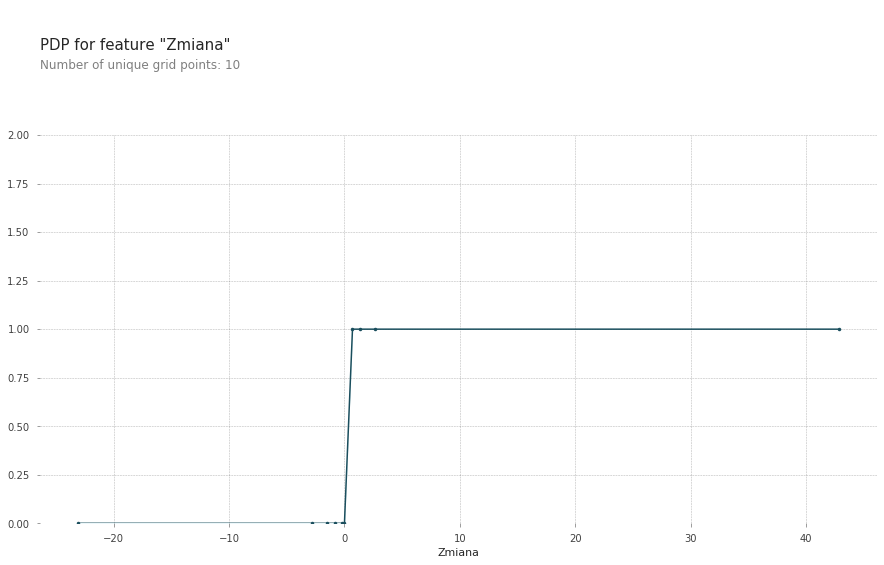
Kod był niekompletny, brakowało rozbicia danych, które wkleiłeś w poprzednim poście jako ostatni listing. Następnym razem formułuj problem precyzyjniej, będzie Ci łatwiej pomóc.
Przechodząc do sedna, znalazłem błąd po wklejeniu do 5. komórki listingu, który usunąłeś:
from sklearn.preprocessing import StandardScaler
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.20, random_state = 0) # Tego nie było!
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.transform(X_test)
W ostatniej linii nadpisujesz zmienną X_test, której używasz w 9. komórce jako parametr dataset.
pdp_dist = pdp.pdp_isolate(model=classifier, dataset=pd.DataFrame(X_test), model_features=feature, feature= feat_name)
Żeby to naprawić, wystarczy zrobić tak:
from sklearn.preprocessing import StandardScaler
X_train, X_test_org, y_train, y_test = train_test_split(X, y, test_size = 0.20, random_state = 0) # Tego nie było!
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.transform(X_test_org)
pdp_dist = pdp.pdp_isolate(model=classifier, dataset=X_test_org, model_features=feature, feature= feat_name)